
高可用集群介绍
前面介绍的Nginx可以实现对后端服务的负载均衡,Nginx就是调度器。但是我们还要考虑一个,调度器本身在工作的时候仍然会有一个风险,因为我们把整个站点的请求的依赖性都建立在了调度器上,调度器坏了怎么办?只要是设备,都有可能会损坏。它一挂,整个服务器集群就挂了,我们不能允许这情况出现。怎么办?做一个备用的调度器,只是备用。随时监控祝调度器的心跳,只要它挂了就接替。调度器本身也是个服务,怎么工作成调度器。把主调度器的地址夺过来,自身启动调度服务,由它来负责调度。主调度器通过网络连接把自己的心跳信息随时向外传输,只要辅调度器能收到。这也是一种集群,高可用集群(HA,High Availability)。但是高可用集群必然有一台空闲着,资源浪费。
负载均衡集群具有高可用能力(但不是高可用集群),因为比如说用户请求被分发到第三台服务器上,而这时候第三台挂了,调度器只需要重新分发请求到好的服务器上就可以了。
HA集群,每一个主节点(就是指服务器)需要向其他节点通知自己的心跳信息,但是LB集群的节点是没有的。所以LB集群具有高可用能力,而这个能力不是依赖于后面的服务器的,而是依赖于前端服务器调度的。现在的问题是如果前端服务器不知道这第三台服务器挂了依然将用户请求分发至第三台怎么办?这种机制称为后端服务器的健康状况检查。检查好了到坏了,也检查坏的到好的。一般说来前端主机都应该具备这样的能力,这才是一个正常情况下的负载集群。
负载均衡集群是以提高服务的并发处理能力为根本着眼点的,而高可用集群是以提供服务始终在线能力为根本着眼点的,它不管你能应付多个个请求,但是一定要让你随时在线,不会因为宕机而使服务不用用了。
如何衡量一个服务的可用性?服务正常在线时间/(正常在线时间+故障处理时间)=可用性。
实现高可用集群的一些开源方案
- heartbeat
- corosync(openais分裂出来的一个项目)
- cman
- keepalived
前面的3套组件工作模式基本都是相同的,keepalived则不相同。keepalived最初的诞生是为了给ipvs提供高可用性。而ipvs说白了就是内核中的一些规则而已,keepalived最初的主要目的就是能够自己调用ipvs的adm命令来生成规则,并且能够自动实现将用户所请求的访问地址转移到其他节点上实现的。
Keepalived介绍
对于Master和Backup来讲,Master这个节点会不停的向另外一个节点通告自己的心跳,但是通告机制是基于VRRP协议实现的,backup一旦接收不到主节点的心跳,就会把vip资源抢过来。而在backup节点,只需要把本地keepalived中那个生效的服务中某一个模块,把它生效起来就可以了。所以keepalived自身是模块化设计的,它有着诸多模块,有些模块就是去监控并生效ipvs规则的。而且keepalived还可以实现后端realserver的健康状况检查。
虽然一开始是为了ipvs提供高可用,但是后来慢慢发展到可以为其他的服务提供高可用,比如对轻量级的调度器haproxy和nginx提供高可用。但是需要自己创建额外的脚本来实现。站在这个角度来讲,keepalived的核心大概是这个样子的:
- 1.vrrp的实现
- 2.跟vrrp相关的一些配置virtual server ——针对的是ipvs。
比如:基于vrrp所谓通告机制之上的对于其他资源的控制:比如对于虚拟服务器的控制。 - 3.vrrp_script:vrrp能够调用外部脚本的实现。
说白了,keepalived就是vrrp协议的实现。vrrp:虚拟冗余路由协议。为什么需要这个协议?比如说,公司有个局域网,有很多很多客户机,这些客户机都需要访问互联网或者其他网络的主机,要想和非本网段的主机通信都需要网关,但是一旦这个网关挂了怎么办?那所有非同网段的都访问不了了。那么如何去实现网关的可用性呢?第一种是让客户端自己发现问题,如果他发现上不了网了,我们在前面提供两个网关,这两个网关之间没有任何心跳信息传递,反正告诉客户端有两网关,其中一个不可用了自己改成另一个网关。第二种:在每一个主机上配置动态路由协议,让主机自动生成路由表。但是我们把pc机上的操作系统都配置为支持动态路由协议,这不是一件小工作。第三种:使用ARP网关。在每个主机上装一个ARP客户端,在前面的路由上装好ARP服务器端,那ARP客户端会自行去判定哪个可以用,哪个不可以用。这三种办法都需要依赖于客户端主机自身去做一些配置,才能保证其可用性。VRRP能够把两个网关虚拟成一个网关来使用,简单来讲,在两个网关前面抹上一层协议,这两个路由器之间可以通过选举决定谁是当前活动节点。一般情况下,只有一个是活动节点。【注意】:vrrp的ip地址是虚拟的,连mac地址也是虚拟的。vrrp协议专门生成了一段虚拟的mac地址来使用。所以这个活动节点拿到的不仅是是vip,还有vmac地址。所以客户端网关地址指向vip就可以了,无论实际上是哪个网关对客户端来讲是透明的。
