
RabbitMQ介绍
消息系统通过将消息的发送和接收分离来实现应用程序的异步和解偶。
或许你正在考虑进行数据投递,非阻塞操作或推送通知。或许你想要实现发布/订阅,异步处理,或者工作队列。所有这些都属于消息系统的模式。
RabbitMQ是一个消息代理,一个消息系统的媒介。它可以为你的应用提供一个通用的消息发送和接收平台,并且保证消息再传输过程中的安全。
RabbitMQ是一个在AMQP协议标准上完整的、可复用的企业消息系统。它遵循Mozilla Public License开源协议,采用Erlang语言实现的工业级的消息队列。
RabbitMQ运行原理
RabbitMQ的两大核心组件是Exchange和Queue,以下是它的运行原理图: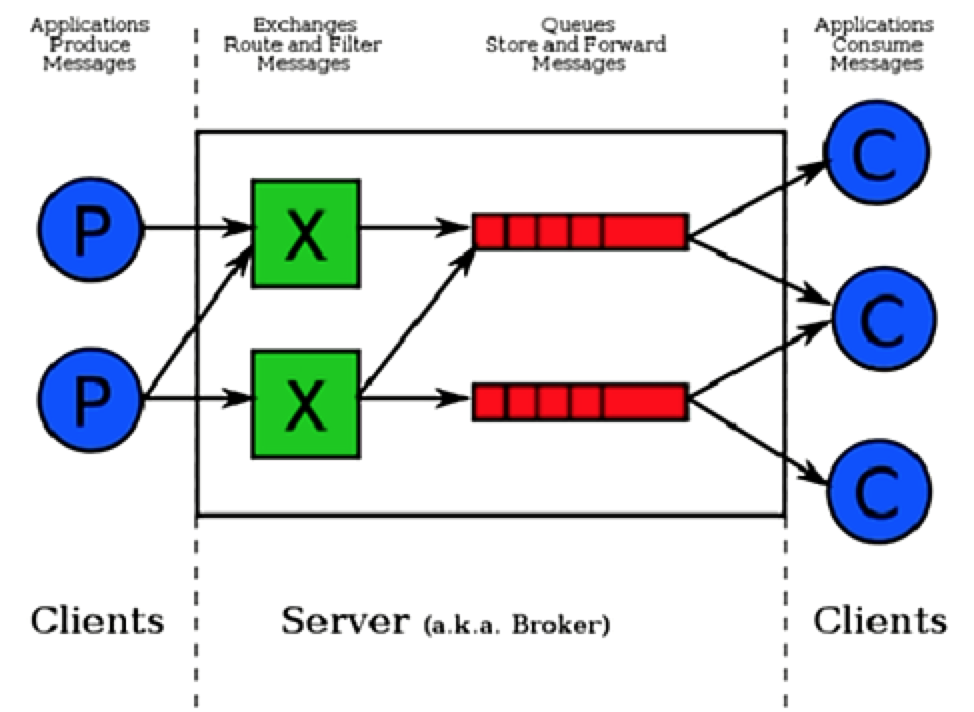
RabbitMQ重要术语
1.Server(broker): 接受客户端连接,实现AMQP消息队列和路由功能的进程。
2.Vitual Host: 这是一个虚拟概念,类似于权限控制组,一个Vitual Host里面可以有若干个Exchange和Queue,但是权限控制的最小粒度是Vitual Host。
3.Exchange: 接收生产者发送的消息,并根据Binding规则将消息路由给服务器中的队列。ExchangeType决定了Exchange路由消息的行为,例如,在RabbitMQ中,ExchangeType有direct、Fanout和Topic三种,不同类型的Exchange路由的行为是不一样的。
4.Message Queue: 消息队列,用于存储还未被消费者消费的消息。
5.Message: 由Header和Body组成,Header是由生产者添加的各种属性的集合,包括Message是否被持久化、由哪个Message Queue接受、优先级是多少等。而body是真正需要传输的APP数据。
6.BindingKey: 所谓绑定就是将一个特定的一个Exchange和一个特定的Queue绑定起来,绑定关键字称为BindingKey。
三种ExchangeType
RabbitMQ消息模型的核心理念是:发布者(producer)不会直接发送任何消息给队列。事实上,发布者(producer)甚至不知道消息是否已经被投递到队列。
发布者(producer)只需要把消息发送给一个交换机(exchange)。交换机非常简单,它一边从发布者方接收消息,一边把消息推送到队列。交换机必须知道如何处理它接收到的消息,是应该推送到指定的队列还是是多个队列,或者是直接忽略消息。这些规则是通过交换机类型(exchange type)来定义的。
