
Spark介绍
Apache Spark
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架(没有数据存储)。最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一。
Hadoop和Spark
Hadoop常用于解决高吞吐、批量处理的业务场景,例如离线计算结果用于浏览量统计。如果需要实时查看浏览量统计信息,Hadoop显然不符合这样的要求。Spark通过内存计算能力极大地提高了大数据处理速度,满足了以上场景的需要。
与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark有以下特点:
1.快速处理能力
随着实时大数据应用越来越多,Hadoop作为离线的高吞吐、低响应框架已不能满足这类需求。Hadoop MapReduce的Job将中间输出和结果存储在HDFS中,读写HDFS造成磁盘I/O称为瓶颈。Spark允许将中间输出和结果存储在内存中,避免了大量的磁盘I/O。同时Spark自身的DAG执行引擎也支持数据在内存中的计算。Spark官网声称性能比Hadoop快100倍,如图所示。即便是内存不足,需要磁盘I/O,其速度也是Hadoop的10倍以上。
2.易于使用
Spark现在支持Java、Scala、Python和R等语言编写应用程序,大大降低了使用者的门槛。自带了80多个高等级操作符,允许在Scala、Python、R的shell中进行交互式查询。
3.通用性
Spark支持SQL及Hive SQL对数据查询,支持流式计算、支持机器学习和图计算。而且除了Spark core以外,建立在其上的这些功能都是一些库,安装好Spark后,这些库就可以使用了。
4.可用性高
Spark自身实现了Standalone部署模式,还可以跑在Hadoop、Mesos、或者云上。此外,Spark还有丰富的数据源支持。Spark除了可以访问操作系统自身的文件系统和HDFS,还可以访问Cassandra、HBase、Hive、Tachyon以及任何Hadoop的数据源。
Spark中的概念
- RDD:弹性分布式数据集。
- Task:具体执行任务。Task分为ShuffleMapTask和ResultTask两种。ShuffleMapTask和ResultTask分别类似于Hadoop中的Map和Reduce。
- Job:用户提交的作业。一个Job可能由一到多个Task组成。
- Stage:Job分成的阶段。一个Job可能被划分为一到多个Stage。
- Partition:数据分区。即一个RDD的数据可以划分为多少个分区。
- NarrowDependency:窄依赖,即子RDD依赖于父RDD中固定的Partition。NarrowDependency分为OneToOneDependency和RangeDependency两种。
- ShuffleDependency:shuffle依赖,也称为宽依赖,即子RDD对父RDD中的所有Partition都有依赖。
- DAG:有向无环图。用于反映各RDD之间的依赖关系。
Spark生态系统
整个Spark主要由以下模块组成:
- Spark Core:Spark的核心功能实现,包括:SparkContext的初始化(Driver Application通过SparkContext提交)、部署模式、存储体系、任务提交与执行、计算引擎等。
- Spark SQL:提供SQL处理能力,便于熟悉关系型数据库操作的工程师进行交互查询。此外,还为熟悉Hadoop的用户提供Hive SQL处理能力。
- Spark Streaming:提供流式计算处理能力,目前支持Kafka、Flume、Twitter、MQTT、ZeroMQ、Kinesis和简单的TCP套接字等数据源。此外,还提供窗口操作。
- GraphX:提供图计算处理能力,支持分布式。
- MLlib:提供机器学习相关的统计、分类、回归等领域的多种算法实现。其一致的API接口大大降低了用户的学习成本。
Spark SQL、Spark Streaming、GraphX、MLlib的能力都是建立在核心引擎之上。如下图所示。
Spark核心功能
Spark Core提供Spark最基础与最核心的功能,主要包括以下功能:
- SparkContext:通常而言,Driver Application的执行和输出都是通过SparkContent来完成的,在正式提交Application之前,首先需要初始化SparkContent。SparkContent隐藏了网络通信、分布式部署、消息通信、存储能力、计算能力、缓存、测量系统、文件服务、Web服务等内容,应用程序开发者只需要使用SparkContent提供的API完成功能开发。SparkContent内置的DAGScheduler负责创建Job,将DAG中的RDD划分到不同的Stage,提交Stage等功能。内置的TaskScheduler负责资源的申请、任务的提交及请求集群对任务的调度等工作。