很多路由设备都是支持vrrp协议的,像华为的等。因为vrrp是个开放式协议,几乎所有的厂商生产的设备都能够支持。那keepalived就是在Linux操作系统上实现了vrrp。比如说我们想用keepalived实现对nginx的高可用,不仅需要转移vip,还需要将相应节点上的nginx服务启动起来,同时还要监控本机上的nginx服务。
keepalived架构
在一个节点上,会启动一个主进程。一般来讲,在一个主进程下会生成两个子进程。一个是用来实现VRRP,另外一个是实现Checkers,检查服务可用性。【注意】:这里提供的check是对ipvs后端realserver的健康状态监测,而我们去监控服务的健康状况则需要自己写脚本。只不过我们仍然把这些脚本归类于checkers。
还有其他的组件,比如:I/O复用器、内存管理组件。还有最左边的是配置文件分析器,这个就是主进程,读取keepalived核心配置文件,分析主配置文件,生效主配置文件,并指挥这两个子进程工作。
WatchDog:是Linux内核中的一个模块,它也是一个计时器,它可以帮助主进程去盯着这两个子进程。主进程并不负责具体的工作,所有的具体工作都是由子进程完成的。这两个子进程任何一个挂了,keepalived就不完整了。keepalived启动以后,这两个子进程每隔两秒钟定期的向主进程打开的unix套接字文件写数据,就是发心跳信息。万一哪一个子进程不再发了,那么主进程就认为子进程挂了,然后去重启这个子进程。基于watchdog监控子进程。
看图中,官方给的图就说明主要是为ipvs提供高可用的,所以配置文件中的一大部分都是定义跟ipvs相关的配置。如果我们不用ipvs,这些配置大多都用不着。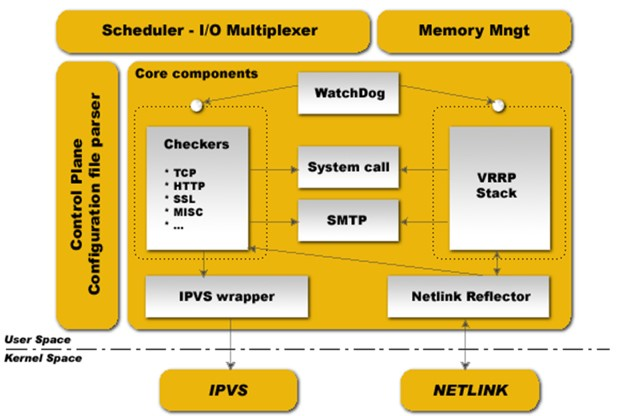
对于想要实现对nginx等服务的高可用,使用keepalived实现vrrp协议还不够,因为我们只转移VIP和VMAC,还需要监控和转移服务。有了chechers,我们就可以自己写一个脚本,这个checkers基于脚本调用每隔1秒钟或者两秒钟就来检查这个服务本身状态是否正常,比如取检查status,一旦得不到running信息,可以先重启这个服务。重启之后还不running就转移。怎么转移啊?vrrp是基于什么机制转移的?此时心跳信息依然正常的,并不是不通告心跳了,这个场景下心跳信息是正常的。此时就不能抢了,这个场景下的转移,依靠每个节点的优先级。优先级是从0-255。一般0和255不用,它们有特殊的用法。数字越大优先级越高。因此我们可以这么来定义,首先上来定义两个物理路由的优先级一大一小,比如100和99。一启动,100那个肯定是主的,99那个是从的。这个选举是通过比较物理路由的优先级的。每个节点上线都是backup,就比如一上来,大家都是村民,等人到齐了,就通过比较优先级选举村长。但是如果某个节点上线等了半天,其他节点不来,于是可以自认为自己是最高优先级的节点。这么个场景:100的那个节点服务已经挂了,脚本里重启服务也不行,但是心跳信息是好的,99那个又抢占不了,怎么办?这就是checkers的作用了,我们可以在检测到服务故障以后,人为的把当前节点的优先级降低,这样99那个就能依靠优先级高抢占VIP资源,然后尝试在99节点上启动服务。如何启动服务需要我们自己去写脚本。
VIP资源转移,我们管理员应该知晓这些转移情况,所以还应该有一个通知机制。万一某个节点发生了故障,应该尽可能早的给管理员发封邮件。你如果配置了有邮件服务器的话,这样节点上资源发生转移的时候会收到邮件通知的。
