ELK介绍
ELK由Elasticsearch、Logstash和Kibana三部分组件组成。
- Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
- Logstash是一个完全开源的工具,它可以对你的日志进行收集、分析,并将其存储供以后使用。
- kibana 是一个开源和免费的工具,它可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
Elasticsearch
Elasticsearch是一个基于Lucene实现的开源、分布式、Restful的全文本搜索引擎。(仅支持文本搜索)此外,它还是一个分布式实时文档存储,其中每个文档的每个field均是被索引的数据,且可被搜索;也是一个带实时分析功能的分布式搜索引擎,能够扩展至数以百计的节点实时处理PB级的数据。
Elasticsearch借助于Lucene的API,在Lucene之外又重新封装了一层实现构建搜索引擎中的搜索组件。除此之外,Elasticsearch还新增了更强大的功能。比如把自己构建为分布式,分布式地将Lucene所提供的索引组建成shard形式,分布于多个节点之上,从而构建成分布式实时查询的组件。
Logstash
支持多数据获取机制,通过TCP/UDP协议、文件、syslog、windows EventLogs及STDIN等。获取到数据后,它支持对数据执行过滤、修改等操作。
logstash配置框架:
input {
...
}
filter {
...
}
output {
...
}
Logstash是高度插件化的,支持4种类型的插件(每一类都有数10种具体的实现):
input、filter、codec、output
input插件
下面介绍input插件几种常见的实现。
1.File:
从指定的文件中读取事件流;其工作特性类似于tail -1,不断将文件的最后一行读出来;不过第一次读取文件时是从第1行开始的;文件中的每一行都被识别为一个事件。对于Logstash而言,每一个独立的信息就是一个事件,而对于文本文件来讲,每一个事件是用一行来表示的,如果期望将多行识别为一个事件的话,就需要codec插件。logstash使用FileWatch(Ruby Gem库)机制来监听文件的变化,FileWatch是Linux内核中提供的一个功能。可以一下子监听多个文件。文件状态记录在.sincedb数据库中。另外,FIle插件还能够自动识别你的日志滚动操作,日志一般达到某个体积、或者满足多少天后会滚动,File也能识别。它会按照上一次那个日志文件所在的位置读取,自动进行滚动,读到最新的文件。
2.udp插件:
如果我们安装的某个程序,它能够通过udp的某个端口输出自己相关日志信息或者事件。Logstash通过udp协议从网络连接来读取Message。其必备参数为port,用于指明自己监听的端口,别的主机向这个端口发事件,host则用来指明自己监听的地址。
3.redis插件:
允许Logstash从redis读数据。支持redis channel和lists两种方式来获取数据。
filter插件
filter插件主要用于将event通过output发出之前,对其实现某些处理功能。
1.grok:用于分析并结构化文本数据。把每一个事件字段切好,做成结构化的形式。使得我们后续可以分析。目前能处理syslog、apache、nginx的日志等。目前Logstash提供120种grok模式,因为我们要分析文本,必须提供模式。
简单举个例子说明下什么是模式:
55.3.244.1 GET /index.html 15824 0.043
比如对于上面一条日志,我们定义如下的模式:
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
那么经过grok过滤后,这个事件后将会加有分析后的字段:
client => 55.3.244.1
method => GET
request => /index.html
bytes => 15824
duration => 0.043
Logstash中默认自带了很多pattern,但是如果没有你需要的,就需要自己在文件中定义你需要的模式。
grok语法格式:
%{SYNTAX:SEMANTIC}
SYNTAX表示预定义模式名称。就是Logstash解压后pattern相关文件里已经定义好的模式,如果没有的,可以自己写在上面那个文件里,名字得全大写。具体的文件在下面的实战中会讲到。
SEMANTIC表示匹配到的文本的自定义的标识符。比如识别处理的ip可能是clientip也可能是server端的ip,我们可以自定义名字。
output插件
1.stdout:标准输出插件。
2.elasticsearch:将结果输出到Elasticsearch中。
elasticsearch插件常见配置参数:
- index:数据存储在ES中的哪个索引中。默认“logstash-%{+YYYY.MM.dd}”,每天使用一个单独的索引。
- workers:执行output的线程数。
3.redis插件:将结果输出到redis中。
Logstash使用redis作为输入或输出插件时,尤其是输出插件时,它有两种数据类型可以用来保存Logstash输出的数据。一种是list,一种是channel。一般使用list,list比较简单。
【注意】:Logstash版本不同,每种插件支持的参数也不同,具体看官方文档。
环境信息
| 主机名 | 操作系统版本 | IP地址 | 安装软件 |
|---|---|---|---|
| hadoop16 | CentOS 7.0 | 172.16.206.16 | elasticsearch-5.6.3.zip、kibana-5.6.3-linux-x86_64.tar.gz |
| spark32 | CentOS 7.0 | 172.16.206.32 | logstash-5.6.3.tar.gz |
Elasticsearch
安装JDK8
# tar zxf jdk-8u73-linux-x64.gz -C /usr/java/
# vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_73
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# source /etc/profile
新建用户
【注意】:elasticsearch不能使用root用户去启动。
# groupadd -g 510 es
# useradd -g 510 -u 510 es
# echo "wisedu123" | passwd --stdin es &> /dev/null
安装配置Elasticsearch
[root@hadoop16 opt]# unzip -oq elasticsearch-5.6.3.zip
[root@hadoop16 opt]# vim elasticsearch-5.6.3/config/elasticsearch.yml
cluster.name: loges
node.name: hadoop16
network.host: 172.16.206.16
bootstrap.memory_lock: true
[root@hadoop16 opt]# vim /etc/security/limits.conf
es - memlock -1
[root@hadoop16 opt]# chown -R es.es elasticsearch-5.6.3
配置说明:
bootstrap.memory_lock: true
这个配置的作用是保护Elasticsearch使用的内存防止其被swapped。
优化Elasticsearch
1.配置操作系统文件描述符数
输入下面的命令进行查看:
$ ulimit -a
找到open files那行:
open files (-n) 1024
设置需要修改:
# vim /etc/security/limits.conf
es - nofile 65536