直接式交换器类型(Direct)
Direct Exchange:直接交互式处理路由键。需要将一个队列绑定到交换机上,要求该消息与一个特定的路由键完全匹配,这是一个完整的匹配。路由键就是BindingKey。如果一个队列绑定到该交换机上要求路由键“dog”,则只有被标记为“dog”的消息才被转发,不会转发dog.puppy,也不会转发dog.guard,只会转发dog。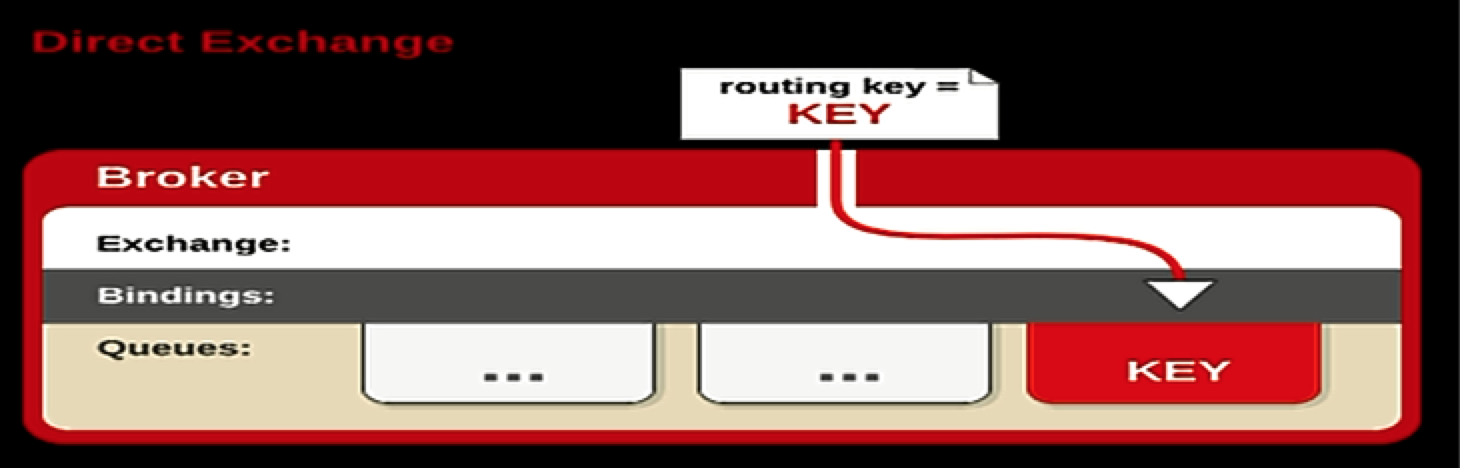
广播式交换机类型(Fanout)
Fanout Exchange:广播式路由键。你只需要简单的将队列绑定到交换机上。一个发送到交换机的消息都被转发到与该交换机绑定的所有队列上。很像子网广播,每台子网内的主机都获得了一份复制的消息。Fanout交换机转发消息是最快的。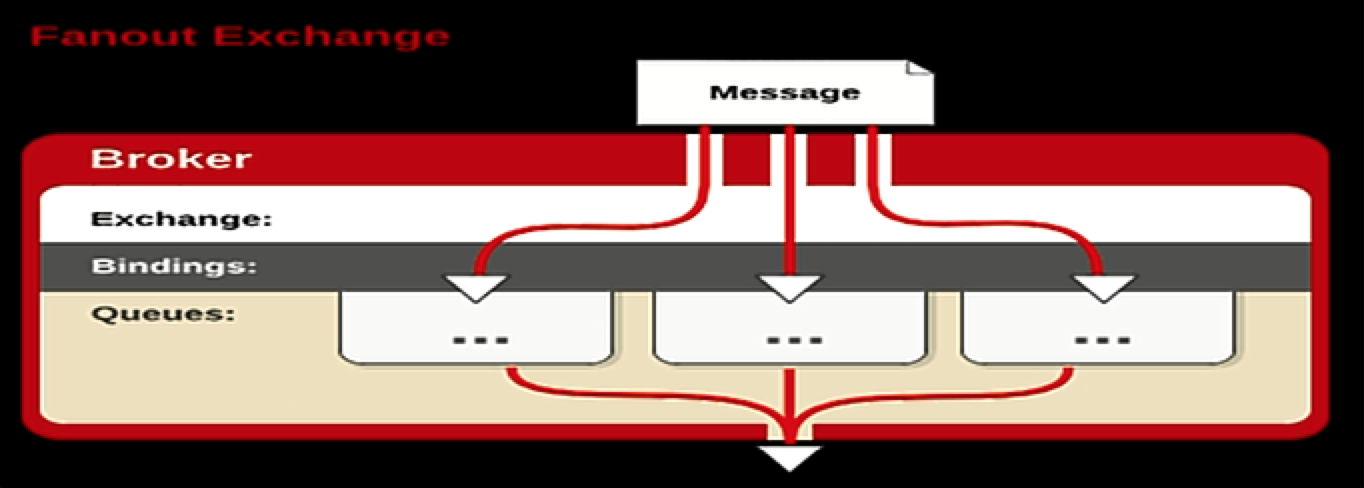
主题式交换金类型(Topic)
Topic Exchange:主题式交换器。通过消息的路由关键字和绑定关键字的模式匹配,将消息路由到被绑定的队列中。这种路由器类型可以被用来支持经典的发布/订阅消息传输类型——使用主题名字空间作为消息寻址模式,将消息传递给那些部分或者全部匹配主题模式的多个消费者。主题交换器类型的工作方式如下:绑定关键字用零个或多个标记构成,每一个标记之间用“.”字符分隔。绑定关键字必须用这种形式明确说明,并支持通配符:“”匹配一个词组,“#”零个或多个词组。因此绑定关键字“.stock.#”匹配路由关键字“usd.stock”和“eur.stock.db”,但是不匹配“stock.nasdaq”。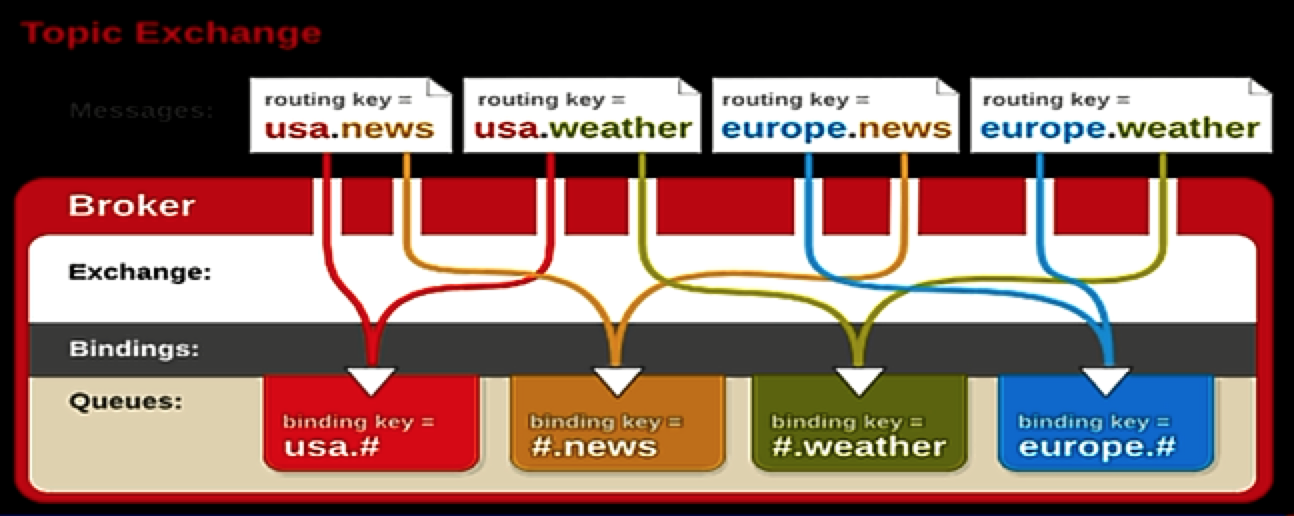
RabbitMQ集群种类
RabbitMQ是用erlang开发的,集群非常方便,因为erlang天生就是一门分布式语言,但其本身并不支持负载均衡。
Rabbit模式大概分为以下三种:单一模式、普通模式、镜像模式。
1.单一模式:最简单的情况,非集群模式。
2.普通模式:默认的集群模式。
对于Queue来说,消息实体只存在于其中一个节点,A、B两个节点仅有相同的元数据,即队列结构。
当消息进入A节点的Queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer。