keepalived的转移速度和监控是非常轻量级的,尤其是对于那些用不着共享存储的、节点非常少的场景等应用的。但是对keepalived来讲,支不支持多节点呢?支持多个节点。但是对于同一组服务来讲,只能有一个节点是活动的,因为VIP和VMAC只能在一个节点上运行。所以是一主多从的模式,但是这种模式下,从越多,浪费越大。其实我们可以这样来做,让两个节点都活动起来。很简单,在两个节点上运行两组服务,一组服务是不可能的。在两个物理路由的基础上做两组虚拟路由。
如果说keepalived实现nginx的高可用,弄了两个vip,两台机器A和B都有Nginx服务,如何让用户访问到两个不同的节点呢?现在两个节点都是活动的,两个节点上nginx服务都在运行。而客户端端访问的时候只能访问一个,怎么能让客户端访问两个?使用DNS的两条A记录。不同的用户解析的结果是不同的主机,我们并不要求绝对的均衡,因此这里nginx提供的是轻量级的反向代理,nginx本身不是提供web服务的。如果是web服务的话,最好就不要使用这种方案了。由此,两个nginx都能正常工作,都能分发用户请求到后端的上游服务器上去。
基于DNS的转发,用户请求被解析的结果在一段时间内会缓存下来的,请求所访问的是同一个nginx。这就是分担负载模型的VRRP机制。基于这个机制,比如说你有3个节点,那就定义3组虚拟路由,其中每一组中,一个是组的,其他两个是备的。但是这多组虚拟路由之间不能干扰。如何让同一组物理路由设备上的不同虚拟路由呢?所以VRRP必须提供一套完善的管理机制。简单来讲,每一组虚拟路由得有自己独有的标识,称为虚拟路由VRID,虚拟路由id号。
还有一个问题,如果有人知道你这做了高可用,他拿来一个主机放在这,并且配置好了vrrp协议,请问这个主机是否有机会成为主节点呢?之前讲其他的高可用集群解决方案时提到不可以让别人的节点随意加到集群中来,那么怎么解决这个问题?要通过认证来解决。VRRP的认证支持两种认证机制,明文字符串认证和MD5、SSHA-1散列认证。明文字符串认证是指各节点间配置好共享域密钥。散列认证配置起来麻烦一点。
keepalived核心就是VRRP,能把VRRP玩转,服务可以通过写脚本,明白是怎么调用脚本的就可以了。如果需要对VRRP有个详细的了解,请搜索H3C的VRRP技术白皮书或者华为的。
安装配置Keepalived
环境信息
| 服务名称 | 操作系统版本 | IP地址 | 角色 |
|---|---|---|---|
| vip | CentOS 7.0 | 10.108.72.112 | JDK1.7、elasticsearch-2.2.3 |
| Nignx1、Keepalived | CentOS 6.5 | 10.108.72.110 | Master |
| Nignx2、Keepalived | CentOS 6.5 | 10.108.72.110 | Backup |
Nginx安装
关于Nginx的安装,参见前面的博客,这里不再赘述。
安装Keepalived
可以rpm安装,也可以源码安装,我这里选择了源码安装。
将keepalived-1.2.15.tar.gz上传到/opt/soft目录下。
[nginx@master soft]# tar -zxvf keepalived-1.2.15.tar.gz
[nginx @master soft]# ./configure --prefix=/opt/keepalived
[nginx @master soft]# make && make install
[nginx @master soft]# cp /opt/keepalived/etc/rc.d/init.d/keepalived /etc/rc.d/init.d/
[nginx @master soft]# cp /opt/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
[nginx @master soft]# mkdir /etc/keepalived
[nginx @master soft]# cp /opt/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/
[nginx @master soft]# cp /opt/keepalived/sbin/keepalived /usr/sbin/
[nginx @master soft]#mkdir /opt/keepalived/log
[nginx @master soft]#mkdir /opt/keepalived/scripts
