
之前采用二进制方式部署过Kubernetes,操作较为繁琐,此次采用kubeadm安装Kubernetes,Kubernetes相关组件介绍详见前面的文章。
环境说明
服务器环境
| 主机名 | 操作系统版本 | IP地址 | 角色 | 安装软件 |
|---|---|---|---|---|
| spark32 | CentOS 7.0 | 172.16.206.32 | Kubernetes Master、Harbor | docker-ce 18.09.4、kubelet v1.14.0、kubeadm v1.14.0、etcd 3.3.10、kube-apiserver v1.14.0、kube-scheduler v1.14.0、kube-controller-manager v1.14.0、kube-proxy、flannel v0.11.0、kubectl v1.14.0、pause 3.1 |
| spark17 | CentOS 7.0 | 172.16.206.17 | Kubernetes Node | docker-ce 18.09.4、kubelet v1.14.0、kubeadm v1.14.0、kube-proxy v1.14.0、flannel v0.11.0、pause 3.1 |
| ubuntu31 | Ubuntu 16.04 | 172.16.206.31 | Kubernetes Node | docker-ce 18.09.4、kubelet v1.14.0、kubeadm v1.14.0、kube-proxy v1.14.0、flannel v0.11.0、pause 3.1 |
【注意】:如果操作系统选择的是CentOS的,建议操作系统选择CentOS 7.3+的,从7.3+开始,默认安装的xfs文件系统的 ftype=1,这样docker可以使用官方推荐的存储驱动:overlay2
如果当前系统小于7.3,并且ftype=0,有几个方法:
- 重新创建xfs文件系统
- https://superuser.com/questions/1321926/recreating-an-xfs-file-system-with-ftype-1,没试过这种方法