所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连A或B,出口总在A,会产生瓶颈。
该模式存在一个问题就是当A节点故障后,B节点无法取到A节点中还未消费的消息实体。
如果做了消息持久化,那么得等A节点恢复,然后才可被消费;如果没有持久化的话,然后就没有然后了……
3.镜像模式:把需要的队列做成镜像队列,存在于多个节点,属于RabbitMQ的HA方案。
该模式解决了上述问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在consumer取数据时临时拉取。
该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。
所以在对可靠性要求较高的场合中适用。
集群基本概念
RabbitMQ的集群节点包括内存节点、磁盘节点。内存节点就是将所有数据放在内存,磁盘节点将数据放在磁盘。不过,如果在投递消息时,打开了消息的持久化,那么即使是内存节点,数据还是安全的放在磁盘。
一个rabbitmq集群中可以共享 user,vhost,queue,exchange等,所有的数据和状态都是必须在所有节点上复制的,一个例外是,那些当前只属于创建它的节点的消息队列,尽管它们可见且可被所有节点读取。rabbitmq节点可以动态的加入到集群中,一个节点它可以加入到集群中,也可以从集群环集群会进行一个基本的负载均衡。
集群中有两种节点:
- 内存节点:只保存状态到内存(一个例外的情况是:持久的queue的持久内容将被保存到disk)
- 磁盘节点:保存状态到内存和磁盘。
内存节点虽然不写入磁盘,但是它执行比磁盘节点要好。集群中,只需要一个磁盘节点来保存状态就足够了。
如果集群中只有内存节点,那么不能停止它们,否则所有的状态,消息等都会丢失。
镜像模式部署集群
环境信息
| 主机名 | 操作系统版本 | IP地址 | 安装软件 |
|---|---|---|---|
| console | CentOS 7.0 | 114.55.248.157 | haproxy-1.5.14 |
| log1 | CentOS 7.0 | 114.55.29.86 | erlang、rabbitmq-server-3.5.0-1.noarch.rpm |