2.增大虚拟内存mmap count配置
备注:如果你以.deb或.rpm包安装,则默认不需要设置此项,因为已经被自动设置,查看方式为:
sysctl vm.max_map_count
如果是手动安装,以root身份执行如下命令:
sysctl vm.max_map_count=262144
并修改文件使设置永久生效:
# vim /etc/sysctl.conf
加一行:vm.max_map_count = 262144
# sysctl -p
改完后,重启elasticsearch。
如果需要需改JVM大小,请修改 jvm.options 配置文件。
启动Elasticsearch
[root@hadoop16 opt]# su - es
[es@hadoop16 ~]$ /opt/elasticsearch-5.6.3/bin/elasticsearch -d
检验bootstrap.mlockall: true是否生效:
curl http://172.16.206.16:9200/_nodes/process?pretty
关注这个这个请求返回数据中的mlockall的值,如果为false,则说明锁定内存失败,这可能由于运行elasticsearch的用户不具备这样的权限。解决该问题的方法是:
在运行elasticsearch之前,以root身份执行
ulimit -l unlimited
然后再次重启elasticsearch。并查看上面的请求中的mlockall的值是否为true。
【注意】:这时候需要在root执行ulimit -l unlimited的shell终端上su - es,然后重启elasticsearch。因为这是命令行设置的ulimit -l unlimited,只对当前会话生效。
# ulimit -l unlimited
# su - es
$ ps -ef|grep elasticsearch
$ kill -9 27189
$ /usr/local/elasticsearch/bin/elasticsearch -d
$ curl http://172.16.206.16:9200/_nodes/process?pretty
要想永久修改锁定内存大小无限制,需修改/etc/security/limits.conf,添加下面的内容,改完不需要重启系统,但是需要重新打开一个shell建立会话。
es - memlock -1
其中,es代表运行elasticsearch的用户,-表示同时设置了soft和hard,memlock代表设置的是”锁定内存”这个类型,-1(unlimited或者infinity)代表没限制。
【补充】: 要使 /etc/security/limits.conf 文件配置生效,必须要确保 pam_limits.so 文件被加入到相关的启动文件中,启动文件位于/etc/pam.d路径下,如该路径下sshd、login、system-auth等,一般是system-auth文件负责加载该so文件。只要加载了pam_limits.so,则配置就会生效,无需重启系统。
安装配置head插件
项目地址:https://github.com/mobz/elasticsearch-head
安装head插件
[root@hadoop16 opt]# git clone git://github.com/mobz/elasticsearch-head.git
[root@hadoop16 opt]# yum -y install epel-release
[root@hadoop16 opt]# yum install nodejs -y
[root@hadoop16 opt]# cd elasticsearch-head/
[root@hadoop16 elasticsearch-head]# npm install
npm: relocation error: npm: symbol SSL_set_cert_cb, version libssl.so.10 not defined in file libssl.so.10 with link time reference
[root@hadoop16 elasticsearch-head]# yum update openssl -y
[root@hadoop16 elasticsearch-head]# npm install
# 如果下载速度太慢,可以如下方式安装
[root@hadoop16 elasticsearch-head]# npm install -gd express --registry=http://registry.npm.taobao.org
# 为了避免每次安装都需要--registry参数,可以使用如下命令进行永久设置:
[root@hadoop16 elasticsearch-head]# npm config set registry http://registry.npm.taobao.org
[root@hadoop16 elasticsearch-head]# npm install grunt --save-dev
[root@hadoop16 elasticsearch-head]# npm install grunt-contrib-clean
[root@hadoop16 elasticsearch-head]# npm install grunt-contrib-concat
[root@hadoop16 elasticsearch-head]# npm install grunt-contrib-watch
[root@hadoop16 elasticsearch-head]# npm install grunt-contrib-connect
[root@hadoop16 elasticsearch-head]# npm install grunt-contrib-copy
[root@hadoop16 elasticsearch-head]# npm install grunt-contrib-jasmine
奇怪的是最后一个没有安装成功,是因为该模块依赖了phantomjs。但是配置之后,依然无法安装。直接启动就可以了:
[root@hadoop16 elasticsearch-head]# grunt server
以上安装head插件的步骤太过复杂,我们可以将下载下来的elasticsearch-head包放入tomcat中,直接启动tomcat就可以访问head插件了。本实验环境下是采用将head插件放入tomcat中运行。
配置
1.修改Elasticsearch的配置文件elasticsearch.yml,增加跨域的配置(需要重启es才能生效)
http.cors.enabled: true
http.cors.allow-origin: "*"
2.编辑head/Gruntfile.js,修改服务器监听地址,增加hostname属性,将其值设置为*。
[root@hadoop16 elasticsearch-head]# pwd
/opt/apache-tomcat-8.5.23/webapps/elasticsearch-head
[root@hadoop16 elasticsearch-head]# vim Gruntfile.js
以下两种配置都是可以的:
# Type1
connect: {
hostname: '*',
server: {
options: {
port: 9100,
base: '.',
keepalive: true
}
}
}
# Type 2
connect: {
server: {
options: {
hostname: '*',
port: 9100,
base: '.',
keepalive: true
}
}
}
3.编辑head/_site/app.js,修改head连接es的地址,将localhost修改为es的IP地址
[root@hadoop16 elasticsearch-head]# pwd
