
上篇博文中介绍了安装部署OpenResty,这篇博文主要记录下Nginx的配置及优化。
Nginx
Nginx的代码是由一个核心和一系列的模块组成, 核心主要用于提供Web Server的基本功能,以及Web和Mail反向代理的功能;还用于启用网络协议,创建必要的运行时环境以及确保不同的模块之间平滑地进行交互。不过,大多跟协议相关的功能和某应用特有的功能都是由nginx的模块实现的。这些功能模块大致可以分为事件模块、阶段性处理器、输出过滤器、变量处理器、协议、upstream和负载均衡几个类别,这些共同组成了nginx的http功能。事件模块主要用于提供OS独立的(不同操作系统的事件机制有所不同)事件通知机制如kqueue或epoll等。协议模块则负责实现nginx通过http、tls/ssl、smtp、pop3以及imap与对应的客户端建立会话。
Nginx的核心模块为Main和Events,此外还包括标准HTTP模块、可选HTTP模块和邮件模块,其还可以支持诸多第三方模块。Main用于配置错误日志、进程及权限等相关的参数,Events用于配置IO模型,如epoll、kqueue、select或poll等,它们是必备模块。
Nginx的主配置文件由几个段组成,这个段通常也被称为nginx的上下文,每个段的定义格式如下所示。需要注意的是,其每一个指令都必须使用分号(;)结束,否则为语法错误。
<section> {
<directive> <parameters>;
}
配置文件有哪些
1.主配置文件:nginx.conf
2.可以使用include指令引入其他地方的配置文件,比如
include conf.d/*.conf
3.fastcgi的配置文件:
fastcgi_params、uwsgi_params
4.配置指令(必须以分号结尾)
Directive value1 [value2...];
支持使用变量:
内置变量:由模块引入;
自定义变量:
set variable value;
引用变量:$variable
配置文件组织结构
主配置文件结构:
main block
event {
...
}
http {
...
server{
location{
...
}
}
}
mail{
...
}
配置main段
1.user USERNAME [GROUPNAME];
指定用于运行worker进程的用户和组,如果不设置,默认是nobody。比如:
user nginx nginx;
2.pid /PATH/TO/PID_FILE;
指定nginx进程的pid文件路径,也可以使用默认的。比如:
pid /var/run/nginx.pid;
3.error_log
用于配置错误日志,可用于main、http、server及location上下文中;语法格式为:
error_log file | stderr [ debug | info | notice | warn | error | crit | alert | emerg ]
比如:
error_log logs/error.log debug;
4.worker_processes
worker进程是单线程进程。如果Nginx用于CPU密集型的场景中,如SSL或gzip,且主机上的CPU个数至少有2个,那么应该将此参数值设定为与CPU核心数相同;如果负载以IO密集型为主,如响应大量内容给客户端,则worker数应该为CPU个数的1.5或2倍。比如:Nginx所在服务器有2颗CPU,每颗两核,那么可以配置:
worker_processes 4; #启动的work线程数
此参数与Events上下文中的work_connections变量一起决定了maxclient的值:
maxclients = work_processes * work_connections
5.worker_cpu_affinity
通过sched_setaffinity()将worker绑定至CPU上,只能用于main上下文。语法格式为:
worker_cpu_affinity cpumask ...
例如:
worker_processes 4;
worker_cpu_affinity 0001 0010 0100 1000;
6.worker_priority
为worker进程设定优先级(指定nice值),此参数只能用于main上下文中,默认为0;语法格式为:
worker_priority number
7.worker_rlimit_nofile
设定worker进程所能够打开的文件描述符个数的最大值。语法格式:
worker_rlimit_nofile number
配置Events段
1.worker_connections
设定每个worker所处理的最大连接数,它与来自main上下文的worker_processes一起决定了maxclients的值。
nginx作为http服务器的时候:
max_clients = worker_processes * worker_connections
nginx作为反向代理服务器的时候:
max_clients = worker_processes * worker_connections/4
2.use
在有着多于一个的事件模型IO的应用场景中,可以使用此指令设定nginx所使用的IO机制,默认为./configure脚本选定的各机制中最适用当前OS的版本。语法格式:
use [ kqueue | rtsig | epoll | /dev/poll | select | poll | eventport ]
一个配置示例
user nginx;
# the load is CPU-bound and we have 16 cores
worker_processes 16;
error_log logs/error.log debug;
pid logs/nginx.pid;
events {
use epoll;
worker_connections 2048;
}
配置http段
http上下文专用于配置用于http的各模块,此类指令非常的多,每个模块都有其专用指定,具体请参数nginx官方文档关于模块部分的说明。大体上来讲,这些模块所提供的配置指令还可以分为如下几个类别。
- 客户端类指令:如client_body_buffer_size、client_header_buffer_size、client_header_timeout和keepalive_timeout等;
- 文件IO类指令:如aio、directio、open_file_cache、open_file_cache_min_uses、open_file_cache_valid和sendfile等;