- 如果你的主机上的卷组还有其他空间,可以重新分配一个逻辑卷,并且在格式化时指定 ftype=1,修改docker的默认存储路径(/var/lib/docker)为新创建的逻辑卷。
【示例】:如何查看xfs文件系统的ftype的值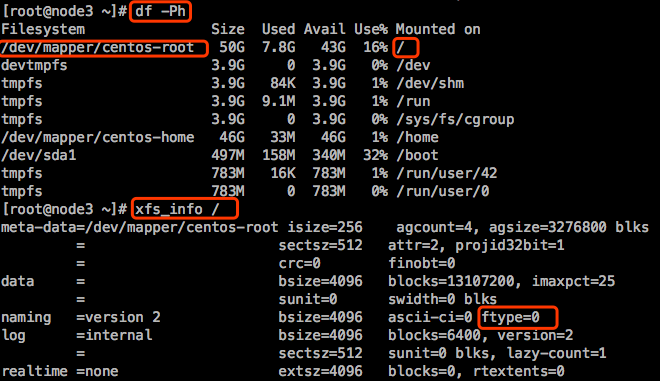
安装准备
1.关闭iptables和firewalld
每个节点都需要做
2.集群主机时间同步
采用NTP(Network Time Protocol)方式来实现, 选择一台机器, 作为集群的时间同步服务器, 然后分别配置服务端和集群其他机器。
参见之前的博客文档安装部署Apache Hadoop (完全分布式模式并且实现NameNode HA和ResourceManager HA)/)
3.禁用SELINUX
每个节点都需要做
4.配置/etc/hosts
每个节点都需要配置
5.docker会生成大量的ip规则,有可能对iptables内部的nfcall,需要打开内生的桥接功能
每个节点都需要配置
安装配置master节点
安装docker-ce、kubelet、kubeadm、kubectl
我们使用阿里云仓库。点击访问阿里云仓库,可以找到docker-ce和kubernetes,在右侧有“帮助”,里面会有说明。
|
|
你也可以自己安装时指定固定的版本安装,我这里默认使用最新的稳定版本1.14.0。以kubeadm为例,查看仓库里有哪些版本可以安装:
配置启动docker
接下来需要安装apiserver、controller manager、scheduler、kube-proxy。kubeadm安装Kubernetes集群时,这些组件是跑在静态Pods中的,官网Static Pod文档。
docker是需要去docker仓库里下载所依赖的每一个镜像文件,这些镜像文件放在google的gcr仓库里,可能下载不了。我这里临时改下docker的配置文件,临时添加个代理,等集群安装完去掉代理。
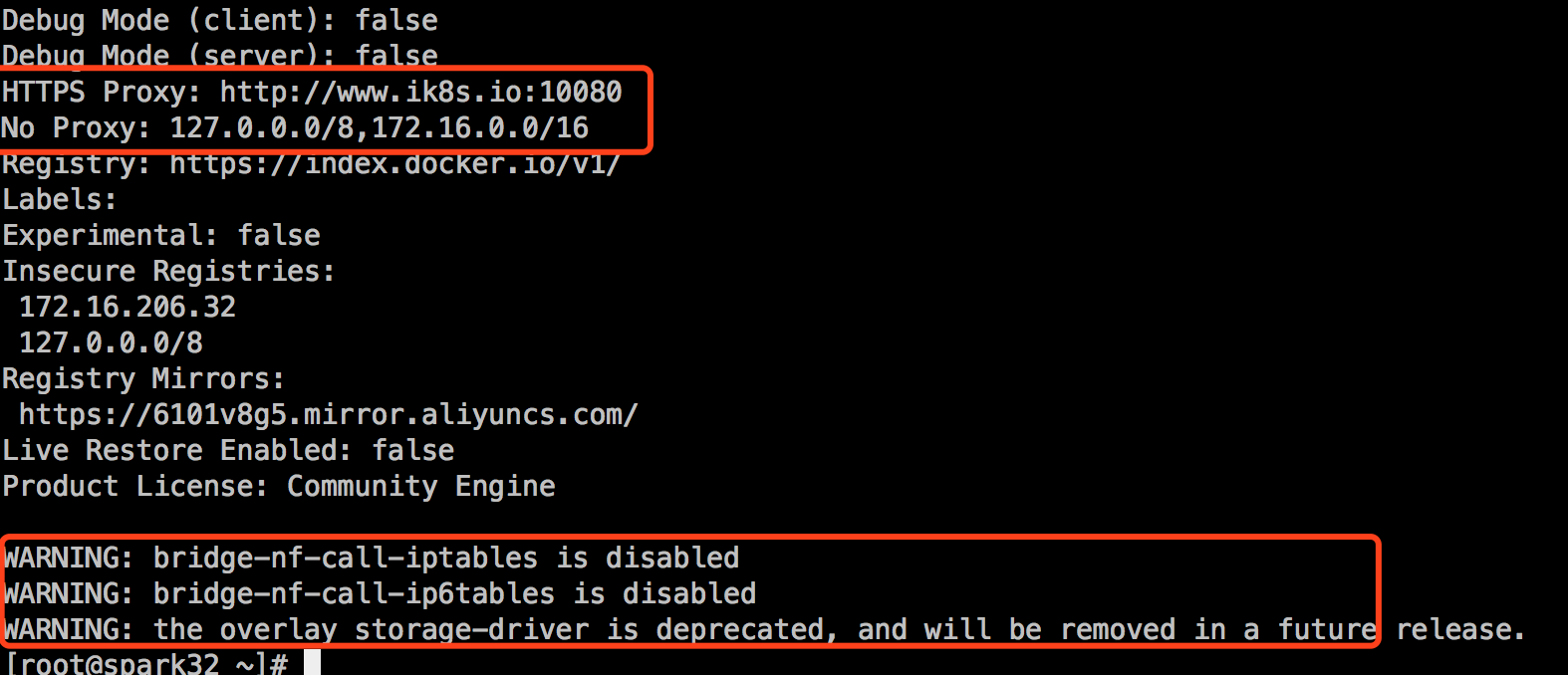