配置Keepalived
将提供的主、从keepalived.conf配置文件拷贝到/etc/keepalived目录下,参考配置文件中的配置项说明调整配置文件。
1.Master上的Keeplived配置文件,keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
#负载均衡器标识,同一网段内,可以相同
}
vrrp_script chk_nginx {
#调用定义的检测模块
script "/opt/keepalived/scripts/check_nginx.sh"
interval 2
weight 2
}
vrrp_instance VI_1 {
#设置为主
state MASTER
#监控网卡
interface eth0
#主备服务器必须一样
virtual_router_id 51
#权重值MASTER 一定要高于备用机器
priority 101
# MASTER与BACKUP负载均衡器之间同步检查的时间间隔,单位是秒
advert_int 1
track_script {
chk_nginx
}
cast_src_ip 10.108.72.110
unicast_peer {
10.108.72.111
}
authentication {
#加密
auth_type PASS
#加密密码,主备要一致
auth_pass fudan123
}
virtual_ipaddress {
#虚拟IP
10.108.72.112
}
}
2.backup上的Keeplived配置文件,keepalived.conf
! Configuration File for keepalived
global_defs {
#负载均衡器标识,同一网段内,可以相同
router_id LVS_DEVEL
}
#调用定义的检测模块
vrrp_script chk_nginx {
#检查脚本
script "/etc/keepalived/scripts/check_nginx.sh"
#检查时间间隔
interval 2
weight 2
}
vrrp_instance VI_1 {
#设置为备
state BACKUP
#监控网卡
interface eth0
#主备服务器必须一样
virtual_router_id 51
#权重值 BACKUP 一定要低于 MASTER
priority 100
# MASTER与BACKUP负载均衡器之间同步检查的时间间隔,单位是秒
advert_int 1
track_script {
chk_nginx
}
#多播的源IP,设置为本机IP
cast_src_ip 10.108.72.111
unicast_peer {
10.108.72.110
}
authentication {
auth_type PASS
auth_pass fudan123
}
virtual_ipaddress {
#虚拟IP
10.108.72.112
}
}
Keepalived监控脚本
将提供的keepalived监控脚本分别拷贝到主、从服务器的/opt/keepalived/scripts目录下,并将脚本设置为可执行。
1.Master机器的监控脚本
check_nginx.sh
|
|
2.Backup机器的监控脚本
check_nginx.sh
Keepalived启动、关闭
1.将Keepalived加入系统服务
chkconfig --add keepalived
2.设置为开机自启动
chkconfig keepalived on
3.启动、关闭
service keepalived start/stop
测试Nginx高可用
1.在主服务器(10.108.72.110)测试与备服务器连接
tcpdump -vvv -i ens160 host 10.108.72.111
2.在备服务器(10.108.72.111)测试与主服务器连接
tcpdump -vvv -i ens160 host 10.108.72.110
3.先是两台都开启keepalived,然后通过VIP(10.108.72.112)访问;
4.再关掉第一台的keepalived,再通过VIP(10.108.72.112)访问,看看能否访问。
查看VIP在哪台机器上
ip addr show