- 存储体系:Spark优先考虑使用各节点的内存作为存储,当内存不足时才会考虑使用磁盘,这极大地减少了磁盘I/O,提升了任务执行效率,使得Spark适用于实时计算、流式计算等场景。此外,Spark还提供了以内存为中心的高容错的分布式文件系统Tachyon供用户进行选择。Tachyon能够为Spark提供可靠的内存级的文件共享服务。
- 计算引擎:计算引擎由SparkContent中的DAGScheduler、RDD以及具体节点上的Executor负责执行的Map和Reduce任务组成。
- 部署模式:由于单节点不足以提供足够的存储和计算能力,所以作为大数据处理的Spark在SparkContext的TaskScheduler组件中提供了对Standalone部署模式的实现和Yarn、Mesos等分布式资源管理系统的支持。通过使用Standallone、Yarn、Mesos等部署模式为Task分配计算资源,提高任务的并发执行效率。除了可用于实际生产环境的Standalone、Yarn、Mesos等部署模式外,Spark还提供了Local模式和local-cluster模式便于开发和调试。
Spark扩展功能
- Spark SQL
- Spark Streaming
- GraphX
- MLlib
Spark部署架构
集群架构
从集群部署的角度看,Spark集群由以下部分组成:
- Cluster Manager:Spark的集群管理器,主要负责资源的分配与管理。集群管理器分配的资源属于一级分配,它将各个Worker上内存、CPU等资源分配给应用程序,但是并不负责对Executor的资源分配。目前Standalone、YARN、Mesos、EC2等都可以作为Spark的集群管理器。
- Worker:Spark的工作节点。对Spark应用程序来说,由集群管理器分配得到资源的Worker节点主要负责以下工作:创建Executor,将资源和任务进一步分配给Executor,同步资源信息给Cluster Manager。
- Executor:执行计算任务的一线进程。主要负责任务的执行以及与Worker、Driver App的信息同步。
- Driver App:客户端驱动程序,也可以理解问客户端应用程序,用于将任务程序转换为RDD和DAG,并与Cluster Manager进行通信与调度。

Spark部署模式
1.一些概念
- Driver:应用驱动程序,可以理解为是老板的客户。
- Master:Spark的主控节点,可以理解为集群的老板。
- Worker:Spark的工作节点,可以理解为集群的各个主管。
- Executor:Spark的工作进程,由Worker监管,负责具体任务的执行。
2.Spark目前支持的部署方式
- 本地部署模式:local、local[N]或者local[N, maxRetries]。主要用于代码调试和跟踪。不具备容错能力,所以不适用于生产环境。local部署模式只有Driver,没有Master和Worker,执行任务的Executor与Driver在同一个JVM进程内。
- 本地集群部署模式:local-cluster[N, cores, memory]。也主要用于代码调试,是源码学习常用的模式。不具备容错能力,不能用于生产环境。local-cluster模式是一种伪分布式集群部署模式,Driver、Master和Worker在同一个JVM内,可以存在多个Worker,每个Worker会有多个Executor,但这些Executor都独自存在于一个JVM进程内。
- Standalone部署模式:spark://。具备容错能力并且支持分布式部署,所以可用于实际的生产。Driver在集群之外,可以是任意的客户端应用程序。Master部署于单独的进程,甚至应该在单独的机器节点上。Master有多个,但同时最多有只有一个处于激活状态。Worker部署于单独的进程,也推荐在单独的节点上部署。
- 第三方部署模式:yarn-standalone、yarn-cluster、mesos://、zk://、simr://等。
安装部署spark
Spark runs on Java 7+, Python 2.6+ and R 3.1+. For the Scala API, Spark 1.6.2 uses Scala 2.10. You will need to use a compatible Scala version (2.10.x).