如上图所示,有个提示,Storage Driver: overlay,以后会被移除。我这里改为overlay2。具体关于存储方面的可仔细阅读docker官方文档相应章节
|
|
【注意】:如果你自己有代理,即使你在服务器上配置了访问所有地址都走代理,在使用命令:docker pull k8s.gcr.io/kube-apiserver:v1.14.0 就可以拉取镜像了,一定要在 /usr/lib/systemd/system/docker.service 里配置代理地址,比如:Environment=”HTTPS_PROXY=http://127.0.0.1:8118“
Environment=”HTTP_PROXY=http://127.0.0.1:8118“
配置kubelet
|
|
早期的k8s要求,每一个节点都不能打开swap设备。如果开了,不让你启动。但是我们可以人为的去忽略它,定义的方式就是上面这个参数。
如果不配置这个,在下面使用kubeadm init初始化master时会报如下错误:
此时不能启动kubelet,它的配置文件还没有生成,在初始化master节点的过程中会生成kubelet的配置文件,并且启动kubelet。先设置开机自启动:
初始化master节点
使用kubeadm安装master节点的各组件。
查看初始化参数:
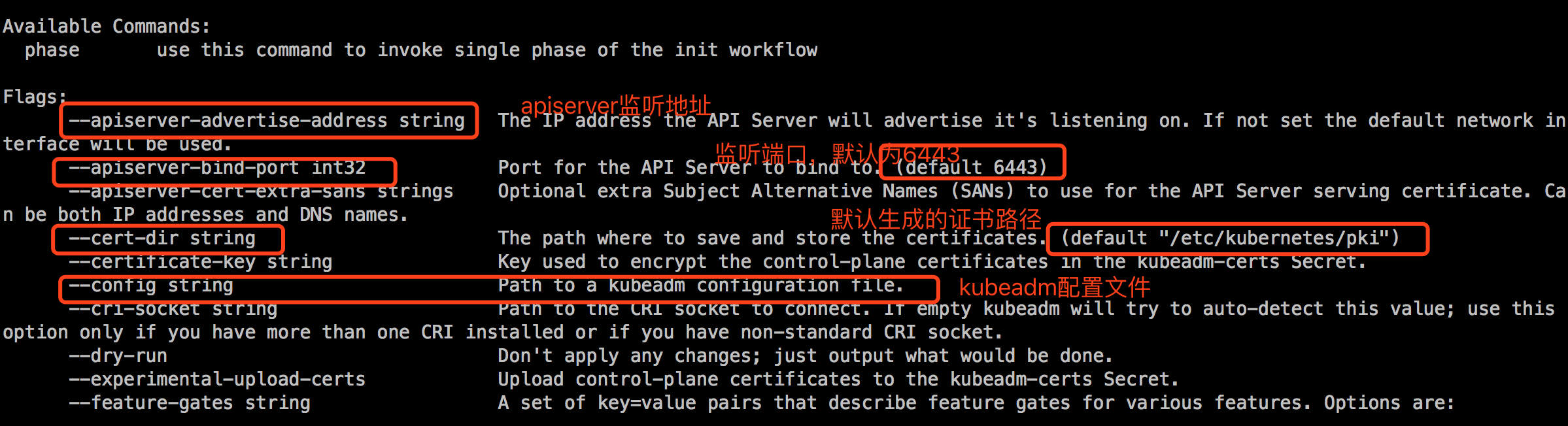
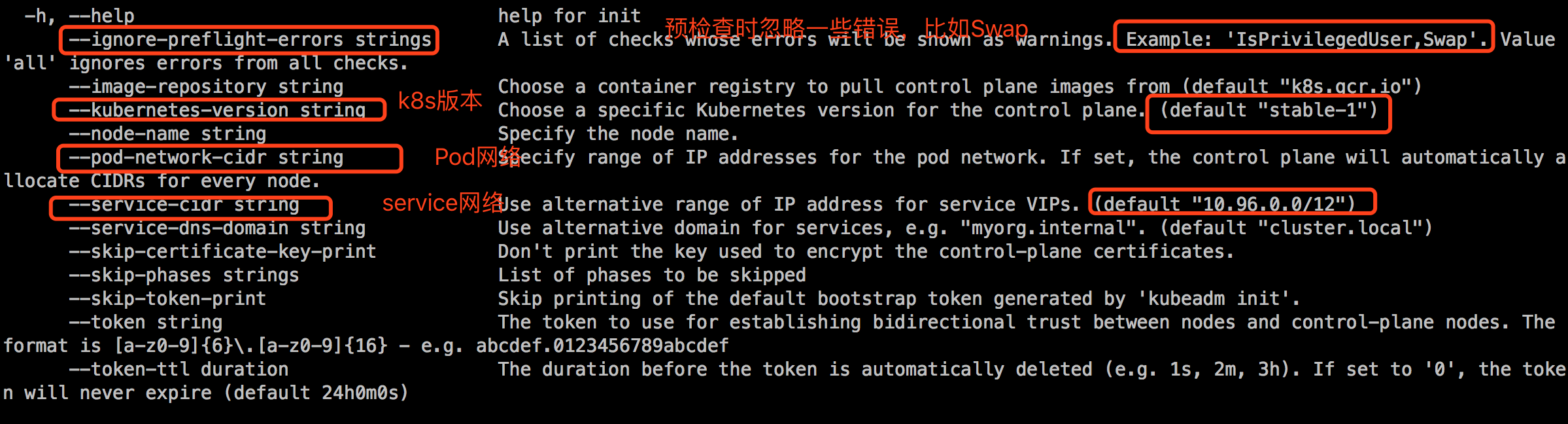
在初始化前,我们可以打印出kubeadm默认的配置:
下面开始初始化:
问题:初始化时发现网上找的代理已经失效了,拉取不了gcr仓库的镜像。
先查看kubeadm初始化master需要哪些镜像:
去掉docker配置文件中代理配置:
配置阿里云加速:参照前面博客CentOS安装Docker CE
从阿里云registry拉取镜像
因为kubeadm安装的docker镜像默认是k8s.gcr.io网站的,所以需要改一下标签:
下面再次初始化:
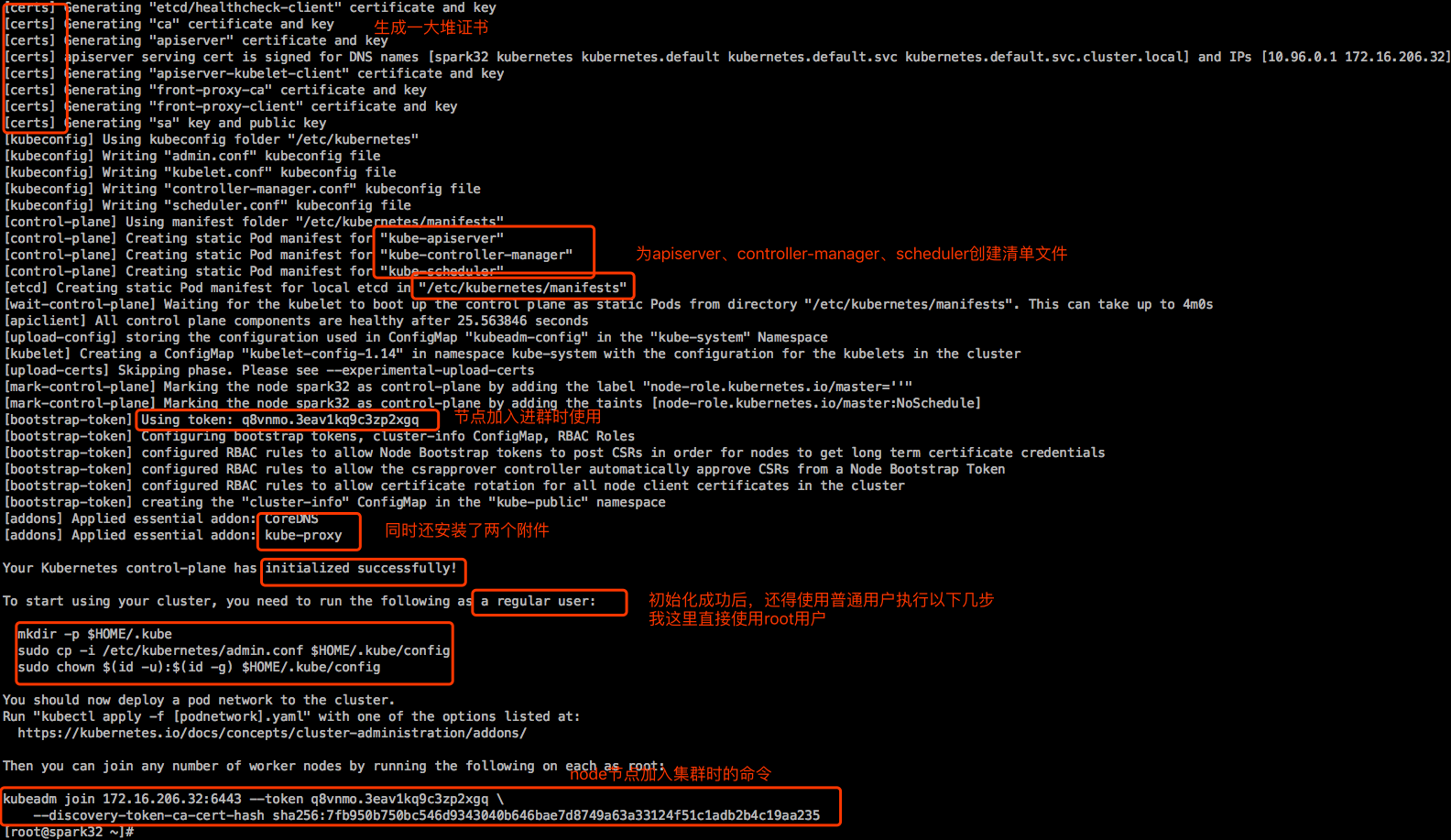
【说明】:
- dns附件在k8s上已经进化到第三版了。第一版叫skydns,后来被kubedns所取代,而在1.11版开始,才正式被CoreDNS所取代。CoreDNS支持前面两版不支持的高级功能,比如像很多资源的动态配置等。
- kube-proxy是作为附件运行的,也是托管在k8s之上。来帮忙负责生成service资源的相关iptables或ipvs规则。从1.11版本开始,默认开始使用的是ipvs。如果当前系统支不支持,默认安装上不支持的时候自动降级为iptables。1.10版及之前都是iptables,那时候使用ipvs还不成熟。
- 这个token是个认证令牌,其实是个域共享密钥,意思是当前这个集群不是谁都能加入进来的,你要想加入进来得拿着这个令牌。这个token是动态生成的,复制保存下来,免得以后找不着了。注意这个令牌有效期是24小时,过了24小时在拿这个令牌来加入集群就会报认证错误,具体看下面的章节-安装配置Ubuntu 16.04 node节点
- –discovery-token-ca-cert-hash:做发现时TLS BootStrap那个相关证书的或者私钥文件的hash码,hash码不对是不会让加入集群的,复制保存下来。
|
|
【说明】:admin.conf里面是kubeadm帮我们生成的一个被kubectl可以拿来作为配置文件,指定连接至k8s的apiserver,并完成认证的配置文件。这里面包含了认证信息,认证证书信息。
kubeadm init workflow:
查看kubelet状态,此时已经启动起来了。
查看集群组件状态:kubectl get cs/componentstatus
这里没有显示apiserver的状态,如果apiserver不健康,我们是得不到这些组件健康状态信息的。
查看集群节点信息:
此时只有主节点一个节点,而且是未就绪状态,因为此时还缺少一个网络附件,此时Pod之间无法通信。
查看集群Pods状态信息(默认查的是default空间的pods,系统级的pods都是在kube-system空间):
coredns处于pending状态,未决定的,行将发生的状态,是因为此时网络插件还没有安装。此时/etc/cni/目录也不存在。