/opt/apache-tomcat-8.5.23/webapps/elasticsearch-head
[root@hadoop16 elasticsearch-head]# vim _site/app.js
# 原配置
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://localhost:9200";
# 将localhost修改为ES的IP地址
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://YOUR-ES-IP:9200";
启动
[root@hadoop16 elasticsearch-head]# cd /opt/apache-tomcat-8.5.23/
[root@hadoop16 apache-tomcat-8.5.23]# bin/startup.sh
Logstash
安装JDK8
Logstash是jruby研发的,需要跑在JVM上,所以需要安装JDK。
# tar zxf jdk-8u73-linux-x64.gz -C /usr/java/
# vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_73
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# source /etc/profile
安装配置Logstash
我这里选择二进制包安装。
[root@spark32 opt]# tar zxf logstash-5.6.3.tar.gz
[root@spark32 opt]# cd logstash-5.6.3/
由于我这里选择是二进制安装,pattern文件位置在:
[root@spark32 logstash-5.6.3]# ls /opt/logstash-5.6.3/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.1.2/patterns/grok-patterns
收集Nginx access日志
Logstash收集Nginx日志,输出到Elasticsearch中。
创建Nginx pattern
[root@spark32 ~]# vim /opt/logstash-5.6.3/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.1.2/patterns/grok-patterns
# Nginx log
NGUSERNAME [a-zA-Z\.\@\-\+_%]+
NGUSER %{NGUSERNAME}
NGINXACCESS %{IPORHOST:clientip} - %{NOTSPACE:remote_user} \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:agent} %{NOTSPACE:http_x_forwarded_for}
创建Logstash配置文件
[root@spark32 logstash-5.6.3]# cd /opt/logstash-5.6.3
[root@spark32 logstash-5.6.3]# mkdir conf
[root@spark32 logstash-5.6.3]# cd conf
[root@spark32 conf]# vim logstash_nginx.conf
input {
file {
path => ["/usr/local/openresty/nginx/logs/host.access.log"]
type => "nginxlog"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{NGINXACCESS}" }
}
}
output {
elasticsearch {
hosts => ["172.16.206.16:9200"]
action => "index"
index => "logstash-%{+YYYY.MM.dd}"
}
}
启动Logstash
[root@spark32 logstash-5.6.3]# bin/logstash -f /opt/logstash-5.6.3/conf/logstash_nginx.conf -t
Sending Logstash's logs to /opt/logstash-5.6.3/logs which is now configured via log4j2.properties
[2017-10-20T17:07:14,793][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/opt/logstash-5.6.3/modules/fb_apache/configuration"}
[2017-10-20T17:07:14,797][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/opt/logstash-5.6.3/modules/netflow/configuration"}
[2017-10-20T17:07:14,803][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.queue", :path=>"/opt/logstash-5.6.3/data/queue"}
[2017-10-20T17:07:14,804][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.dead_letter_queue", :path=>"/opt/logstash-5.6.3/data/dead_letter_queue"}
Configuration OK
[2017-10-20T17:07:14,999][INFO ][logstash.runner ] Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash
[root@spark32 logstash-5.6.3]# bin/logstash -f /opt/logstash-5.6.3/conf/logstash_nginx.conf &
记录收集到日志的文件位置在:
[root@spark32 file]# ls -a
. .. .sincedb_650663ba19529187a32a8b9dc99049f8
[root@spark32 file]# pwd
/opt/logstash-5.6.3/data/plugins/inputs/file
查看Elasticsearch索引:
[es@hadoop16 elasticsearch-5.6.3]$ curl -XGET '172.16.206.16:9200/_cat/indices'
yellow open logstash-2017.10.20 DVARGYZ2R9CfT-xyLrhyAQ 5 1 7 0 49.9kb 49.9kb
Kibana
安装配置kibana
[root@hadoop16 opt]# tar zxf kibana-5.6.3-linux-x86_64.tar.gz
[root@hadoop16 opt]# ln -sv kibana-5.6.3-linux-x86_64 kibana
‘kibana’ -> ‘kibana-5.6.3-linux-x86_64’
[root@hadoop16 opt]# cd kibana
[root@hadoop16 kibana]# cd config/
[root@hadoop16 config]# vim kibana.yml
server.host: "172.16.206.16"
elasticsearch.url: "http://172.16.206.16:9200"
[root@hadoop16 config]# cd ..