本地部署模式
下载安装JDK8
# mkdir /usr/java
# tar zxf /usr/local/jdk-8u73-linux-x64.gz -C /usr/java/
# vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_73
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# source /etc/profile
下载安装scala-2.10.6
[root@care ~]# cd /usr/local/
[root@care local]# tar zxf scala-2.10.6.tgz
[root@care local]# vim /etc/profile
# Scala environment
export SCALA_HOME=/usr/local/scala-2.10.6
export PATH=$SCALA_HOME/bin:$PATH
[root@care local]# source /etc/profile
查看是否成功:
[root@care local]# scala -version
配置登录自己不需要输入密码
[root@care ~]# ssh-keygen -t rsa -P ''
[root@care ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub root@localhost
下载安装spark
http://spark.apache.org/downloads.html,我这里选择编译好的二进制版本1.6.1
[root@care local]# tar zxf spark-1.6.1-bin-hadoop2.6.tgz
[root@care local]# mv spark-1.6.1-bin-hadoop2.6 spark-1.6.1
[root@care local]# vim /etc/profile
# Spark environment
export SPARK_HOME=/usr/local/spark-1.6.1
export PATH=$SPARK_HOME/bin:$PATH
[root@care local]# source /etc/profile
[root@care local]# cd spark-1.6.1/conf/
[root@care conf]# cp spark-env.sh.template spark-env.sh
[root@care conf]# vim spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_73
export SCALA_HOME=/usr/local/scala-2.10.6
export SPARK_MASTER_IP=172.16.7.119
export SPARK_WORKER_MEMORY=4G
如果要选择源码编译安装,Build方法网址:
http://spark.apache.org/docs/latest/building-spark.html
启动spark
[root@care ~]# /usr/local/spark-1.6.1/sbin/start-all.sh
查看启动的进程:
[root@care ~]# jps
查看Web UI
Master UI:http://172.16.7.119:8080/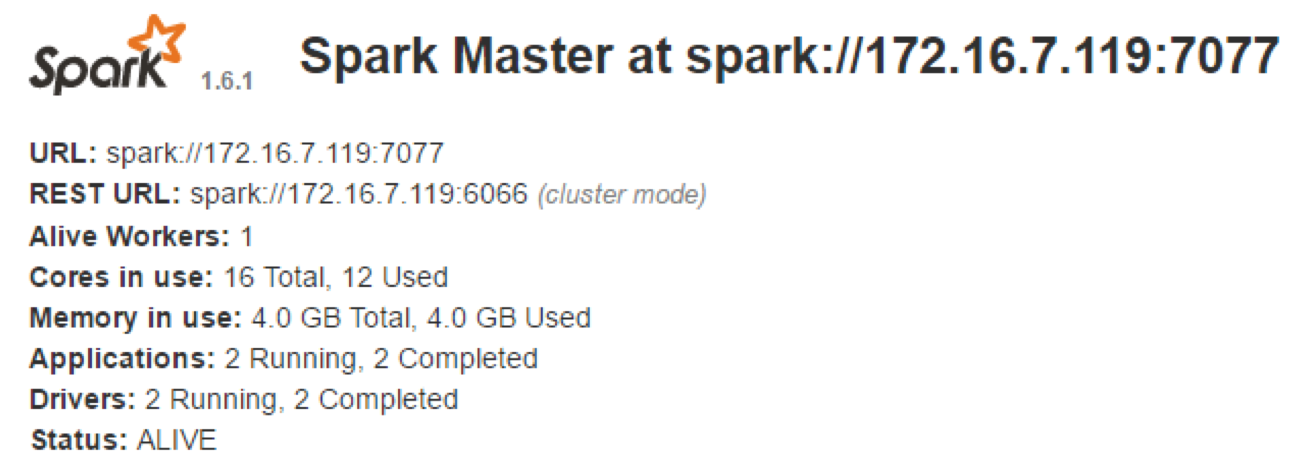
Worker UI:http://172.16.7.119:8081/
停止spark
[root@care ~]# /usr/local/spark-1.6.1/sbin/stop-all.sh
Standalone模式部署spark (无HA)
Spark Standalone采用了Master/Slaves架构的集群模式,因此,存在着Master单点故障。
Spark提供了两种单点故障的解决方案:
- 基于文件系统的单点恢复
- 基于ZooKeeper的Standby Masters
此模式主要用来做开发,因为开发时应用运行频率高,而且对Master故障的影响不大,最主要的是出现故障重新运行便可,不需要恢复。
环境信息
| 主机名 | IP地址 | 操作系统版本 | 安装软件 |
|---|---|---|---|
| spark17 | 172.16.206.17 | CentOS 7.1 | JDK8、scala-2.10.6、spark-1.6.1 |
| spark31 | 172.16.206.31 | CentOS 7.1 | JDK8、scala-2.10.6、spark-1.6.1 |
| spark132 | 172.16.206.32 | CentOS 7.1 | JDK8、scala-2.10.6、spark-1.6.1 |
spark17作为Mater节点,其他两台作为Worker节点。
节点时间同步
采用NTP(Network Time Protocol)方式来实现, 选择一台机器, 作为集群的时间同步服务器, 然后分别配置服务端和集群其他机器。我这里以spark17机器(Hadoop集群机器)时间为准,其他机器同这台机器时间做同步。
NTP服务端
1.安装ntp服务
# yum install ntp -y
2.配置/etc/ntp.conf,这边采用本地机器作为时间的原点
注释server列表:
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
添加如下内容:
server 127.127.1.0 prefer
fudge 127.127.1.0 stratum 8
logfile /var/log/ntp.log
3.启动ntpd服务
# systemctl start ntpd
4.查看ntp服务状态
# systemctl status ntpd
5.加入开机启动
# systemctl enable ntpd
NTP客户端
1.安装ntp
# yum install ntpdate -y
2.配置crontab任务主动同步
# crontab -e
*/10 * * * * /usr/sbin/ntpdate 172.16.206.17;hwclock -w
各节点配置hosts文件
集群各主机都要配置:
# vim /etc/hosts
172.16.206.17 spark17