| log2 | CentOS 7.0 | 114.55.29.241 | erlang、rabbitmq-server-3.5.0-1.noarch.rpm |
【环境说明】:集群中有3台机器,console主机作为反向代理,另外两台是rabbitmq server,一台使用磁盘模式,一台使用内存模式。
【注意】:请确保两台rabbitmq server主机的/etc/hosts里有ip地址和主机名的对应关系。如:
114.55.29.86 log1
114.55.29.241 log2
集群每个节点安装rabbitmq server
log1和log2分别安装rabbitmq server。
1.配置好epel源
rpm -Uvh http://download.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-5.noarch.rpm
2.安装依赖包
[root@log1 local]# yum install erlang –y
3.安装rabbitMq
[root@log1 local]# wget http://www.rabbitmq.com/releases/rabbitmq-server/v3.5.0/rabbitmq-server-3.5.0-1.noarch.rpm
[root@log1 local]# yum localinstall rabbitmq-server-3.5.0-1.noarch.rpm -y
4.添加开机启动
[root@log1 local]# chkconfig rabbitmq-server on
5.启动
[root@log1 local]# service rabbitmq-server start
Starting rabbitmq-server: SUCCESS
rabbitmq-server.
6.开启web管理界面
[root@log1 local]# rabbitmq-plugins enable rabbitmq_management
The following plugins have been enabled:
mochiweb
webmachine
rabbitmq_web_dispatch
amqp_client
rabbitmq_management_agent
rabbitmq_management
Applying plugin configuration to rabbit@log1... started 6 plugins.