- hash类指令:用于定义Nginx为某特定的变量分配多大的内存空间,如types_hash_bucket_size、server_names_hash_bucket_size和variables_hash_bucket_size等;
- 套接字类指令:用于定义Nginx如何处理tcp套接字相关的功能,如tcp_nodelay(用于keepalive功能启用时)和tcp_nopush(用于sendfile启用时)等;
套接字或主机相关配置
server {
<directive> <parameters>;
}
用于定义虚拟主机相关的属性。比如:
server {
listen PORT; #listen指令监听在不同的端口;
server_name NAME; #server_name指令指向不同的主机名;
root /PATH/TO/DOCUMENTROOT;
}
1.listen
listen address[:port] [default_server] [ssl] [http2 | spdy]
listen port [default_server] [ssl] [http2 | spdy]
- default_server:设置默认虚拟主机;用于基于IP地址,或使用了任意不能对应于任何一个server的name时所返回站点;
- ssl:用于限制只能通过ssl连接提供服务;
- spdy:SPDY protocol(speedy),在编译了spdy模块的情况下,用于支持SPDY协议;
- http2:http version 2;
2.server_name NAME […];
后可跟一个或多个主机名;名称还可以使用通配符和正则表达式(~);
- 首先做精确匹配;例如:www.wisedu.com
- 左侧通配符;例如:*.wisedu.com
- 右侧通配符,例如:www.wisedu.*
- 正则表达式,例如:~^.*.wisedu.com$
- default_server
3.tcp_nodelay on|off;
Syntax: tcp_nodelay on | off;
Default: tcp_nodelay on;
Context: http, server, location
对keepalive模式下的连接是否使用TCP_NODELAY选项;
4.tcp_nopush on|off;
Syntax: tcp_nopush on | off;
Default: tcp_nopush off;
Context: http, server, location
是否启用TCP_NOPUSH(FREEBSE)或TCP_CORK(Linux)选项;仅在sendfile为on时有用;
tcp_nopush和tcp_nodelay选项:
先来了解下Nagle算法:
在网络拥塞控制领域,有一个非常有名的算法叫做Nagle算法(Nagle algorithm),这是使用它的发明人John Nagle的名字来命名的,John Nagle在1984年首次用这个算法来尝试解决福特汽车公司的网络拥塞问题(RFC 896),该问题的具体描述是:如果我们的应用程序一次产生1个字节的数据,而这个1个字节数据又以网络数据包的形式发送到远端服务器,那么就很容易导致网络由于太多的数据包而过载。比如,当用户使用Telnet连接到远程服务器时,每一次击键操作就会产生1个字节数据,进而发送出去一个数据包,所以,在典型情况下,传送一个只拥有1个字节有效数据的数据包,却要发费40个字节长包头(即ip头20字节+tcp头20字节)的额外开销,这种有效载荷(payload)利用率极其低下的情况被统称之为愚蠢窗口症候群(Silly Window Syndrome)。可以看到,这种情况对于轻负载的网络来说,可能还可以接受,但是对于重负载的网络而言,就极有可能承载不了而轻易的发生拥塞瘫痪。
针对上面提到的这个状况,Nagle算法的改进在于:如果发送端欲多次发送包含少量字符的数据包(一般情况下,后面统一称长度小于MSS的数据包为小包,与此相对,称长度等于MSS的数据包为大包,为了某些对比说明,还有中包,即长度比小包长,但又不足一个MSS的包),则发送端会先将第一个小包发送出去,而将后面到达的少量字符数据都缓存起来而不立即发送,直到收到接收端对前一个数据包报文段的ACK确认、或当前字符属于紧急数据,或者积攒到了一定数量的数据(比如缓存的字符数据已经达到数据包报文段的最大长度)等多种情况才将其组成一个较大的数据包发送出去。
TCP中的Nagle算法默认是启用的,但是它并不是适合任何情况,对于telnet或rlogin这样的远程登录应用的确比较适合(原本就是为此而设计),但是在某些应用场景下我们却又需要关闭它。
Nagle算法是指发送方发送的数据不会立即发出, 而是先放在缓冲区, 等缓存区满了再发出。发送完一批数据后, 会等待接收方对这批数据的回应, 然后再发送下一批数据。Negale 算法适用于发送方需要发送大批量数据, 并且接收方会及时作出回应的场合, 这种算法通过减少传输数据的次数来提高通信效率。如果发送方持续地发送小批量的数据, 并且接收方不一定会立即发送响应数据, 那么Negale算法会使发送方运行很慢. 对于GUI 程序, 如网络游戏程序(服务器需要实时跟踪客户端鼠标的移动), 这个问题尤其突出。客户端鼠标位置改动的信息需要实时发送到服务器上, 由于Negale 算法采用缓冲, 大大减低了实时响应速度, 导致客户程序运行很慢。这个时候就需要使用TCP_NODELAY选项。
tcp_nopush
官方:
tcp_nopush
Syntax: tcp_nopush on | off
Default: off
Context: http, server, location
Reference: tcp_nopush
This directive permits or forbids the use of thesocket options TCP_NOPUSH on FreeBSD or TCP_CORK on Linux. This option is onlyavailable when using sendfile.
Setting this option causes nginx to attempt to sendit’s HTTP response headers in one packet on Linux and FreeBSD 4.x
You can read more about the TCP_NOPUSH and TCP_CORKsocket options here.
