
I/O类型
从不同的角度来划分,有两种不同的方式:
同步I/O和异步I/O ——synchronous, asynchronous
同步和异步关注的是消息通知机制。说白了就是如何通知调用者的。I/O就是一方能够提供服务,一方需要调用别人的服务,所以I/O请求就是调用方向被调用方请求运行一个应用,通常是一个函数,可以理解成是一个库调用、函数调用或者系统调用。假如是一次系统调用,调用方向被调用方发起一次系统调用请求,被调用方本地要把这个系统调用运行完成,所以要在本地处理处理,把处理的结果响应给调用方。问题是调用方什么时候知道自己的请求结束了呢?自己的请求对方响应了呢?所以这就是同步和异步两种模式。
所谓同步是调用发出之后不会立即返回,但一旦返回,则返回是最终结果;(被调用者一直在处理处理,处理到最后返回结果给调用者)
所谓异步是调用发出之后,被调用方返回消息,但返回的并非最终结果;被调用者通过状态、通知机制(比如打电话通知你)等来通知调用者,或通过回调函数来处理结果。 (当调用者发出请求以后,被调用者立即就告诉调用者了,比如:请求已收到,等着叫号吧。)
阻塞I/O和非阻塞I/O ——block, nonblock
阻塞和非阻塞关注的是调用者等待被调用返回结果时的状态。
阻塞是指调用结果返回之前,调用者(一般是进程或者线程)会被挂起;调用者只有在得到返回结果之后才能继续;
非阻塞是指调用者在结果返回之前,不会被挂起,即调用不会阻塞调用者。
【例子】:你去一个饭馆吃饭去了,点了一碗面,师傅在现做。然后你就在那等着,这期间不能做其他的事情,这就是阻塞。还有一种方案是在等面的时候该干嘛干嘛去,比如出去玩了会游戏等,估摸着面差不多的时候回到饭馆,吃面。这就是非阻塞。
I/O模型
同步、异步和阻塞、非阻塞看起来很像,但是关注的点不同,一个关注着调用者如何等待结果,一个关注着被调用者如何通知调用者调用完成的。所以压根不是一回事。站在这个角度来划分的话,I/O可以分成5种模型:
● 阻塞式I/O(blocking I/O)
● 非阻塞式I/O(nonblocking I/O)
● 复用式I/O(I/O multiplexing)
● 事件驱动式I/O(signal driven I/O)
● 异步I/O(asynchronous I/O)
下面以磁盘I/O来解释,这些概念非常关键。例如,用户程序发起一个I/O调用,如从磁盘上做一次read操作(用户空间的进程是没有权限直接访问文件的,进程向用户内核发起I/O调用,请求说我要读取某数据):
(1)内核从磁盘将数据加载到内核内存空间;
(2)将内核内存中的数据copy一份到进程内存空间。
以上两步中真正被称为I/O的那一步其实只是第(2)步,第(1)步只是内核处理数据的过程。
阻塞式I/O(blocking I/O)
下图中,左侧竖线代表调用者,右侧竖线代表被调用者。整个I/O调用在右侧内核来看,分为两步。如上。所谓阻塞式I/O指的是调用方发起调用后将会被挂起,这个进程或线程将转为不可中断式睡眠状态。调用者在得到返回结果之前,什么事都不能做,一直处于等待过程当中。想象一下,假如是个web服务器,第一个用户请求来了,由一个进程响应用户请求,这个进程向内核发起I/O调用请求,加载用户请求的页面资源,在加载这个页面资源的过程当中,假设它工作于阻塞式I/O的话,它就会被挂起,它显然不能响应用户的其他请求。Apache的prefork并不是工作在阻塞式I/O之下。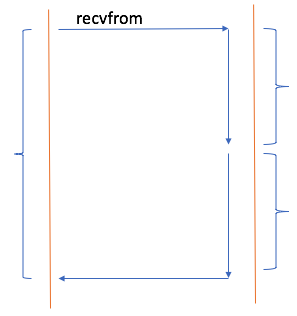