7.修改配置文件
[root@log1 local]# cp /usr/share/doc/rabbitmq-server-3.5.0/rabbitmq.config.example /etc/rabbitmq/rabbitmq.config
修改用户配置 让其可以通过远程访问 不限于localhost。注意:rabbitmq从3.3.0开始禁止使用guest/guest权限通过除localhost外的访问。
[root@log1 local]# vim /etc/rabbitmq/rabbitmq.config
{loopback_users, []} 删除前面的注释%%,同时注意后面的逗号,只有一个配置项的时候,请删除后面的逗号。
以上7步在log2主机上都要执行
8.因为默认用户为guest,要添加其他的管理账户。
注意:如果是集群的话,只要在一台主机设置即可,其它会自动同步。
[root@log1 local]# rabbitmqctl add_user zxadmin wisedu@2016
Creating user "zxadmin" ...
[root@log1 local]# rabbitmqctl set_user_tags zxadmin administrator
Setting tags for user "zxadmin" to [administrator] ...
[root@log1 local]# rabbitmqctl set_permissions -p / zxadmin ".*" ".*" ".*"
Setting permissions for user "zxadmin" in vhost "/" ...
9.重启rabbitMQ
[root@log1 local]# service rabbitmq-server restart
Restarting rabbitmq-server: SUCCESS
rabbitmq-server.
10.访问管控台
浏览器输入URL:http://ip/15672

设置每个节点Cookie
Rabbitmq的集群是依赖于erlang的集群来工作的,所以必须先构建起erlang的集群环境。Erlang的集群中各节点是通过一个magic cookie来实现的,这个cookie存放在 /var/lib/rabbitmq/.erlang.cookie 中,文件是400的权限。所以必须保证各节点cookie保持一致,否则节点之间就无法通信。
将其中一台节点上的.erlang.cookie值复制下来保存到其他节点上。或者使用scp的方法也可,但是要注意文件的权限和属主属组。我这里将log1中的cookie 复制到log2中。
1.因为.erlang.cookie是只读的,先修改下log2中的.erlang.cookie权限
[root@log2 rabbitmq]# chmod 777 .erlang.cookie
2.copy log1主机上的.erlang.cookie到log2主机/var/lib/rabbitmq/目录下
[root@log1 rabbitmq]# scp -p .erlang.cookie root@114.55.29.241:/var/lib/rabbitmq/
3.停止所有节点RabbitMq服务,然后使用detached参数独立运行,这步很关键,尤其增加节点停止节点后再次启动遇到无法启动都可以参照这个顺序。