linux 下是tcp_cork,上面的意思就是说,当使用sendfile函数时,tcp_nopush才起作用,它和指令tcp_nodelay是互斥的。tcp_cork是linux下tcp/ip传输的一个标准了,这个标准的大概的意思是,一般情况下,在tcp交互的过程中,当应用程序接收到数据包后马上传送出去,不等待,而tcp_cork选项是数据包不会马上传送出去,等到数据包最大时,一次性的传输出去,这样有助于解决网络堵塞。
也就是说tcp_nopush = on 会设置调用tcp_cork方法,这个也是默认的,结果就是数据包不会马上传送出去,等到数据包最大时,一次性的传输出去,这样有助于解决网络堵塞。
以快递投递举例说明一下(以下是我的理解,也许是不正确的),当快递东西时,快递员收到一个包裹,马上投递,这样保证了即时性,但是会耗费大量的人力物力,在网络上表现就是会引起网络堵塞,而当快递收到一个包裹,把包裹放到集散地,等一定数量后统一投递,这样就是tcp_cork的选项干的事情,这样的话,会最大化的利用网络资源,虽然有一点点延迟。
对于nginx配置文件中的tcp_nopush,tcp_nopush on;这个选项对于www,ftp等大文件很有帮助。
tcp_nodelay
TCP_NODELAY和TCP_CORK基本上控制了包的“Nagle化”,Nagle化在这里的含义是采用Nagle算法把较小的包组装为更大的帧。 John Nagle是Nagle算法的发明人,后者就是用他的名字来命名的,他在1984年首次用这种方法来尝试解决福特汽车公司的网络拥塞问题(欲了解详情请参看IETF RFC 896)。他解决的问题就是所谓的silly window syndrome,中文称“愚蠢窗口症候群”,具体含义是,因为普遍终端应用程序每产生一次击键操作就会发送一个包,而典型情况下一个包会拥有一个字节的数据载荷以及40个字节长的包头,于是产生4000%的过载,很轻易地就能令网络发生拥塞,。 Nagle化后来成了一种标准并且立即在因特网上得以实现。它现在已经成为缺省配置了,但在我们看来,有些场合下把这一选项关掉也是合乎需要的。
现在让我们假设某个应用程序发出了一个请求,希望发送小块数据。我们可以选择立即发送数据或者等待产生更多的数据然后再一次发送两种策略。如果我们马上发送数据,那么交互性的以及客户/服务器型的应用程序将极大地受益。如果请求立即发出那么响应时间也会快一些。以上操作可以通过设置套接字的TCP_NODELAY = on 选项来完成,这样就禁用了Nagle 算法。
另外一种情况则需要我们等到数据量达到最大时才通过网络一次发送全部数据,这种数据传输方式有益于大量数据的通信性能,典型的应用就是文件服务器。应用 Nagle算法在这种情况下就会产生问题。但是,如果你正在发送大量数据,你可以设置TCP_CORK选项禁用Nagle化,其方式正好同 TCP_NODELAY相反(TCP_CORK和 TCP_NODELAY是互相排斥的)。
5.sendfile on|off;
是否启用sendfile功能;
先来看下nginx作为web服务器的工作方式:
用户请求进来了,先到达网卡,由内核处理下交给了监听在80套接字上的应用程序,即交给worker进程,这个worker进程通过连接建立、通过接入分析发现用户请求的是一个静态页面,下面就是I/O了。首先进程向内核发出系统调用。内核为它准备一个缓冲,然后内核从磁盘中加载这个文件到缓冲中,然后将这个文件复制给worker进程自己的地址空间,然后进程将这个文件封装成响应报文,这个封装过程是,进程封装http请求首部,然后交给内核封装TCP首部、IP首部,然后交给客户端。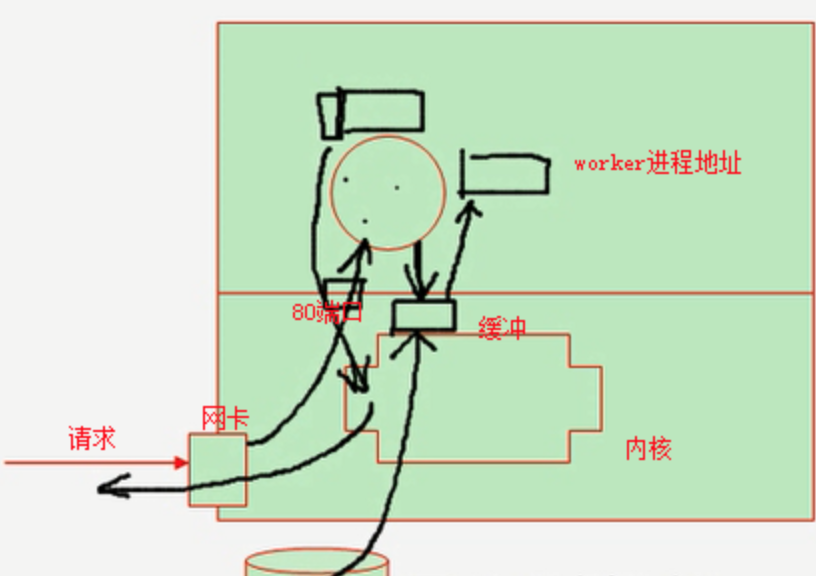
然后你会发现这个文件是这么走的:从硬盘到内核空间,从内核到用户空间,从用户空间再到内核空间,白白绕一圈。如果说这个请求直接在内核中就封装好(http请求首部封装其实也是在内核封装的),这样就避免了两次复制(注意是复制,内核任何时候和进程交互都是复制,除非共享内存)。复制虽然时间短,但是架不住多啊。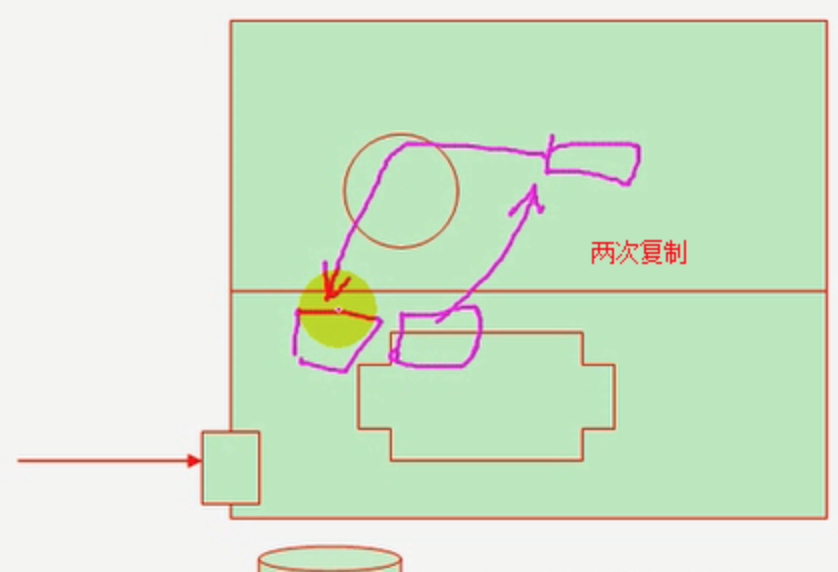
这就是sendfile机制,读过来就响应了。send只支持很小的文件,sendfile64支持更大的文件。
现在流行的web 服务器里面都提供 sendfile 选项用来提高服务器性能,那到底 sendfile是什么,怎么影响性能的呢?