非阻塞式I/O(nonblocking I/O)
左侧是调用者,右侧是被调用者。对于被调用者,依然是两个阶段,数据从磁盘到内核内存,然后数据从内核内存到进程内存。对于非阻塞式I/O,调用者也把这个过程分成两个阶段(左侧也是两个阶段),第1阶段,当调用者发出请求之后,被调用者立即告诉你:请求已收到,你等着吧。但问题是等到什么时候呢?就像去面馆点了一碗面一样,然后你出去玩了,但是你怎么知道面好了呢?为了及时得到吃面,所以你不得不每隔几秒钟回去看看面好了没有。这种就叫做盲等,效率并不高。这种不会直接转为睡眠状态,直到好了告诉你。一旦老板告诉你面OK了,是指面已经在柜台上了,其实是指数据从磁盘到内核内存了,你想吃还得自己从柜台上端过去。所以第二阶段你去端面,在这个过程你是什么事情都是做不了的,所以虽然是非阻塞,第2阶段依然是阻塞的。
所以对于非阻塞式I/O,第一阶段是盲等,第二阶段依然是阻塞的。很显然第二种模式相对第一种模式,性能并没有提升。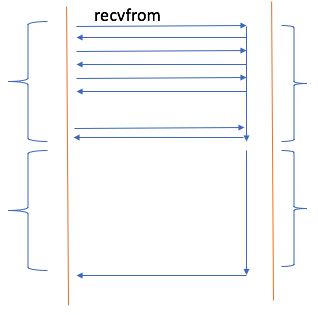
复用式I/O(I/O multiplexing)
任何一个进程,它只能处理一个I/O,因为它一旦被一个I/O阻塞了,直到被唤醒之前,其他人干的事情它一概不知。但作为web服务器进程,它其实是处理两路I/O的,第一路用户通过网络进来,这是网络I/O,第二路是自己向内核发请求加载数据,这是磁盘I/O。这是两路不同的I/O,因此一旦进程被阻塞在磁盘I/O上,如果这个时候网络I/O发生异动了,这个进程是不会知道的。默认情况下,只能处理完一路I/O,在去处理另一路I/O。
再举个例子,比如终端执行一个命令,然后阻塞在磁盘I/O上,你不要了,按了ctrl+c,按道理这个进程处于不可中断睡眠,它应该是不知道的。怎么才能取消。现实中是能取消的,这就是多路I/O(或者说是复用I/O)的工作机制了。
默认情况下,调用者向被调用者发起调用请求时,如果阻塞了,调用者就任何事都做不了,任何信号都处理不了。为了避免这种情况,有人就在内核中开发了复用式I/O的程序,当调用者需要发起I/O调用时,而是内核给调用者准备了个代理人,调用者将请求发给这个代理人,代理人在把这个请求转为内核可以理解的请求,这样一来,调用者就被阻塞在代理人上,而不是阻塞在内核中完成任务的那个事情上。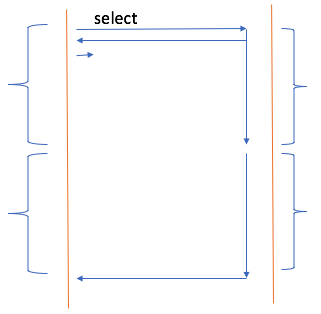
再举个例子,银行很多人在办业务,都在那排队,假如柜台是单进程模型的,在某个时刻只能处理一个业务。这个银行柜台就相当于内核准备的代理人,比如第一个用户想通过这个银行柜台开一张银行卡。向营业员发调用请求,给我开张银行卡,营业员在把请求结果响应给调用者之前,一般而言,这个调用者要一直在柜台坐在那等着。但是也有第二种情况,比如银行业务是两段式的,营业员不直接面对客户,每个营业员配一个助理,这个助理就站在柜台前,负责处理用户请求。所以当任何一个用户请求来了,用户请求扔给助理,助理帮你负责送到内部去。银行柜台有多个,分别办理不同的业务,比如说某个请求既要开张银行卡,又要存款。假设两个业务能同时进行的话,请求者跟助理说我要开张银行卡,于是助理把这个请求扔给一柜台了,自己就闲出来了。然后请求者又扔给助理一个请求,说我要存钱,于是助理又要第二个请求扔给第二个柜台了。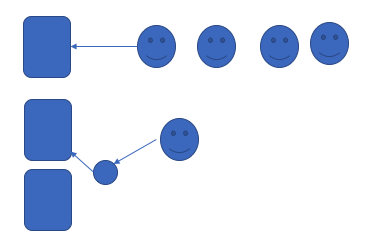