[root@hadoop16 kibana]# bin/kibana &
访问
浏览器输入:http://172.16.206.16:5601/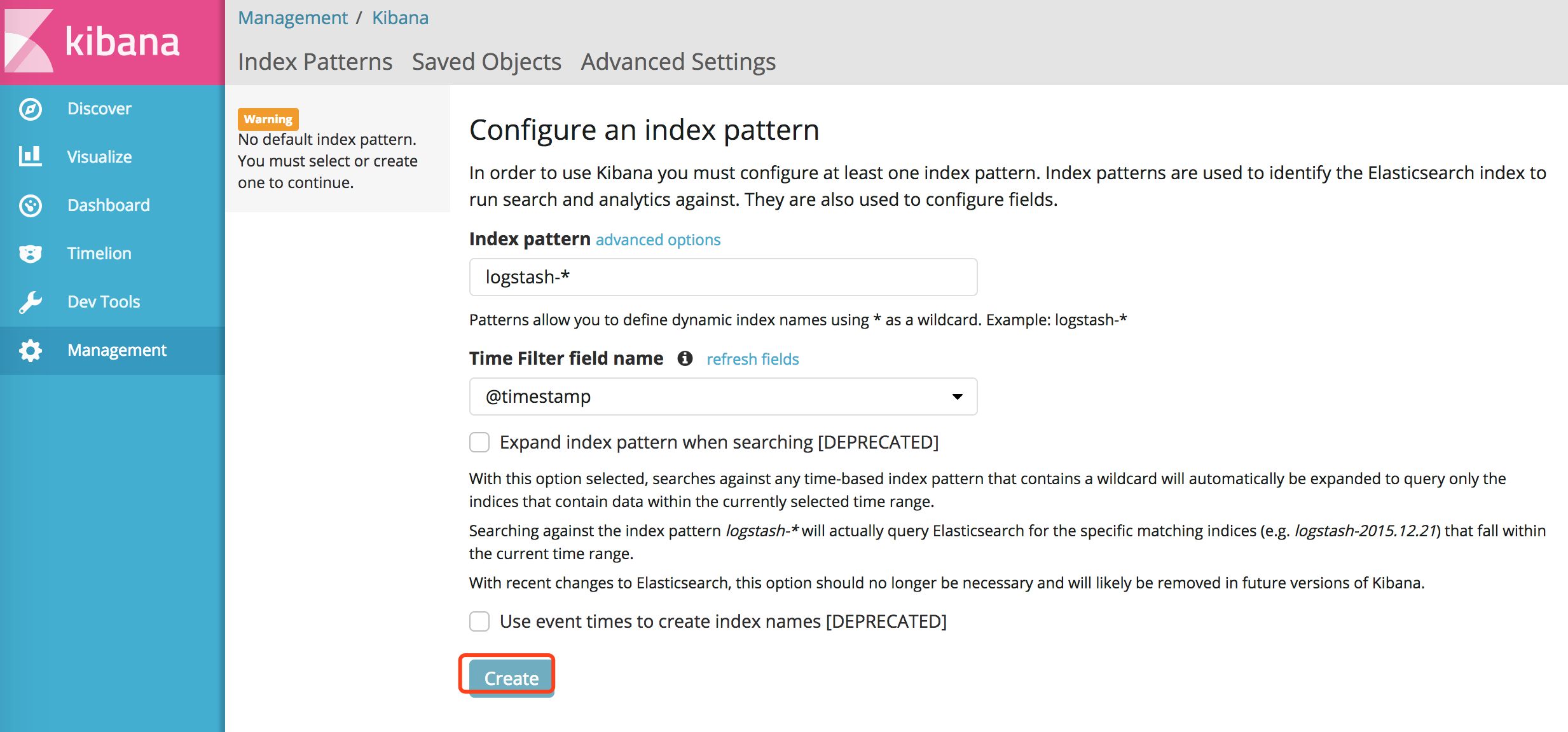
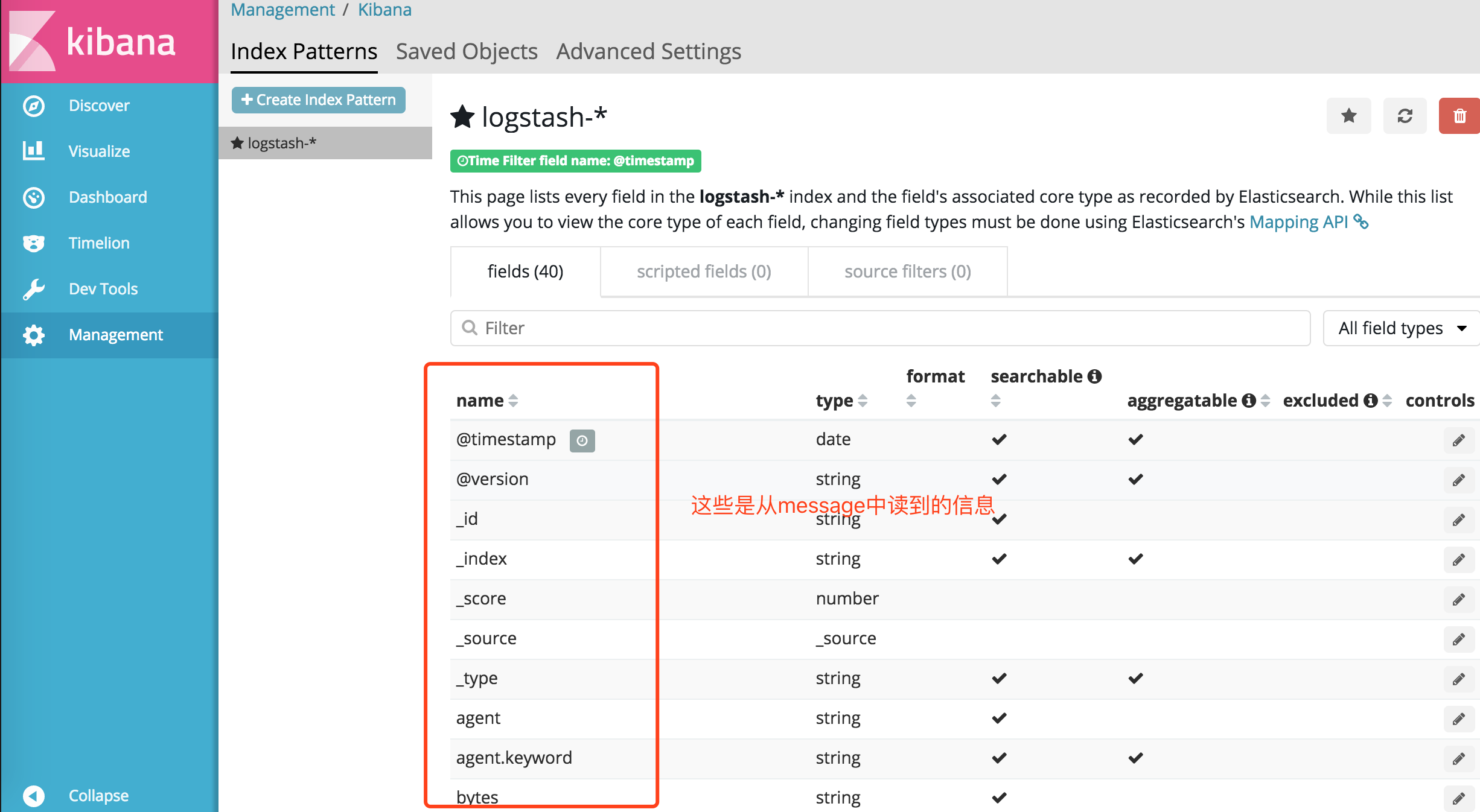
点击左侧菜单的Discover: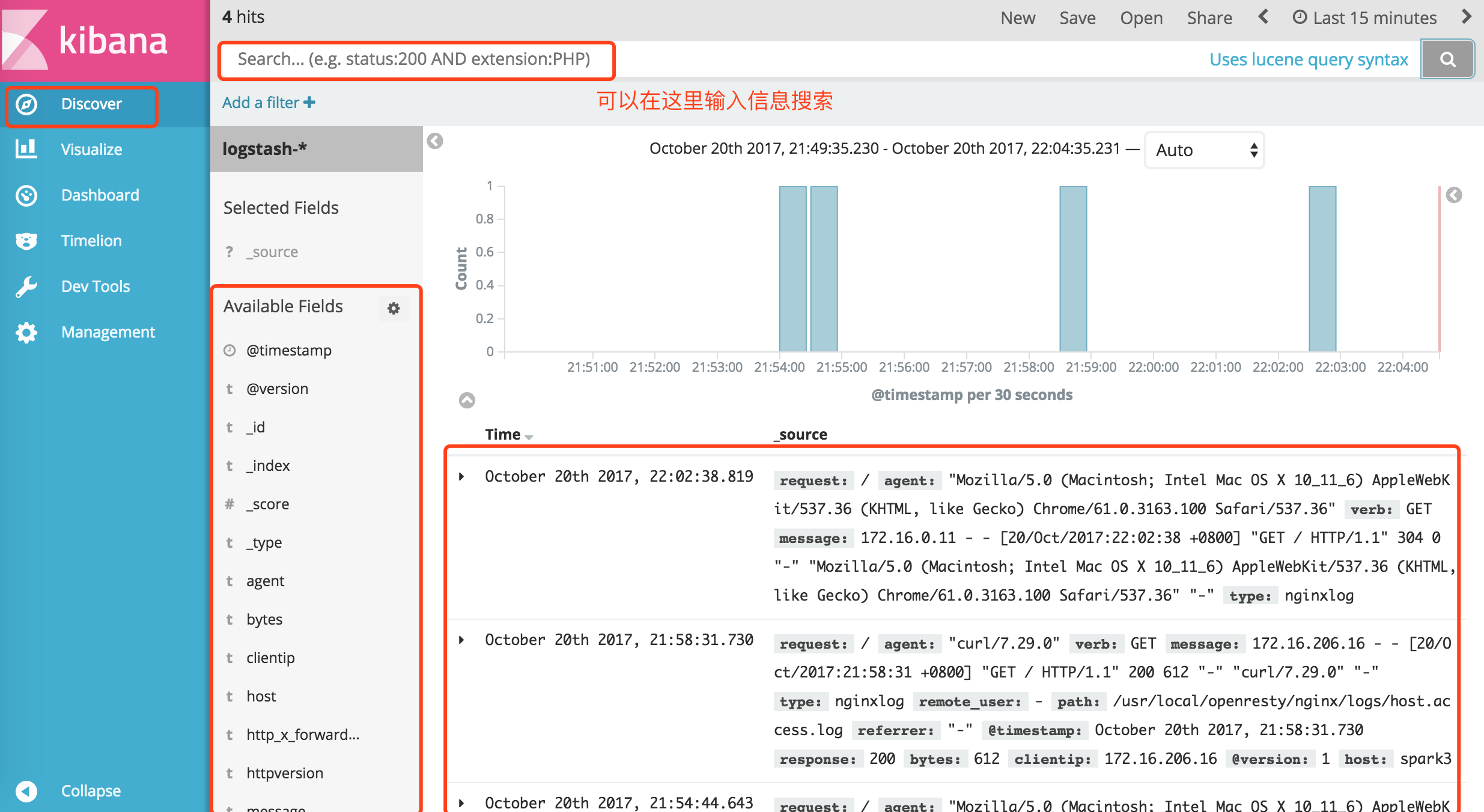