sendfile实际上是 Linux2.0+以后的推出的一个系统调用,web服务器可以通过调整自身的配置来决定是否利用sendfile这个系统调用。先来看一下不用 sendfile的传统网络传输过程:
read(file,tmp_buf, len);
write(socket,tmp_buf, len);
硬盘 >> kernel buffer >> user buffer>> kernel socket buffer >>协议栈
一般来说一个网络应用是通过读硬盘数据,然后写数据到socket 来完成网络传输的。上面2行用代码解释了这一点,不过上面2行简单的代码掩盖了底层的很多操作。来看看底层是怎么执行上面2行代码的:
- ①系统调用 read()产生一个上下文切换:从 user mode 切换到 kernel mode,然后 DMA 执行拷贝,把文件数据从硬盘读到一个 kernel buffer 里。
- ②数据从 kernel buffer拷贝到 user buffer,然后系统调用 read() 返回,这时又产生一个上下文切换:从kernel mode 切换到 user mode。
- ③系统调用write()产生一个上下文切换:从 user mode切换到 kernel mode,然后把步骤2读到 user buffer的数据拷贝到 kernel buffer(数据第2次拷贝到 kernel buffer),不过这次是个不同的 kernel buffer,这个 buffer和 socket相关联。
④系统调用 write()返回,产生一个上下文切换:从 kernel mode 切换到 user mode(第4次切换了),然后 DMA 从 kernel buffer拷贝数据到协议栈(第4次拷贝了)。
上面4个步骤有4次上下文切换,有4次拷贝,我们发现如果能减少切换次数和拷贝次数将会有效提升性能。在kernel2.0+ 版本中,系统调用 sendfile() 就是用来简化上面步骤提升性能的。sendfile() 不但能减少切换次数而且还能减少拷贝次数。
再来看一下用 sendfile() 来进行网络传输的过程:sendfile(socket,file, len);
硬盘 >> kernel buffer (快速拷贝到kernel socket buffer) >>协议栈①系统调用sendfile()通过 DMA把硬盘数据拷贝到 kernel buffer,然后数据被 kernel直接拷贝到另外一个与 socket相关的 kernel buffer。这里没有 user mode和 kernel mode之间的切换,在 kernel中直接完成了从一个 buffer到另一个buffer的拷贝。
- ②DMA 把数据从 kernelbuffer 直接拷贝给协议栈,没有切换,也不需要数据从 user mode 拷贝到 kernel mode,因为数据就在 kernel 里。
步骤减少了,切换减少了,拷贝减少了,自然性能就提升了。这就是为什么说在 Nginx 配置文件里打开 sendfile on 选项能提高 web server性能的原因。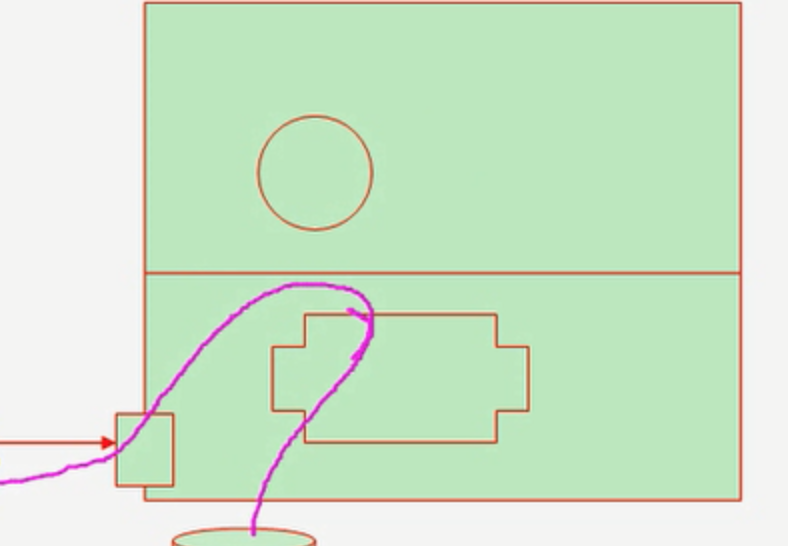
4.gzip on;
对于响应用户的内容是不是先压缩再发送,可以节省带宽。如果网络带宽小,用户访问量大的话可以使用这种方式。
路径相关的指令
1.root
设置web资源的路径映射;用于指明请求的URL所对应的文档的目录路径;
server {
...
root /data/www/vhost1;
}
http://www.wisedu.com/images/logo.jpg --> /data/www/vhosts/images/logo.jpg
server {
...
server_name www.wisedu.com;
location /images/ {
root /data/imgs/;
...
}
}
http://www.wisedu.com/images/logo.jpg --> /data/imgs/images/logo.jpg
2.location [ = | ~ | ~* | ^~ ] uri { … }
location @name { … }
功能:允许根据用户请求的URI来匹配定义的各location,匹配到时,此请求将被相应的location块中的配置所处理;简言之,即用于为需要用到专用配置的uri提供特定配置。
先来看下location [ = | ~ | ~* | ^~ ] uri { … }
- location URI{}:对当前路径及所有对象都生效。
- location = URI{}:只对当前路径生效,不包括子路径。这是精确匹配。
- location ~ URI{}:
- location
~*URI{}:模式匹配URI,此处的URI可使用正则表达式,~区分字符大小写。~*不区分字符大小写。 - location ^~ URI{}:明确说明不使用正则表达式。
【注意】:如果被两个location匹配到,nginx是有优先级的。=优先级最高,^~优先级第二,模式匹配优先级第三,没加任何符号的优先级最低。
官方例子:http://nginx.org/en/docs/http/ngx_http_core_module.html#location
location = / {
[ configuration A ]
}
location / {
[ configuration B ]
}
location /documents/ {
[ configuration C ]
}
location ^~ /images/ {
[ configuration D ]
}
location ~* \.(gif|jpg|jpeg)$ {
[ configuration E ]
}
The “/” request will match configuration A, the “/index.html” request will match configuration B, the “/documents/document.html” request will match configuration C, the “/images/1.gif” request will match configuration D, and the “/documents/1.jpg” request will match configuration E.