内核的那个代理人就相当于助理,帮我们实现多路I/O。如果没有这个助理,想完成复用是不可能的。这个助理在内核中就是一种特殊的系统调用。早期的内核有个select()调用,就是这种模式。另外一个poll()调用,也是这种模式。select()是由BSD研发的,后来BSD内部吵架,又模仿select()写了个poll()。两者功能是一样的,只不过一个是BSD风格的,一个是SysV风格的。
此后,任何调用者在发起系统调用时,它把调用请求不是扔给内核,而是扔给内核中的助理了。或者说是向内核助理注册一个I/O。select()在实现多路I/O时有限制,要求最多不能超出1024路,如果你想超出,拿内核源码改一改。改成2048,没问题,但是1024的限制是由道理的,因为超出后性能会下降的。我们在讲到prefork模型时,说最多能接受1024个请求并发,其实prefork就是基于select()多路复用I/O模型来实现的。
对于这种复用式I/O,依然是阻塞型的,只不过它不是阻塞在自己真正的那个调用之上,而是阻塞在那个助理上,也是select()或poll()上。
因此两个阶段,第一个阶段数据从磁盘到内核空间,这个阶段调用者是被阻塞的,只不过没阻塞在内核的I/O调用上,而是阻塞在select()或poll()上。select()这个时候还可以接受其他请求。阻塞在select()之上的最大好处就是可以继续接受其他请求,因为它能够接受其他信号进来。但是对于第二阶段来讲,调用者依然是阻塞的。第二阶段是真正的I/O过程,这个时候调用者就不是阻塞在select()之上,而是阻塞在自己真正的调用之上。
复用式I/O对性能并没有提升,最多只是能处理额外的事情而已,并不是在性能上有什么提升。
事件驱动式I/O(signal driven I/O)
调用者发起调用之后,在第一阶段,内核立即返回结果给调用者,告诉调用者:你的请求我已经收到了,你该干嘛干嘛去,一旦我这边完成了,我会通知你。就相当于你去吃面了,老板告诉你面做好了我会打电话通知你的。这不是盲等,你该干嘛干嘛,不需要回来看,过一会老板通知你OK了,你就回来了。回来后,面在柜台上,我们去端面。端面的过程才是真正的I/O过程,这个过程是不能干其他事情的。(也像我们去餐馆,没位置,留了个电话号码,然后出去玩了,等服务员电话。)
这个过程中,第一段是非阻塞的,第二段是阻塞的。作为web服务器来讲,这有什么用呢?一个进程,第一个用户请求来了,进程向内核发起系统调用,加载文件,内核说你该干嘛干嘛去。于是这个进程就闲下来了,这样它就可以处理其它请求了。这就是为什么一个进程可以处理多个请求的原因。但是这个并不意味着性能一定好。虽然已经比阻塞和盲等有优势了,但是它第二段依然是阻塞的。面已经OK了,你仍然得自己端,所以在内核空间数据复制到进程空间这段,仍然是阻塞的。
为什么叫事件驱动呢?因为一旦数据从磁盘到内核空间后,内核会通知调用者。所以调用者本身使用回调函数来处理。
假如第二个请求数据已经准备好了,等着调用者进程将数据从内核空间复制到用户空间,但是假如此时调用者阻塞在第一个请求上,正在复制第一个请求的数据到进程空间,怎么办?内核通知完了在特定时间内你没有接收,这个信号就消失了。怎么办?所以通知与否,怎么通知,这就引入了两种通知机制。