172.16.206.31 spark31
172.16.206.32 spark32
下载安装JDK8
集群每台机器都要安装JDK8。
# mkdir /usr/java
# tar zxf /usr/local/jdk-8u73-linux-x64.gz -C /usr/java/
# vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_73
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# source /etc/profile
下载安装scala-2.10.6
集群每个节点都需要安装scala。
# cd /usr/local/
# tar zxf scala-2.10.6.tgz
# vim /etc/profile
# Scala environment
export SCALA_HOME=/usr/local/scala-2.10.6
export PATH=$SCALA_HOME/bin:$PATH
# source /etc/profile
查看是否成功:
# scala -version
配置主节点登录自己和其他节点不需要输入密码
生成一对密钥:
[root@spark17 ~]# ssh-keygen -t rsa -P ''
拷贝公钥到自己和其他节点:
[root@spark17 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub root@spark17
[root@spark17 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub root@spark31
[root@spark17 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub root@spark32
安装配置spark
我这里下载的是Spark的编译版本spark-1.6.1-bin-hadoop2.6.tgz,否则需要自己事先自行编译。
先在master机器上(172.16.206.17)安装spark:
[root@spark17 ~]# cd /usr/local/
[root@spark17 local]# tar zxf spark-1.6.1-bin-hadoop2.6.tgz
[root@spark17 local]# mv spark-1.6.1-bin-hadoop2.6 spark-1.6.1
[root@spark17 local]# vim /etc/profile
# Spark environment
export SPARK_HOME=/usr/local/spark-1.6.1
export PATH=$SPARK_HOME/bin:$PATH
[root@spark17 local]# source /etc/profile
配置spark:
修改spark-env.sh文件:
[root@spark17 local]# cd spark-1.6.1/conf/
[root@ spark17 conf]# cp spark-env.sh.template spark-env.sh
[root@ spark17 conf]# vim spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_73
export SCALA_HOME=/usr/local/scala-2.10.6
export SPARK_MASTER_IP=spark17
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORDER_INSTANCES=1
export SPARK_WORKER_MEMORY=4G
修改slave文件:只需要在slave文件中写入各节点的主机名即可,包括master的主机名。
[root@spark17 conf]# cp slaves.template slaves
[root@spark17 conf]# vim slaves

一旦创建好文件, 你就可以使用下面的shell脚本启动或者停止你的集群了。 这些脚本基于Hadoop的发布脚本, 可以在SPARK_HOME/bin找到:
- sbin/start-master.sh:在脚本执行的机器上启动master.
- sbin/start-slaves.sh:启动conf/slaves 文件中配置的所有的slave.
- sbin/start-all.sh:启动上面描述的master和salve.
- sbin/stop-master.sh:停止bin/start-master.sh 脚本启动的master.
- sbin/stop-slaves.sh:停止conf/slaves 文件中配置的slave.
- sbin/stop-all.sh:停止上面描述的master和slave.
【注意】:这些脚本必须在你想运行的master机器上执行,而不是你的本地机。
将master上配置好的spark通过scp复制到其他各个节点上(注意其他节点上的profile文件也要一致)
[root@spark17 ~]# scp -r /usr/local/spark-1.6.1 root@spark31:/usr/local/
[root@spark17 ~]# scp -r /usr/local/spark-1.6.1 root@spark32:/usr/local/
[root@spark31 local]# vim /etc/profile
# Spark environment
export SPARK_HOME=/usr/local/spark-1.6.1
export PATH=$SPARK_HOME/bin:$PATH
[root@spark31 local]# source /etc/profile
启动spark
在master上一次性启动集群:
[root@spark17 ~]# cd /usr/local/spark-1.6.1/sbin/
[root@spark17 sbin]# ./start-all.sh
停止spark
[root@spark17 ~]# cd /usr/local/spark-1.6.1/sbin/
[root@spark17 sbin]# ./stop-all.sh