补充一个,
location / {
[ configuration A ]
}
location /abc {
[ configuration B ]
}
访问 http://ip:port/abc 将被 location /abc 匹配到。
再来看下location @name { … },命名的location
The “@” prefix defines a named location. Such a location is not used for a regular request processing, but instead used for request redirection. They cannot be nested, and cannot contain nested locations.
@:内部服务跳转
server {
location /img/ {
set $memcached_key $uri;
memcached_pass name:11211;
default_type text/html;
error_page 404 @fallback; #以 /img/ 开头的请求,如果连接的状态为 404。则会匹配到 @fallback 这条规则上。
}
location @fallback {
proxy_pass http://backend;
}
}
3.alias
定义路径别名。
location /images/ {
root /data/imgs/;
}
location /images/ {
alias /data/imgs/;
}
访问/images/test.jpg,对应的结果如下:
- root指令:给定的路径对应于location的“/”这个URL;
/images/test.jpg –> /data/imgs/images/test.jpg - alias指令:给定的路径对应于location的“/uri/“这个URL;
/images/test.jpg –> /data/imgs/test.jpg,注意alias把location后配置的路径images丢弃掉了。
【注意】:
- 使用alias时,目录名后面一定要加”/“。
- alias在使用正则匹配时,必须捕捉要匹配的内容并在指定的内容处使用。
- alias只能位于location块中。(root可以不放在location中)
4.index
index file ...;
设置默认主页面。
5.error_page code … [=[response]] uri;
根据http的状态码重定向错误页面;
error_page 404 /404.html
error_page 404 =200 /404.html (以指定的响应状态码进行响应)
6.try_files file … uri;
try_files file … =code;
其作用是按顺序检查文件是否存在,尝试查找第1至第N-1个文件,返回第一个找到的文件或文件夹(结尾加斜线表示为文件夹),如果所有的文件或文件夹都找不到,会进行一个内部重定向到最后一个参数。(必须不能匹配至当前location,而应该匹配至其它location,否则会导致死循环)。
location / {
try_files $uri $uri/ @fallback; # $uri为Nginx内置变量,下面会讲到。
root /home/data/FS/desgin_style/;
}
location @fallback {
proxy_pass_header Server;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Scheme $scheme;
proxy_pass http://backend;
}
客户端请求相关的配置
1.keepalive_timeout timeout [header_timeout];
设定keepalive连接的超时时长;0表示禁止长连接;默认为75s。
KeepAlive,意思为是否长连接。如果设置了超时时间,那么在这个时间内,那么当Nginx完成用户的请求后,那么Nginx进程不会断开用户的请求连接,依然保持连接状态。设置成0s则当Nginx完成用户的请求后,那么Nginx进程会立即断开和用户的请求连接。
完成用户的请求后,连接依然存在着,这样的好处是:当该用户的请求在过来时,Nginx会用这个已经建立的连接,不需要重新创建连接。这样会节省CPU的资源。但是却耗费了内存。为什么呢?可以假设这样的场景。假如keepalive 超时时间为10s,而每1s中有100个用户请求访问,每个用户3次连接,每个连接耗费2M内存,那么10s内建立的连接次数为1000次(跟用户每s请求次数无关),消耗内存为1000x2=2000M,相反,如果不保持长连接,同样的环境场景下,每1s内有100x3个连接,下一秒还是100x3个连接,也就是说永远都是100x3个连接,那么1s内甚至10s内消耗的内存为100x3x2=600M。 然而,在这10s内创建的连接次数100x3x10=3000次,这样肯定消耗了更多的cpu资源。毕竟每次tcp连接都是需要cpu去处理的。
问题来了,既然知道长连接与否的利与弊,那么如何判定什么时候On,什么时候Off?
在上面的举例中,涉及到了一个数,那就是每个用户在1s内请求的次数,如果把3改为1,是不是10s内得到的连接次数总和是一样的。那么这样无论是On还是Off,消耗的CPU资源是一样的。所以,我们考虑3种情况:
- ①用户浏览一个网页时,除了网页本身外,还引用了多个 javascript 文件,多个 css 文件,多个图片文件,并且这些文件都在同一个 HTTP 服务器上。
- ②用户浏览一个网页时,除了网页本身外,还引用一个 javascript 文件,一个图片文件。
- ③用户浏览的是一个动态网页,由程序即时生成内容,并且不引用其他内容。
对于上面3中情况,我认为:1 最适合打开 KeepAlive ,2 随意,3 最适合关闭 KeepAlive(连接消耗的内存比较大)
总结一下:
在内存非常充足的服务器上,不管是否关闭 KeepAlive 功能,服务器性能不会有明显变化;
如果服务器内存较少,或者服务器有非常大量的文件系统访问时,或者主要处理动态网页服务,关闭 KeepAlive 后可以节省很多内存,而节省出来的内存用于文件系统Cache,可以提高文件系统访问的性能,并且系统会更加稳定。
目前的服务器,CPU很强,所以不用考虑频繁的tcp连接对cpu造成的压力,那还让它长连接干什么,故,建议关闭你的长连接吧!!!