停止:
[root@log1 rabbitmq]# service rabbitmq-server stop
[root@log2 rabbitmq]# service rabbitmq-server stop
启动:
[root@log1 rabbitmq]# rabbitmq-server -detached
Warning: PID file not written; -detached was passed.
[root@log2 rabbitmq]# rabbitmq-server -detached
Warning: PID file not written; -detached was passed.
4.分别查看下每个节点
[root@log1 rabbitmq]# rabbitmqctl cluster_status

[root@log2 rabbitmq]# rabbitmqctl cluster_status
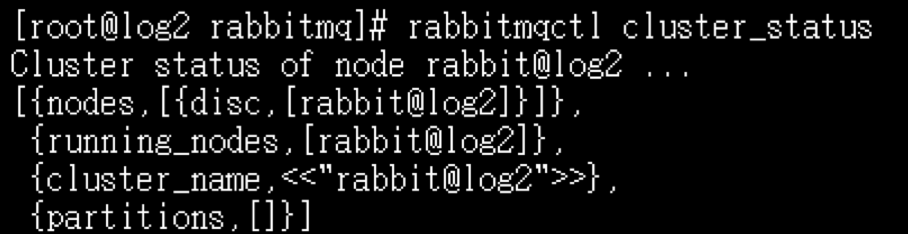
5.将log2作为内存节点与log1连接起来,在log2上执行如下命令:
[root@log2 rabbitmq]# rabbitmqctl stop_app
[root@log2 rabbitmq]# rabbitmqctl join_cluster --ram rabbit@log1
[root@log2 rabbitmq]# rabbitmqctl start_app
上述命令先停掉rabbitmq应用,然后调用cluster命令,将log2连接到log1,使两者成为一个集群,最后重启log2的rabbitmq应用。在这个cluster命令下,log2是内存节点,log1是磁盘节点(RabbitMQ启动后,默认是磁盘节点)。
log1如果要使log2在集群里也是磁盘节点,join_cluster 命令去掉–ram参数即可:
[root@log2 rabbitmq]# rabbitmqctl join_cluster rabbit@log1
只要在节点列表里包含了自己,它就成为一个磁盘节点。在RabbitMQ集群里,必须至少有一个磁盘节点存在。
6.再次查看各节点状态
[root@log1 rabbitmq]# rabbitmqctl cluster_status
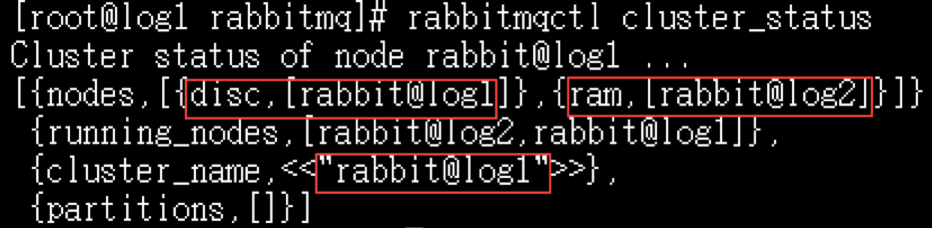
[root@log2 rabbitmq]# rabbitmqctl cluster_status

这样RabbitMQ集群就正常工作了。可以访问任意一个web管控台:http://ip/15672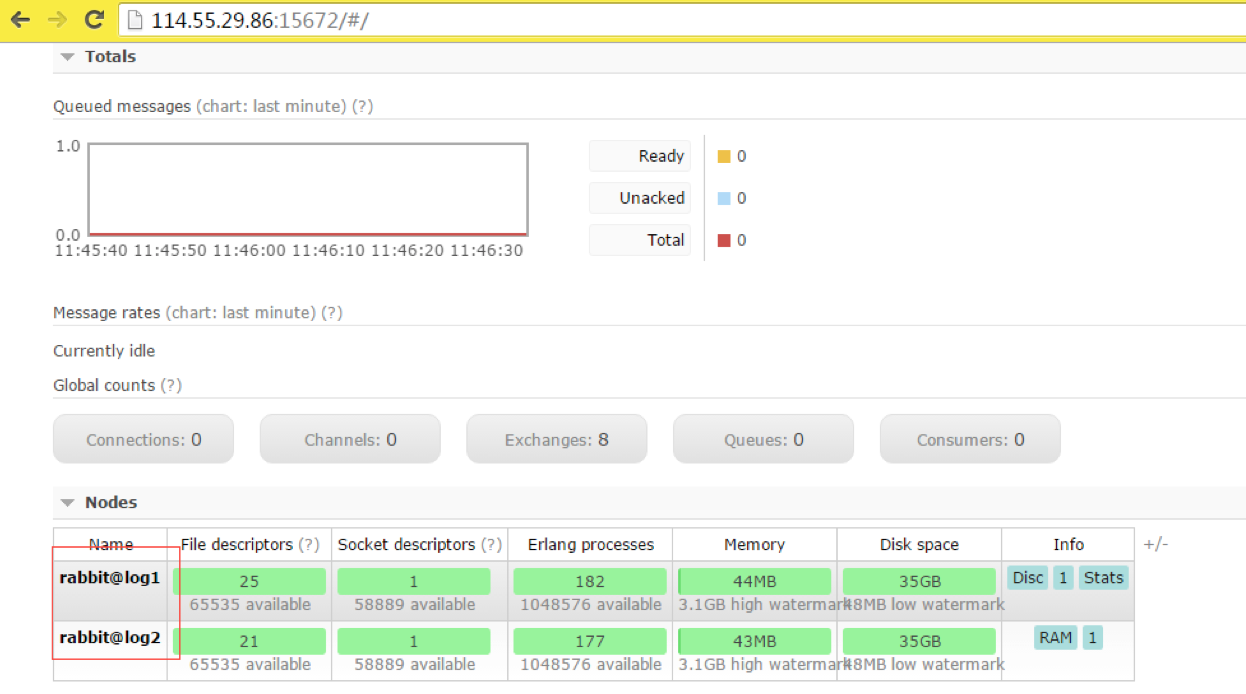
添加镜像模式配置
上面配置RabbitMQ默认集群模式,但并不保证队列的高可用性,尽管交换机、绑定这些可以复制到集群里的任何一个节点,但是队列内容不会复制,虽然该模式解决一部分节点压力,但队列节点宕机直接导致该队列无法使用,只能等待重启,所以要想在队列节点宕机或故障也能正常使用,就要复制队列内容到集群里的每个节点,需要创建镜像队列。
1.安装haproxy
haproxy是在主机名为console上安装的。可以选择源代码编译安装或者yum安装,在这里我选择了yum安装。安装版本:haproxy-1.5.14-3.el7.x86_64