【注意】:原来kubeadm 1.14.0版本初始化master节点时,已经支持从其他仓库下载需要的镜像,选项为:–image-repository string
这就意味着我们不需要像上面那样从阿里云registry下载镜像,在打tag了。
部署网络附件flannel
官网:https://github.com/coreos/flannel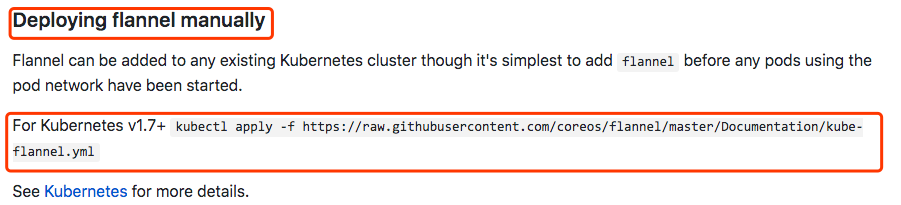
看到这些并不是执行好了,此时正在拉取flannel镜像。下载很慢,耐心等待。可以使用docker images查看是否下载完成。。。
可以使用docker images查看当前服务器上下载的镜像,如果一直没有下来,直接运行命令拉取:
拉取下来后,过一会儿,对应的flannel的pod就会启动起来了。
查看集群Pods状态:
此时再次查看master节点状态,已经是就绪状态了:
安装配置CentOS 7 node节点
我这里以spark17节点为例:
安装docker-ce、kubelet、kubeadm
在master节点上远程拷贝 docker-ce.repo、kubernetes.repo 到node3节点。
安装docker-ce、kubelet、kubeadm
启动docker:
配置启动docker
修改docker的Storage Driver:
重启docker并设置开机自启动:
配置kubelet
|
|
加入集群
我这里由于上面kubeadm init的时候没有使用 –image-repository string 指定从其他registry下载镜像,所以我先下载下来需要的镜像,然后再加入到集群中。
或者可以在master节点上,把镜像docker save保存为tar,然后到node节点上docker load为镜像。以flannel为例:
加入集群:
要等待几分钟,node节点会下载kube-proxy和flannel,启动起来,才算真正完成。可以使用 kubectl get nodes 查看节点状态。
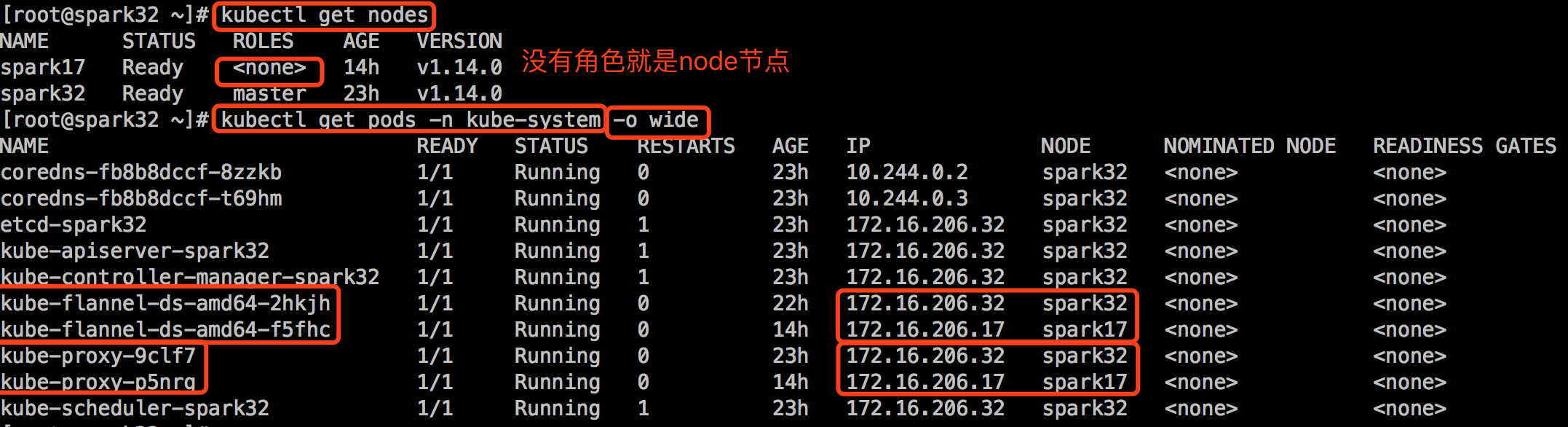
安装配置Ubuntu 16.04 node节点