PS: 如果,你的服务器上请求量很大,那你最好还是关闭这个参数吧。我试过一次,打开长连接,并且设置超时时间为30s,结果仅仅十几s就把所有的Nginx进程跑满。这样很危险的,直接让用户等待,等30s,这不扯淡嘛?即使是你设置成3s,照样会让用户等待3s,这样很不合理的。所以,归根结蒂还是关闭长连接吧,这样效率会更高。
举个网上的具体例子:
- 1.项目环境:nginx(前段代理,仅作代理用途)+3个tomcat(都在同一个服务器上),做的web项目
- 2.涉及到的业务逻辑:文件上传(可能有大文件,比如说android游戏,100m);客户端接口请求;网站后台管理
- 3.问题重现流程:
- 3.1 配置好tomcat后,直接加上nginx前段代理(仅配置了http代理)
- 3.2 问题一:当管理员后台上传文件时,大文件无法上传成功,出现time-out,经重复测试,发现上传时间超过1分钟以后,就会返回超时信息,小文件没有问题
- 3.3 经调研得知nginx默认设置的http连接超时时间为75s,超过75s,会断掉当前的http连接,而大文件上传时经常会超过75s,这就导致大文件无法上传成功,当时的解决方案是,设置nginx http连接超时时间为30分钟,即参数keepalive_timeout=1800;文件上传问题基本解决;
- 3.4项目运行2天后,发现服务器突然宕机了,重启nginx可以解决问题,但是2个小时后又再次宕机,重启nginx又解决了问题,调研了一个中午,并且查看nginx的错误日志(socket() failed (24: Too many open files) while connecting to upstream),发现问题来源与nginx的连接数(设置的默认值为1024)达到上限
- 3.5发现这个问题后,我就想应该把nginx的连接数调大点,于是设置 worker_connections 10240;重启nginx,短时间没有出现问题,但是运行过程中,我再次查看错误日志,发现(socket() failed (24: Too many open files) while connecting to upstream)时不时的出现
- 3.6 此时发现调整nginx的连接数并不能完全解决问题,于是google,百度之,发现问题所在,罪魁祸首是:nginx的keepalive_timeout(参看http://fengzheng369.blog.163.com/blog/static/752209792012418103813580/ )设置项时间太长,客户端接口访问其实是一个比较快速的过程,访问完成了已经不需要继续使用http连接了,但是由于对nginx的错误配置,导致接口访问完成后http连接并没有被释放掉,所以导致连接数越来越大,最终nginx崩溃。
- 4.那么这个问题应该如何解决呢?
将keepalive_timeout时间调小会导致上传操作可能无法完成;调大点的话,许多无效的http连接占据着nginx的连接数。这貌似是一个两难的问题。
解决方案一:将接口请求,后台管理,文件上传这三个业务逻辑分开,nginx对这三种业务逻辑分开转发,每个业务逻辑单独设置一个keepalive-timeout(未实验)。
2.keepalive_requests number;
在keepalived连接上所允许请求的最大资源数量;默认为100;
3.keepalive_disable none | browser …;
指明禁止为何种浏览器使用keepalive功能;
4.send_timeout #;
发送响应报文的超时时长,默认为60s;
5.client_body_buffer_size size;
接收客户请求报文body的缓冲区大小;默认为16k;超出此指定大小时,其将被移存于磁盘上;
6.client_body_temp_path path [level1 [level2 [level3]]];
设定用于存储客户端请求body的临时存储路径及子目录结构和数量;
client_body_temp_path /var/tmp/client_body 2 2;
7.client_max_body_size 10m;
允许客户端请求的最大的单个文件字节数,这个参数可以限制body的大小,默认是1m。如果上传的文件较大,那么需要调大这个参数。
对客户端请求的进行限制
1.limit_excpet METHOD {…}
对指定范围之外的其它的方法进行访问控制;
limit_except GET {
allow 172.16.0.0/16;
deny all;
}
2.对客户端限速
我们经常会遇到这种情况,服务器流量异常,负载过大等等。对于大流量恶意的攻击访问,会带来带宽的浪费,服务器压力,影响业务,往往考虑对同一个ip的连接数,并发数进行限制。下面说说ngx_http_limit_conn_module 模块来实现该需求。该模块可以根据定义的键来限制每个键值的连接数,如同一个IP来源的连接数。并不是所有的连接都会被该模块计数,只有那些正在被处理的请求(这些请求的头信息已被完全读入)所在的连接才会被计数。
nginx的限速功能通过limit_zone、limit_conn和limit_rate指令进行配置。首先需要在http上下文配置一个limit_zone,然后在需要的地方使用limit_conn和limit_rate 进行限速设置。
limit_conn_zone
语法: limit_conn_zone $variable zone=name:size;
默认值: none
配置段: http
该指令描述会话状态存储区域。键的状态中保存了当前连接数,键的值可以是特定变量的任何非空值(空值将不会被考虑)。$variable定义键,zone=name定义区域名称,后面的limit_conn指令会用到的。size定义各个键共享内存空间大小。如:
limit_conn_zone $binary_remote_addr zone=addr:10m;
【说明】:
- 客户端的IP地址作为键。注意,这里使用的是$binary_remote_addr变量,而不是$remote_addr变量。
- $remote_addr变量的长度为7字节到15字节,而存储状态在32位平台中占用32字节或64字节,在64位平台中占用64字节。
- $binary_remote_addr变量的长度是固定的4字节,存储状态在32位平台中占用32字节或64字节,在64位平台中占用64字节。
- 1M共享空间可以保存3.2万个32位的状态,1.6万个64位的状态。如果共享内存空间被耗尽,服务器将会对后续所有的请求返回 503 (Service Temporarily Unavailable) 错误。
- limit_zone 指令和limit_conn_zone指令同等意思,已经被弃用,就不再做说明了。
limit_conn
语法:limit_conn zone_name number
默认值:none
配置段:http, server, location
指定每个给定键值的最大同时连接数,当超过这个数字时被返回503 (Service Temporarily Unavailable)错误。如:
limit_conn_zone $binary_remote_addr zone=addr:10m;
server {
location /www.ttlsa.com/ {
limit_conn addr 1;
}
}
同一IP同一时间只允许有一个连接。
当多个 limit_conn 指令被配置时,所有的连接数限制都会生效。比如,下面配置不仅会限制单一IP来源的连接数,同时也会限制单一虚拟服务器的总连接数:
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn_zone $server_name zone=perserver:10m;