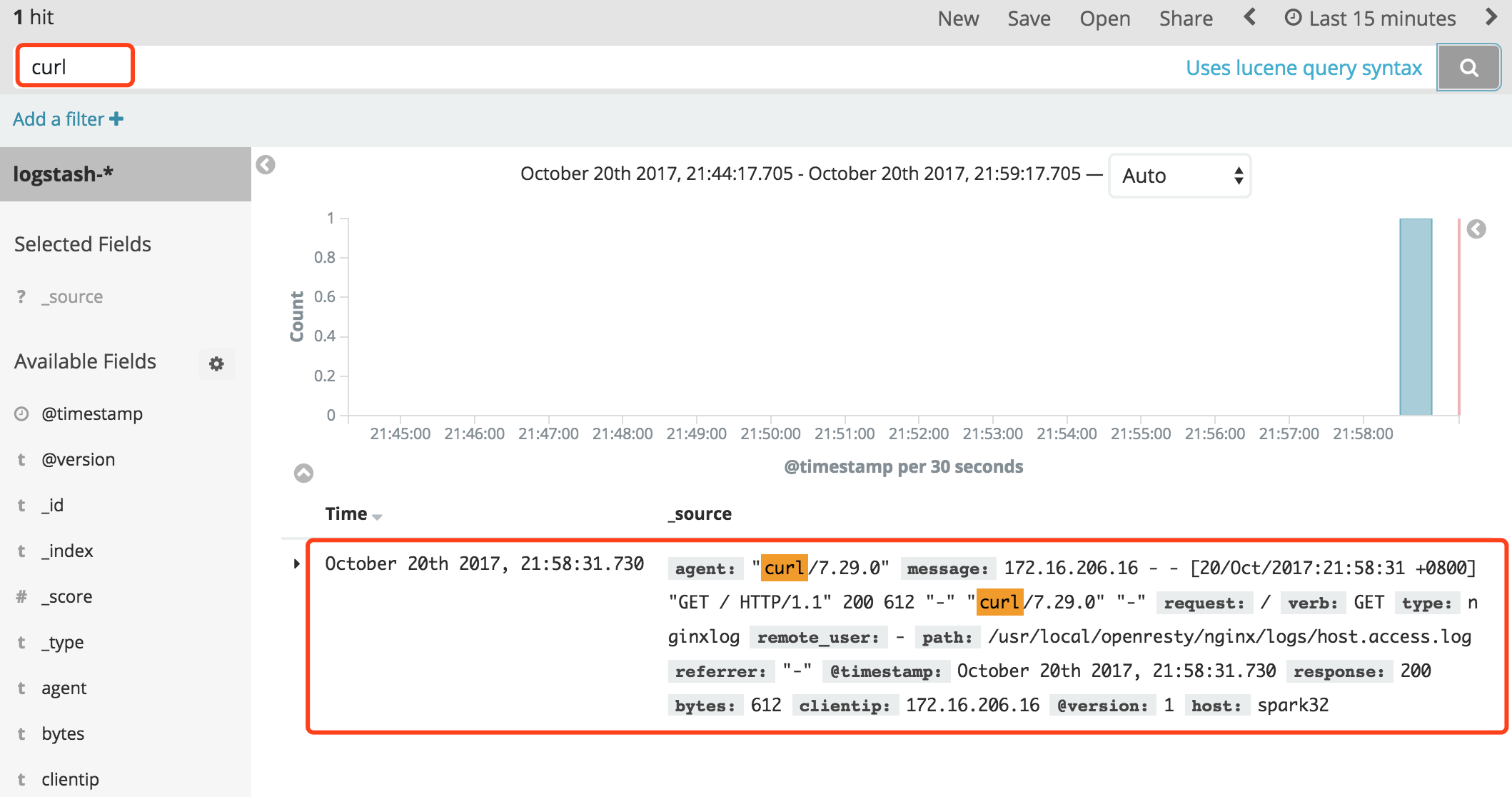
比如我用curl访问下nginx,然后去kibana中搜索。要稍微等一下,等日志进到Elasticsearch中。
[root@hadoop16 kibana]# curl http://172.16.206.32:808
总结:
1.Logstash 主要的特点就是它的灵活性,因为它有很多插件。然后它清楚的文档已经直白的配置格式让它可以再多种场景下应用。这样的良性循环让我们可以在网上找到很多资源,几乎可以处理任何问题。
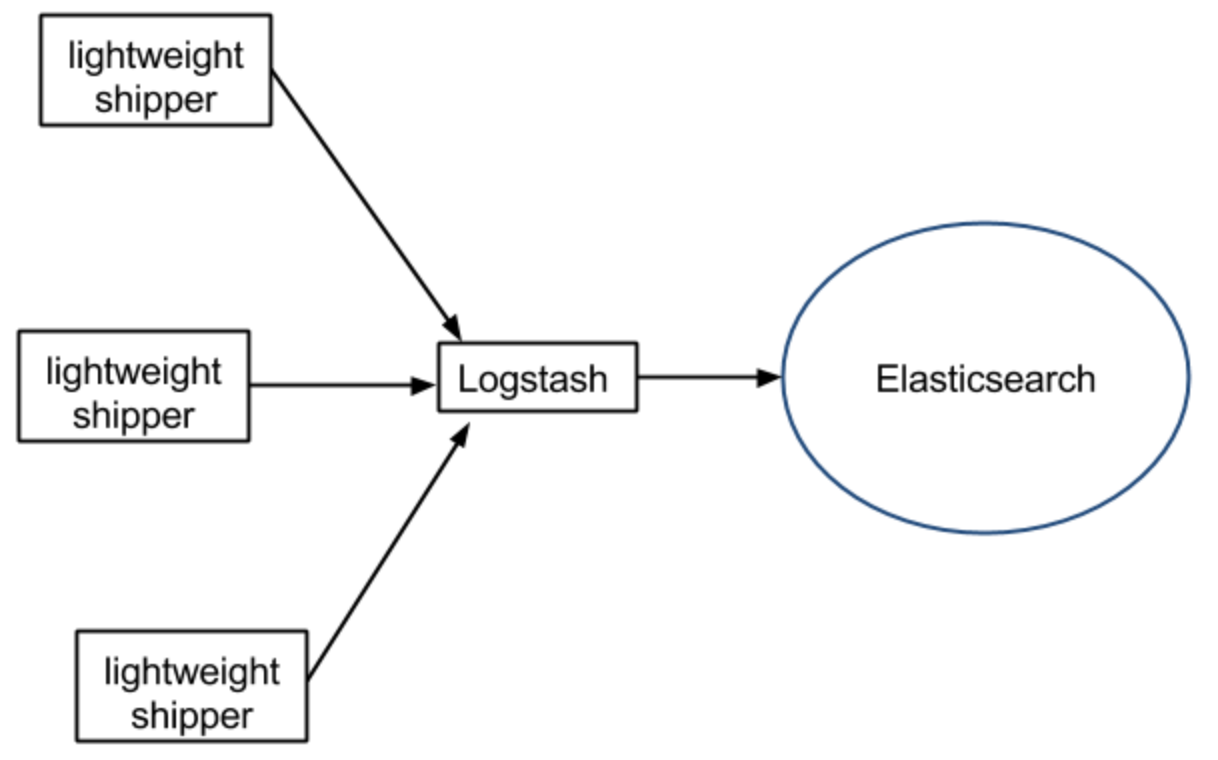
2.Logstash不支持缓存,当然我们可以使用redis或者kafka作为中心缓冲池,架构如下: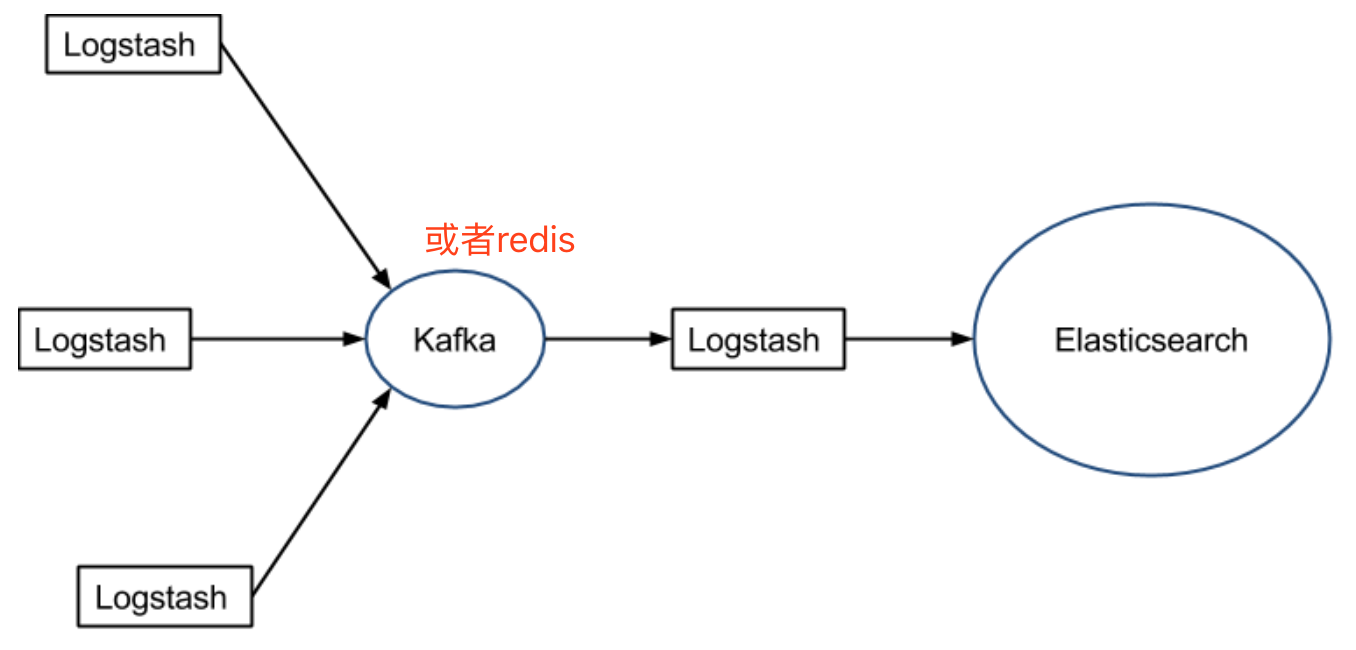
3.Logstash是在jvm跑的,资源消耗比较大,太重量级了。后来作者又用golang写了一个功能较少但是资源消耗也小的轻量级的logstash-forwarder。后来这个人加入了elastic公司。因为elastic公司本身还收购了另一个开源项目packetbeat,而这个项目专门就是用golang写的,有整个团队,所以elastic公司干脆把logstash-forwarder的开发工作也合并到同一个golang团队来搞,于是新的项目就叫filebeat了。当然也可以自己写agent,用go、python都可以写。这样我们就可以使用轻量的日志传输工具,将数据从服务器端经由一个或多个 Logstash 中心服务器传输到 Elasticsearch。