集群中有一台服务器的操作系统是Ubuntu 16.04,作为Node节点。
关闭防火墙:
查看apparmor(相当于CentOS中的SELinux)状态:
检查nf-call:
安装docker-ce、kubelet、kubeadm
我们使用阿里云仓库。点击访问阿里云仓库,可以找到docker-ce和kubernetes,在右侧有“帮助”,里面会有说明。
安装docker
https://yq.aliyun.com/articles/110806
step 1: 安装必要的一些系统工具
step 2: 安装GPG证书
Step 3: 写入软件源信息
Step 4: 更新并安装 Docker-CE
有个WARNING,根据错误提示,只是cgroups中的swap account没有开启。这个功能应该是用在 docker run -m=1524288 -it ubuntu /bin/bash 类似的命令,用来限制一个docker容器的内存使用上限,所以这里只是WARNING,不影响使用。
解决:
编辑/etc/default/grub,找到 GRUB_CMDLINE_LINUX=””,在双引号里面输入cgroup_enable=memory swapaccount=1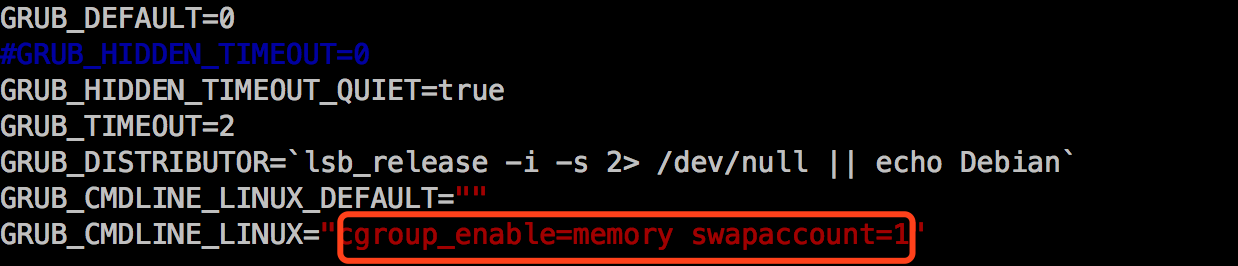
安装kubelet、kubeadm
|
|
下面这条命令需要切换到root用户运行,普通用户sudo执行时一直提示要求使用root用户执行:
下面在切回到普通用户执行:
配置kubelet
Kubernetes 1.8开始要求关闭系统的Swap,如果不关闭,默认配置下kubelet将无法启动。可以通过kubelet的启动参数–fail-swap-on=false更改这个限制。配置忽略swap:
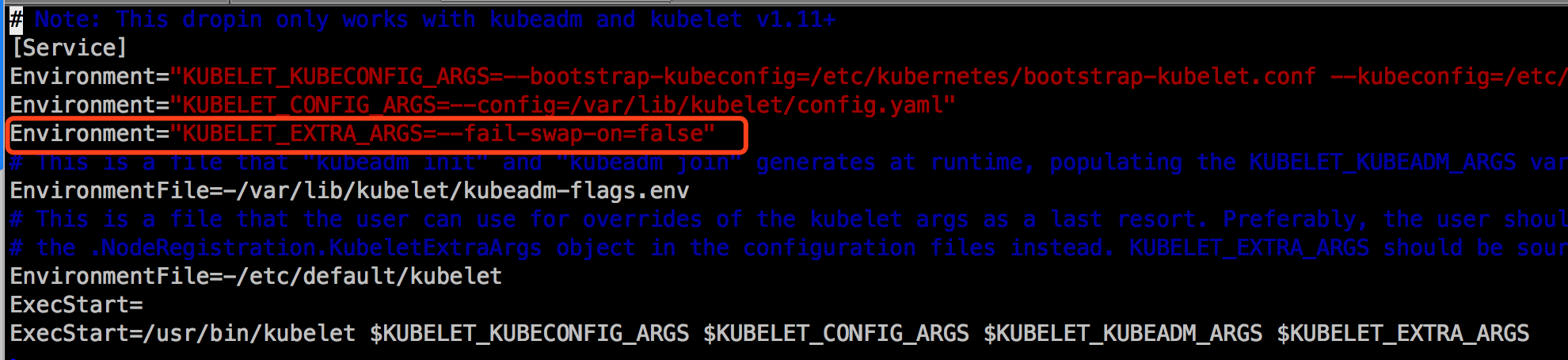
加入集群
把需要的3个镜像下载下来,分别是kube-proxy、pause、flannel。
加入集群:
切换到root用户,执行如下命令:
但是发现报错了:error execution phase preflight: unable to fetch the kubeadm-config ConfigMap: failed to get config map: Unauthorized