server {
limit_conn perip 10;
limit_conn perserver 100;
}
limit_rate
语法:limit_rate rate
默认值:0
配置段:http, server, location, if in location
对每个连接的速率限制。参数rate的单位是字节/秒,设置为0将关闭限速。 按连接限速而不是按IP限制,因此如果某个客户端同时开启了两个连接,那么客户端的整体速率是这条指令设置值的2倍。
Nginx反向代理配置
Nginx通过proxy模块实现反向代理功能。在作为web反向代理服务器时,nginx负责接收客户请求,并能够根据URI、客户端参数或其它的处理逻辑将用户请求调度至上游服务器上(upstream server)。nginx在实现反向代理功能时的最重要指令为proxy_pass,它能够将location定义的某URI代理至指定的上游服务器(组)上。如下面的示例中,location的/uri将被替换为上游服务器上的/newuri。
location /uri {
proxy_pass http://www.magedu.com:8080/newuri; # 指定将请求代理至upstream server的URL路径;
}
补充:上游,有发源的意思。故上游服务器指的产生内容的服务器。
不过,这种处理机制中有两个例外。一个是如果location的URI是通过模式匹配定义的,其URI将直接被传递至上游服务器,而不能为其指定转换的另一个URI。例如下面示例中的/forum将被代理为http://www.magedu.com/forum。
location ~ ^/bbs {
proxy_pass http://www.magedu.com;
}
第二个例外是,如果在loation中使用的URL重定向,那么nginx将使用重定向后的URI处理请求,而不再考虑上游服务器上定义的URI。如下面所示的例子中,传送给上游服务器的URI为/index.php?page=
location / {
rewrite /(.*)$ /index.php?page=$1 break;
proxy_pass http://localhost:8080/index;
}
proxy模块的指令
proxy模块的可用配置指令非常多,它们分别用于定义proxy模块工作时的诸多属性,如连接超时时长、代理时使用http协议版本等。下面对常用的指令做一个简单说明。
- proxy_connect_timeout:nginx将一个请求发送至upstream server之前等待的最大时长;
- proxy_cookie_domain:将upstream server通过Set-Cookie首部设定的domain属性修改为指定的值,其值可以为一个字符串、正则表达式的模式或一个引用的变量;
- proxy_cookie_path: 将upstream server通过Set-Cookie首部设定的path属性修改为指定的值,其值可以为一个字符串、正则表达式的模式或一个引用的变量;
- proxy_hide_header:设定发送给客户端的报文中需要隐藏的首部;
- proxy_pass:指定将请求代理至upstream server的URL路径;
- proxy_set_header:将发送至upsream server的报文的某首部进行重写;
- proxy_redirect:重写location并刷新从upstream server收到的报文的首部;
- proxy_send_timeout:在连接断开之前两次发送至upstream server的写操作的最大间隔时长;
- proxy_read_timeout:在连接断开之前两次从接收upstream server接收读操作的最大间隔时长;
如下面的一个示例:
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
client_max_body_size 10m;
client_body_buffer_size 128k;
proxy_connect_timeout 30;
proxy_send_timeout 15;
proxy_read_timeout 15;
nginx proxy_pass 后面的url 加与不加/的区别:
在nginx中配置proxy_pass时,当在后面的url加上了/,相当于是绝对根路径,则nginx不会把location中匹配的路径部分代理走;如果没有/,则会把匹配的路径部分也给代理走。
下面四种情况分别用http://192.168.1.4/proxy/test.html 进行访问。
第一种:
location /proxy/ {
proxy_pass http://127.0.0.1:81/;
}
会被代理到http://127.0.0.1:81/test.html 这个url
第二种(相对于第一种,最后少一个 /)
location /proxy/ {
proxy_pass http://127.0.0.1:81;
}
会被代理到http://127.0.0.1:81/proxy/test.html 这个url
第三种:
location /proxy/ {
proxy_pass http://127.0.0.1:81/ftlynx/;
}
会被代理到http://127.0.0.1:81/ftlynx/test.html 这个url。
第四种情况(相对于第三种,最后少一个 / ):
location /proxy/ {
proxy_pass http://127.0.0.1:81/ftlynx;
}
会被代理到http://127.0.0.1:81/ftlynxtest.html 这个url
location后加/和不加/的区别
首先是location进行的是模糊匹配
- 没有“/”时,location /abc/def可以匹配/abc/defghi请求,也可以匹配/abc/def/ghi等
- 而有“/”时,location /abc/def/不能匹配/abc/defghi请求,只能匹配/abc/def/anything这样的请求
Nginx实现负载均衡 –upstream模块
与proxy模块结合使用的模块中,最常用的当属upstream模块。upstream模块可定义一个新的上下文,它包含了一组服务器,这些服务器可能被赋予了不同的权重、不同的类型甚至可以基于维护等原因被标记为down。直白点就是说如果后端一个服务器是在抗不住了,nginx还可以代理用户请求至多个服务器,也就是一个location里定义多个服务器,即实现负载均衡的效果。还能检查后端server的健康状况。
例如:
upstream backend {
server 172.16.7.151:8080 weight=5;
server 172.16.7.152:8090 weight=3;
}
server {
listen 80;
server_name www.wisedu.com;
location / {
proxy_pass http://backend;
}
}
server也可以使用域名,但是需要内网有DNS服务器,或者在hosts文件做解析。也可以是IP:port。
upstream模块定义在http段,可以定义多个upstream,但是每一个都要有自己独立的名称。
upstream模块常用的指令有:
- ip_hash:基于客户端IP地址完成请求的分发,它可以保证来自于同一个客户端的请求始终被转发至同一个upstream服务器;
upstream lb { ip_hash; server 172.16.7.151:8080; server 172.16.7.152:8090; } - keepalive:每个worker进程为发送到upstream服务器的连接所缓存的个数;