- 第一种:水平触发。通知一次,你没响应,没来处理,内核就再通知一次。没来处理留再通知一次,直到你处理为止。多次通知看上去更可靠,但是浪费资源。(类似老板一直打电话给你,直到你接电话)
- 第二种:边缘触发。只通知一次,但是如果调用者没响应怎么办呢?把通知事件通过回调函数让调用者自行获取,或者把通知信息放置某处,或者过一会儿调用者自己去要。(老板打了一遍电话,你没接,怕面凉了,就端到厨房。过一会你看到未接电话,知道面好了,就回来了,跟老板要。这叫回调。至于什么是回调函数,可以看:https://www.zhihu.com/question/19801131)
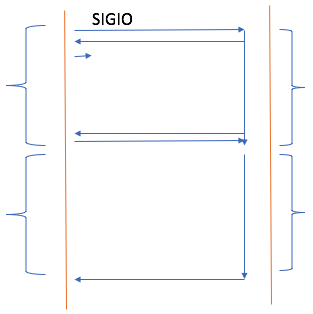
异步I/O(asynchronous I/O)
当调用者向内核发调用,内核说请求已收到,该干嘛干嘛去。于是内核在后台默默地完成第一步,默默地完成第二步。然后才告诉调用者,饭已OK了,过来吃吧。饭都不用你端了,直接由营业员端到你事先定义好的座位上。因此第一个阶段不用阻塞,第二个阶段不用阻塞。
作为一个web服务器来讲,当第一个用户请求进来时,用户请求资源,这个进程向内核发起系统调用,内核自己把数据从磁盘到内核空间,在复制到进程空间,所有东西都准备好了,告诉进程OK了,进程就立即打包响应报文响应给客户端。
httpd的event模型就是事件驱动型I/O,但是据说新版2.4也支持异步I/O。在异步模型下,生产力大大解放。内核从磁盘加载数据到内核内存中,一般都会缓存下来。如果第二个用户请求的资源和前面的用户请求的资源是一样的,直接响应就可以了。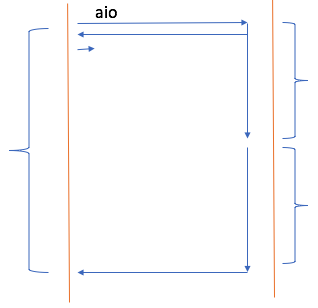
五种I/O模型对比
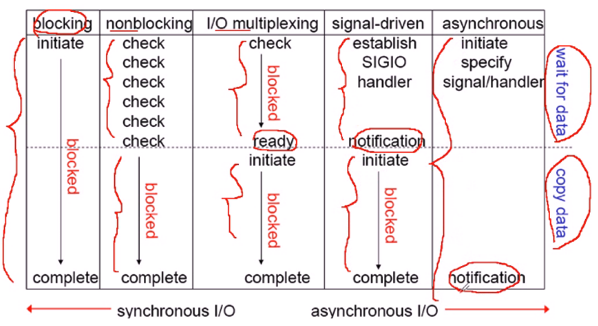
有通知机制的我们称为异步I/O,无通知机制的我们称为同步I/O。见上图最下面,前面3个是同步I/O,后面2个是异步I/O。
Nginx在设计时,用的就是事件驱动型I/O,而且基于边缘触发来实现。Nginx还支持异步I/O。而且还能完成mmap机制,内存映射机制。
Nginx基于File AIO(异步I/O),在文件级别上磁盘I/O上基于异步I/O来实现的;同时对于异步通信,nginx基于事件驱动加上边缘触发来完成一个线程处理多个请求,这对于c10k问题是十分有效的解决方案。
HTTPD的MPM
httpd的MPM(多道处理模块)
● prefork:进程模型的。用的是复用型I/O。
● worker:线程模型的。用的是复用型I/O。并发有限,select()最多1024个。
● event:线程模型的。用的是事件驱动式I/O。
- prefork工作模型
有一个主进程,主进程生成多个子进程,每个子进程处理一个请求。主进程是以管理员的身份启动的,所以它能够监听在80端口上。端口<1024的被称为特权端口,只有管理员才有权限使用的。 - worker工作模型
有一个主进程,主进程生成多个子进程,每个子进程在生成多个线程,每个线程响应一个请求。 - event工作模型
有一个主进程,生成多个子进程,每个子进程响应多个请求。当然你也可以理解有一个主进程,生成多个子线程,对Linux而言,子进程和线程并没有严格意义上的区分。而event模型中最著名的、最典型的特性是事件驱动机制。