解决:https://github.com/kubernetes/kubeadm/issues/1310
TTL for the token should be 24h.我这个是后面几天加的新节点。
回到master节点,查看集群token:

生成一个新的token:

再次回到node节点执行加入集群命令:

在Ubuntu上使用kubectl,
把master节点上的 $HOME/.kube/config/admin.conf 拷贝到 这台Ubuntu机器的 $HOME/.kube/,并将admin.conf重命名为config
如何从集群中移除Node
如果需要从集群中移除spark17这个Node执行下面的命令:
在master节点上执行:
在spark17节点上执行:
在ubuntu31节点上执行:
重置集群
在master节点上执行如下命令:
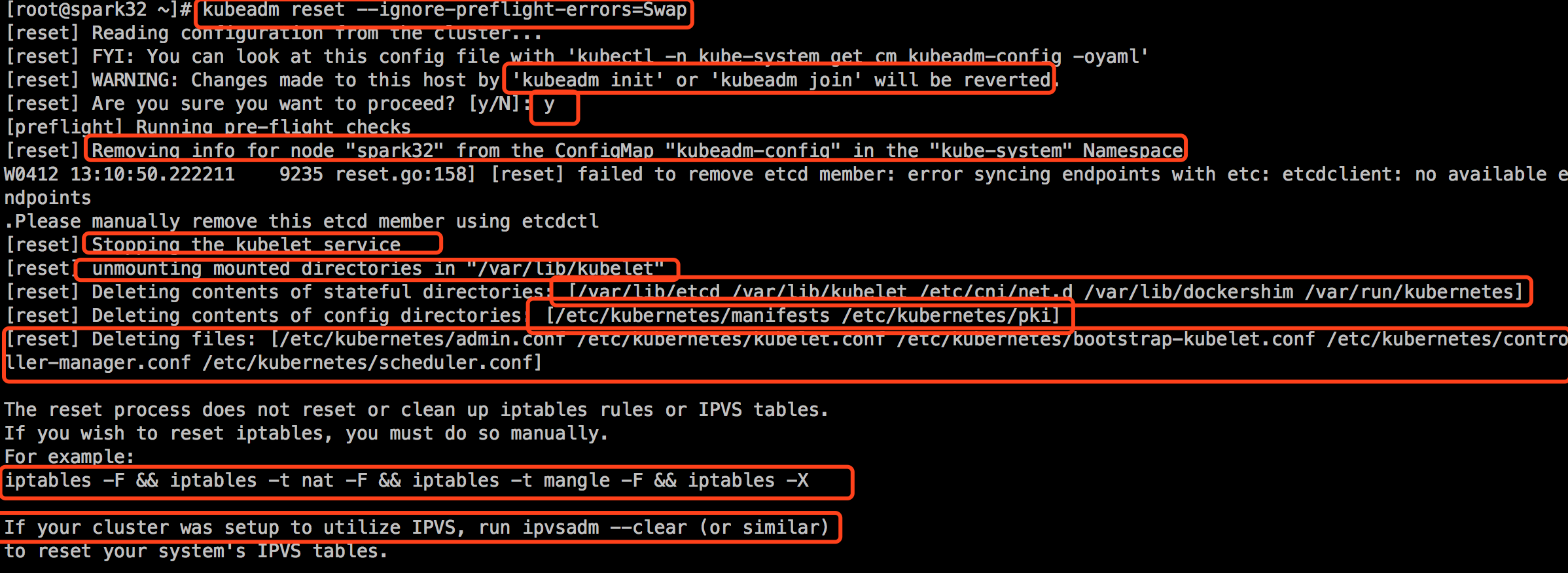
登录另外两台机器:
CentOS:
Ubuntu:
切换到root用户:
坑
kubelet报错
查看kubelet日志,发现kubelet一直在报错:
|
|
|
|
查看当前系统支持哪些subsystem:
发现并不支持pids。
查看当前系统内核:
升级内核,经过测试,在CentOS 7.4默认的内核为3.10.0-514.26.2.el7.x86_64,默认是开启了pids subsystem,我这边使用yum升级内核为 3.10.0-957.el7.x86_64
查看仓库里有哪些版本的内核,并安装:
由于CentOS 7使用grub2作为引导程序 ,所以和CentOS 6有所不同,并不是修改/etc/grub.conf来修改启动项,需要如下操作:
重启后,查看内核版本,并查看是否支持pids subsystem。
此时已经支持了pids subsystem,查看kubelet已经不报错了
apiserver疯狂刷日志:OpenAPI AggregationController: Processing item k8s_internal_local_delegation_chain_0000000001