- least_conn:最少连接调度算法;检查后端的连接状况,挑一个当前连接数最少的来负责响应。
- server:定义一个upstream服务器的地址,还可包括一系列可选参数,如:
- weight:权重;
- max_fails:最大失败连接次数,失败连接的超时时长由fail_timeout指定;
- fail_timeout:等待请求的目标服务器发送响应的时长;
- backup:用于fallback的目的,所有服务均故障时才启动此服务器;
- down:手动标记其不再处理任何请求;
upstream模块的负载均衡算法主要有三种,轮调(round-robin)、ip哈希(ip_hash)和最少连接(least_conn)三种。默认是轮调算法。
健康状况检查
如果某台机器挂了怎么办?可以进行健康状况检查。
upstream webserv {
server 172.16.7.151:8080 weight=1 max_fails=2 fail_timeout=2;
server 172.16.7.152:8090 weight=1 max_fails=2 fail_timeout=2;
}
健康状况检查还应该有一个功能,万一所有服务器都宕掉怎么办?必须要有个Sorry-Server,下面以本机作为Sorry-Server,可以在定义个虚拟主机:
server {
listen 8080;
server_name localhost;
root /web/errorpages;
index index.html
}
upstream添加配置:
upstream webserv {
server 172.16.7.151:8080 weight=1 max_fails=2 fail_timeout=2;
server 172.16.7.152:8090 weight=1 max_fails=2 fail_timeout=2;
server 127.0.0.1:8080 backup;
}
backup: 其它所有的非backup机器down或者忙的时候,请求backup机器。所以这台机器压力会最轻。
Nginx的URL重写功能和if指令
URL重写rewrite
1.什么叫rewrite
举个例子:
location /images/ { ——这是我们当前服务器上的目录
rewrite http://172.16.2.27/images/; ——把你转到另外一台服务器上的目录去了。
}
2.Nginx的rewrite
Nginx的rewrite支持正则表达式 ——可以将一类URL转成另一类URL
Syntax: rewrite regex replacement [flag];
Default: —
Context: server, location, if
server区块中如果有包含rewrite规则,则会最先执行,而且只会执行一次, 然后再判断命中哪个location的配置。如果location中也配置了rewrite,会再去执行该location中的rewrite,当该location中的rewrite执行完毕时,rewrite并不会停止,而是根据rewrite过的URL再次判断location并执行其中的配置。那么,这里就存在一个问题,如果rewrite写的不正确的话,是会在location区块间造成无限循环的。所以nginx才会加一个最多重试10次的上限。比如:
location / {
root html;
index index.html index.htm;
rewrite ^/bbs/(.*)$ /forum/$1
}
flag:支持4种标志。
- last:本次重写完成之后重启下一轮检查。一般场景下用的都是last。
- break:本次重写完成之后不启用下一轮检查,直接响应。
- redirect:返回302临时重定向,地址栏会显示跳转后的地址
- permanent: 返回301永久重定向,地址栏会显示跳转后的地址
测验一下break与last的区别:
location /test1.txt/ {
rewrite /test1.txt/ /test2.txt break;
}
location ~ test2.txt {
return 508;
}
使用break会停止匹配下面的location,直接发起请求www.xxx.com/test2.txt,由于不存在文件test2.txt,则会直接显示404。
使用last的话,会继续搜索下面是否有符合条件(符合重写后的/test2.txt请求)的location。此时,/test2.txt刚好与面location的条件对应上了,进入花括号{}里面的代码执行,这里会返回508。
if指令
在location中使用if语句可以实现条件判断,其通常有一个return语句,且一般与有着last或break标记的rewrite规则一同使用。但其也可以按需要使用在多种场景下,需要注意的是,不当的使用可能会导致不可预料的后果。
upstream imageservers {
server 172.16.100.8:80 weight 2;
server 172.16.100.9:80 weight 3;
}
location / {
if ($request_method == “PUT”) {
proxy_pass http://upload.wisedu.com:8080;
}
if ($request_uri ~ "\.(jpg|gif|jpeg|png)$") {
proxy_pass http://imageservers;
break; #这里的break也是停止rewrite检查
}
}
if语句中的判断条件
正则表达式匹配:
==: 等值比较;
~:与指定正则表达式模式匹配时返回“真”,判断匹配与否时区分字符大小写;
~*:与指定正则表达式模式匹配时返回“真”,判断匹配与否时不区分字符大小写;
!~:与指定正则表达式模式不匹配时返回“真”,判断匹配与否时区分字符大小写;
!~*:与指定正则表达式模式不匹配时返回“真”,判断匹配与否时不区分字符大小写;
文件及目录匹配判断:
-f, !-f:判断指定的路径是否为存在且为文件;
-d, !-d:判断指定的路径是否为存在且为目录;
-e, !-e:判断指定的路径是否存在,文件或目录均可;
-x, !-x:判断指定路径的文件是否存在且可执行;
http核心模块的内置变量
$uri: 当前请求的uri,不带参数;
$request_uri: 请求的uri,带完整参数;
$host: http请求报文中host首部;如果请求中没有host首部,则以处理此请求的虚拟主机的主机名代替;
$hostname: nginx服务运行在的主机的主机名;
$remote_addr: 客户端IP
$remote_port: 客户端Port
$remote_user: 使用用户认证时客户端用户输入的用户名;
$request_filename: 用户请求中的URI经过本地root或alias转换后映射的本地的文件路径;
$request_method: 请求方法
$server_addr: 服务器地址
$server_name: 服务器名称
$server_port: 服务器端口
$server_protocol: 服务器向客户端发送响应时的协议,如http/1.1, http/1.0
$scheme: 在请求中使用scheme, 如https://www.magedu.com/中的https;
$http_HEADER: 匹配请求报文中指定的HEADER,$http_host匹配请求报文中的host首部
$sent_http_HEADER: 匹配响应报文中指定的HEADER,例如$http_content_type匹配响应报文中的content-type首部;
$document_root:当前请求映射到的root配置;