[root@console ~]# yum install -y haproxy
2.修改配置/etc/haproxy/haproxy.cfg
[root@console ~]# vim /etc/haproxy/haproxy.cfg
删除 main frontend which proxys to the backends以下的所有内容,并添加
listen rabbitmq_cluster 0.0.0.0:5672
mode tcp
balance roundrobin
server rqslave1 114.55.29.241:5672 check inter 2000 rise 2 fall 3
server rqmaster 114.55.29.86:5672 check inter 2000 rise 2 fall 3
如果有3台或3台以上,可以把disc节点注释掉,原因就是让rabbitmq性能最佳化。这样负载均衡器会监听5672端口,轮询多个内存节点的5672端口,磁盘节点可以只做备份不提供给生产者、消费者使用,当然如果我们服务器资源充足情况也可以配置多个磁盘节点。此外,还需要修改defaults段配置: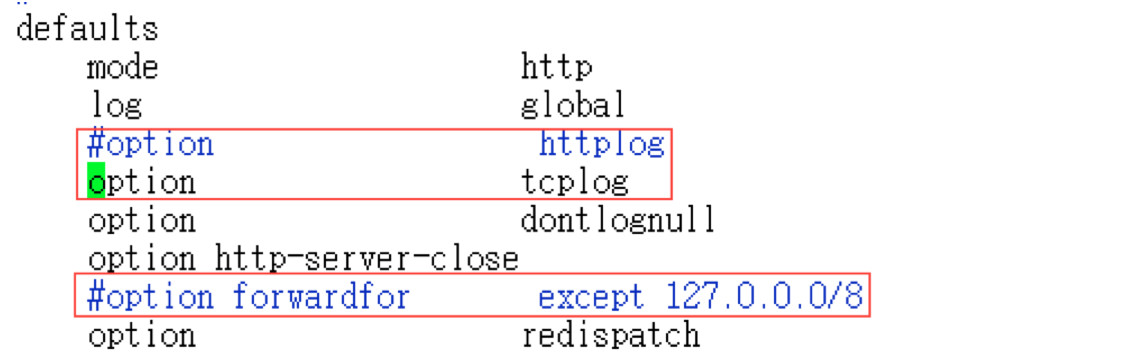
检查配置文件语法:
[root@console ~]# haproxy -c -f /etc/haproxy/haproxy.cfg
启动haproxy:
[root@console ~]# service haproxy start
Redirecting to /bin/systemctl start haproxy.service
3.配置策略:设置ha模式
使用Rabbit镜像功能,需要基于rabbitmq策略来实现,政策是用来控制和修改群集范围的某个vhost队列行为和Exchange行为。
其中ha-mode有三种模式:
- all: 同步至所有的;
- exactly: 同步最多N个机器. 当现有集群机器数小于N时,同步所有,大于等于N时则不进行同步. N需要额外通过ha-params来指定;
nodes: 只同步至符合指定名称的nodes. N需要额外通过ha-params来指定。
在cluster中任意节点启用策略,策略会自动同步到集群节点。我这里设置的是同步全部的queue, 可以按需自己选择指定的queue。语法:rabbitmqctl set_policy [-p vhostpath ] { name } { pattern } { definition } [ priority ]
在log1主机上执行如下命令:
[root@log1 ~]# rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'

这行命令创建了一个策略,策略名称为ha-all,策略模式为 all ,即复制到所有节点,包含新增节点,策略正则表达式为 “^” 表示所有匹配所有队列名称。
集群退出
假设要把log2退出集群。
在log2上执行:
#rabbitmqctl stop_app
#rabbitmqctl reset
#rabbitmqctl start_app
在集群主节点上执行:
# rabbitmqctl forget_cluster_node rabbit@log2