|
|
疯狂的刷这两行日志。。。
网上查了在1.14.0版本上确实有人遇到这样的情况,见kubernetes issue:

但如今装的是1.14.0版本,只能尝试着降低apiserver这个组件的日志级别。基本上每个 kubernetes 组件都会有个通用的参数 –v;这个参数用于控制 kubernetes 各个组件的日志级别。官方关于apiserver命令行文档:https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/,里面可以看到有个关于日志级别的选项:
关于Kubernetes组件输出日志级别说明:
kubeadm init在初始化master节点的时候生成了apiserver组件的manifests,在 /etc/kubernetes/manifests/ 目录下。修改文件kube-apiserver.yaml:
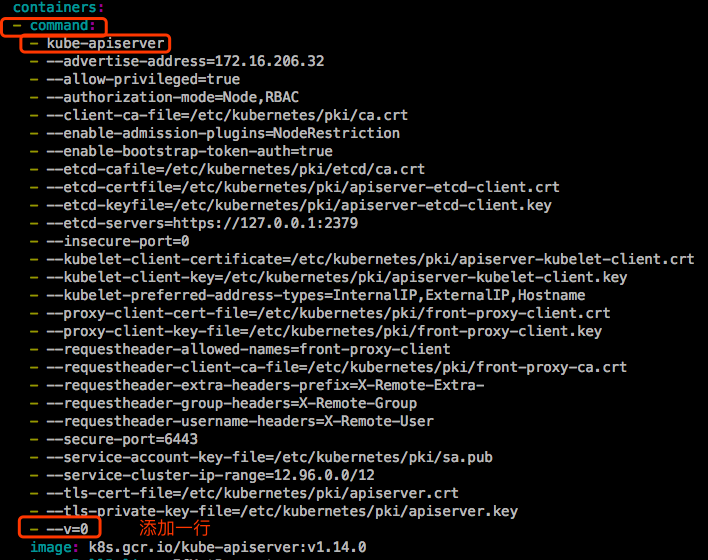
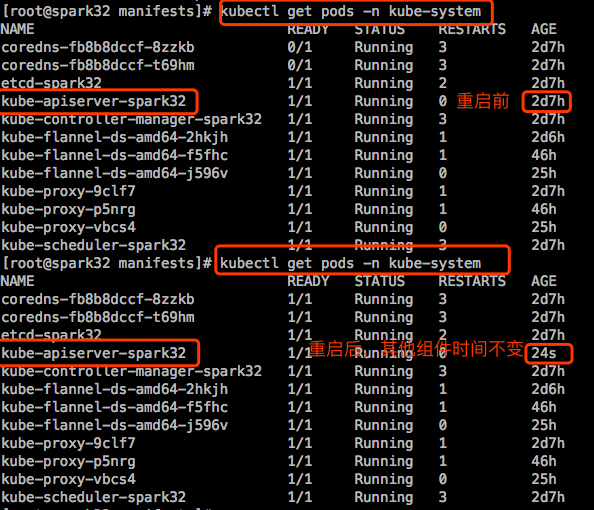
然后重启kubelet,在重启之前我们先查看当前集群的pod,注意apiserver这个pod的运行时间,等会重启kubelet之后,在运行查询pod的命令,会发现apiserver的运行时间改了,其实是kubelet检测到了kube-apiserver的manifest文件改变了,于是重新生成了pod。
再去查看apiserver pod的日志,就发现没那么多输出了。
【说明】:
1.静态pod(DaemonSet)在特定的节点上直接通过 kubelet 守护进程进行管理,API 服务无法管理。它没有跟任何的副本控制器进行关联,kubelet 守护进程对它进行监控,如果崩溃了,kubelet 守护进程会重启它。Kubelet 通过 Kubernetes API 服务为每个静态 pod 创建 镜像 pod,这些镜像 pod 对于 API 服务是可见的,但是不受它控制。
2.kubeadm init workflow里面有一句: