
MySQL逻辑架构
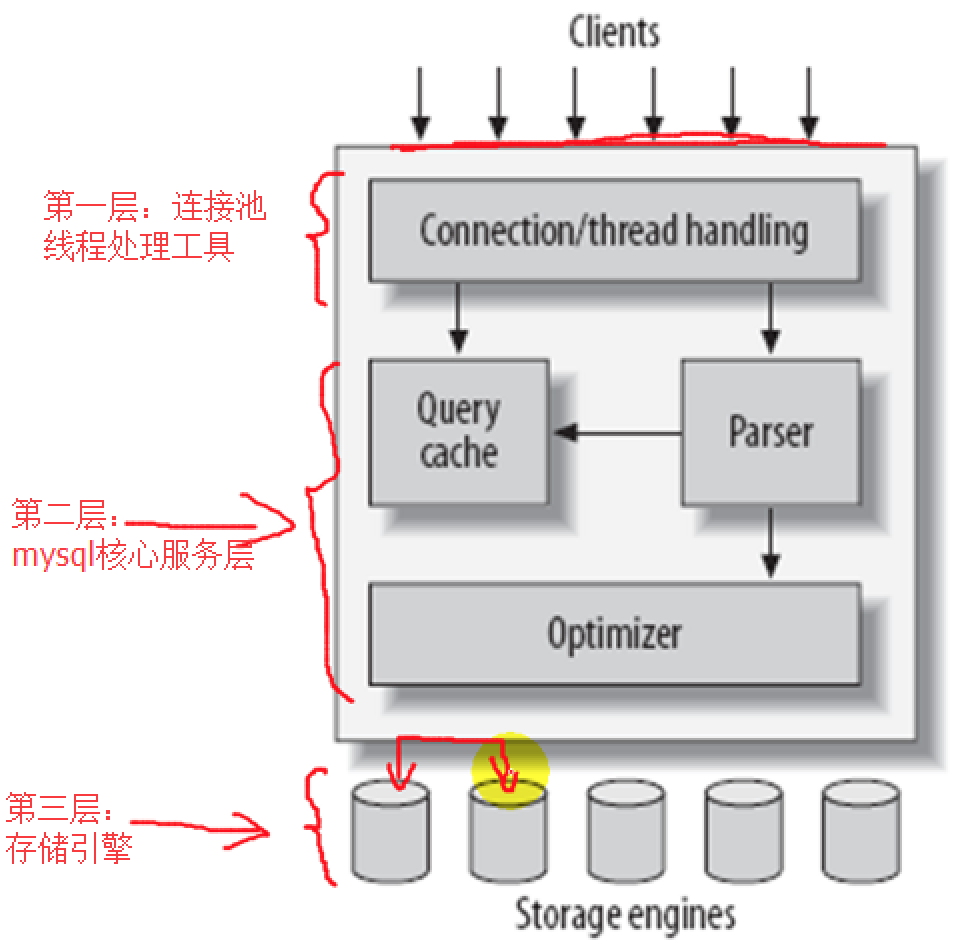
1.第一层:连接池或称为线程处理工具。处理用户的连接建立。
mysql现在对于线程管理是通过线程池来实现的。一个池子中所能够容纳的水量是有限的,所以一个线程池中所能够容纳的线程数也是有限的。所以mysql启动时事先创建好一个线程池,在这个池子内假如创建了100个空闲线程,来一个用户连接,给它一个线程,当用户连接达到100个,新连接就要排队等待,后面维持一个队列。当某个连接上的用户请求退出后,其对应的线程不会销毁,只会清理数据,还原成原来的样子,再去处理新的用户请求。
所以用户的连接线程在线程池的管理模式中是不会被销毁的,一般是能够实现重用的。所以就避免了频繁的线程创建和删除。
mysql客户端和服务器端通信要通过mysql协议进行通信,协议一般来讲有两种格式。http协议是文本的,我们可以通过telnet连进去手动发送命令的,https协议是二进制的。mysql协议这两种格式都支持。哪种协议会比较高效?二进制的会略微高效一点,所以很多支持两种协议的默认都使用二进制格式。无论是二进制还是文本,都是明文的,只不过你编码成了二进制格式而已,我们只需要一个解码工具,就能把二进制转换为原来的样子了。
为了安全,加密。mysql支持将它的协议基于ssl进行发送的。
2.第二层:mysql核心服务层。是MySQL的核心功能层。包括查询解析、分析、优化、缓存以及mysql的所有内置函数(BIF)等。
Parser:解析器,也叫分析器。主要功能是分析查询语句的。首先要做词法分析,要把整个sql语句切割成一个一个的片段,还要做语法分析,看看整个sql语句中有没有语法错误,甚至于还要做语义分析。这些都是由分析器完成。当然,mysql并没有自己开发分析器,有很多著名的开源分析器,yacc和lex,一个做词法分析,一个做语法分析的。mysql借用了这分析器做了二次开发并整合进mysql使用了。
Optimizer:优化器。包括重写查询、决定表的读取顺序(多表查询时调整表的读取顺序)、多表查询时选择一个开销最小的索引。但是我们在查询时,如果你作为用户知道哪个索引更好用,你也可以向mysql发送语句时给它提示以影响mysql决策的。对于mysql来讲,优化器并不关心底层那个表真正使用的存储引擎是什么,但是存储引擎根据其特性的不同所提供的性能表现也不同。但是优化器又不考虑存储引擎,但好在优化器会通过向存储引擎的API发起调用请求让存储引擎返回这种存储引擎下所对应的表的统计数据来判断这个表的查询开销有多大,并基于此做出优化决策。一直在说查询,INSERT和UPDATE都要查询的,我们这里讲的查询是广义上的查询,不仅仅是SELECT。不过,如果你真正执行的是SELECT,mysql还有个内部的工具对这种查询可以发挥效用以提升性能的,就是图中的Query Cache。
Query Cache只对SELECT语句有效。只有SELECT才会被缓存下来。所以如果我们执行的是SELECT语句,服务器每次在解析查询操作之前会去查看缓存中是否命中。所以这对SELECT操作是额外的开销,但是如果命中率足够可靠的话,Query Cache还是很有必要的。怎么查看查询缓存的命中率多高?后面讲到mysql优化时,会讲怎么根据缓存的统计数据来分析命中率的。在命中率的基础上决定到底是否开启缓存。你可以把缓存工作在某种特定模式下,默认mysql都不缓存。只有我们手动明确要缓存语句才缓存。
3.第三层:存储引擎。存储引擎的主要工作是真正负责数据的存储和提取的。
MySQL锁
MySQL允许多用户同时连接进来,如果多个用户在访问同一张表的时候,会发生什么问题?比如A用户连接进来修改表A,第二个用户B这时想查询表A中数据能否进行查询?不能查询,怎么达到这个目的呢?你得让B用户的查询操作知道表A正在被某一用户施加写操作。这需要MySQL内在的某些机制完成并发访问控制,而并发访问控制通常基于锁来实现。对于读操作来说,多个用户同时读是没问题的,但是对于写操作是不行的。
MySQL锁
1.按执行操作时施加的锁模式来分类:两种类型。
- 读锁:又称为共享锁,可以同时读,但是不可以写。读为什么要加锁,因为防止其他人去修改我们正在查询的数据的。
- 写锁:独占锁,排它锁。
2.按锁粒度划分:
- 表锁:table lock。锁定了整张表。开销最小。
- 行锁:row lock。锁定了需要的行。
粒度越小,开销越大,但并发性越好;
粒度越大,开销越小,但并发性越差;
- 3.按锁的实现位置划分:
- MySQL锁:可以使用显式锁。很多时候我们提到MySQL,是指第二层核心服务层。
- 存储引擎锁:自动进行的(隐式锁)。大多数查询操作都会自动由存储引擎施加锁的。
如何实现显式锁(在服务器级别显式锁只能是表级锁)
LOCK TABLES
UNLOCK TABLES #只能一次释放所有表的锁,不能指定表和锁类型。见下面的截图语法。
LOCK TABLES
tbl_name lock_type
[, tbl_name lock_type] ...
锁类型:READ|WRITE
【示例1】:演示读锁。
mysql> use hellodb
Database changed
mysql> LOCK TABLES classes READ;
Query OK, 0 rows affected (0.00 sec)
启动另一个终端,连接进来: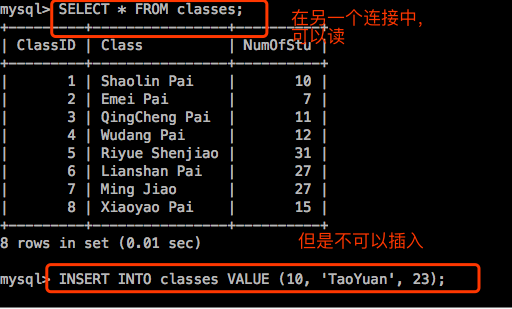
在第一个终端上,释放锁:
mysql> UNLOCK TABLES;
Query OK, 0 rows affected (0.00 sec)
然后到第二个窗口,会发现数据已经插入成功了。
InnoDB存储引擎也支持另外一种显式锁(锁定挑选出的部分行,行级锁 ):
SELECT ... LOCK IN SHARE MODE; 共享锁
SELECT ... FOR UPDATE; 排它锁
【示例2】:演示InnoDB行级锁。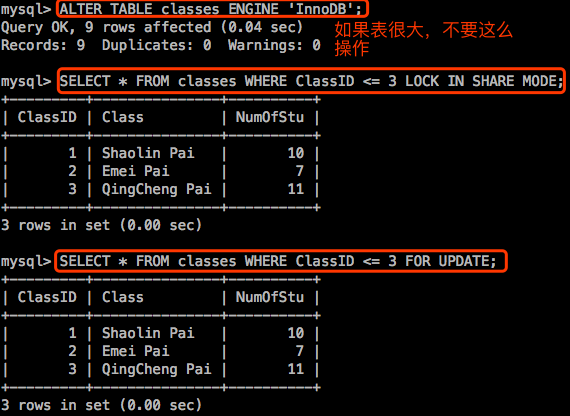
【注意】:
1.只是在语句执行过程中添加了锁,语句执行结束了锁就释放了。因此就没有UNLOCK了。
2.除了特性情况下,做备份操作时,不建议手动施加锁,因为存储引擎会自动进行锁操作,而且它的锁操作性能比我们自己施加要好的多。做备份操作时,要手动添加读锁。
事务Transaction
基于锁我们实现了一定意义上的并发功能了,但是一般来讲,为了完成更高级别的操作,需要支持事务。
事务就是一组原子性的查询语句,也即将多个查询当作一个独立的工作单元。
【注意】:MyISAM存储引擎是不支持事务的。
ACID测试:能满足ACID测试就表示其支持事务,或兼容事务。
- A:Atomicity,原子性。
- C:Consistency, 一致性。我们的数据库总是从一个一致性状态转到另一个一致性状态。比如,Tom从自己的账户(7000)转账3000到Jerry账户(5000)上, 这样Tom就只剩4000,Jerry就有了8000。转账前二者总和是12000,转账后还是12000。
- I: Isolation, 隔离性, 一个事务的所有修改操作在提交之前所有的修改对其它事务是不可见的。
- 第一步:Tom: 7000-3000。事务没提交之前,有人查询Jerry账户,是不能看到这多3000的。同样查询Tom账户,也不能看到少了3000。因为我们事务还没提交
- 第二步:Jerry: 5000+3000
- D:Durability, 持久性, 一旦事务得到提交,其所做的修改会永久有效。
事实上,ACID机制需要背后有强大的机制才能实现的,而且一旦让一个存储引擎或关系型数据库支持事务,那么它在复杂程度上面是成几何倍上升的。并且如果事务做的完全隔离,事务就是串行的了。如果做到完全隔离,只有在两个事务压根不会涉及到同一张表的时候才会同时执行,否则只要涉及到同一个数据集,事务都只能以串行方式进行。数据安全性越高,其并发性就越低。所以就有了隔离级别的概念。
隔离级别
隔离级别(4个):
- READ UNCOMMITTED (读未提交)
读别人还没提交的数据,这属于没什么隔离性的。数据安全性最差,但并发性最好(但从实际上来看,不会比其他级别好太多。又极其缺乏安全性,所以很少用。)
会产生脏读,不可重读,幻读(看到的数据和背后的数据不一样) - READ COMMITTED (读提交)
只有别人提交了,我们才能看到。市面上常见的大多数关系型数据库隔离级别都是读提交,不过mysql不是。mysql是第3个隔离级别,可重读。
不可重读,幻读 - REPEATABLE READ (可重读)
解决了脏读问题,而且可重读,但是解决不了幻读问题。 - SERIALIZABLE (串行化)
强制事务的串行执行避免了幻读。
跟事务相关的命令:
解释下常用的:
mysql> START TRANSACTION 手动显式启动一个事务。在这个事务中执行的所有语句在你执行下一条语句之前都处于未提交状态,未提交的事务都可以进行回滚。
mysql> COMMIT
mysql> ROLLBACK 回滚。回滚时有个问题,如果我们的事务非常大,假如有60个语句,我们执行到第40个的时候,发现第38个错了,如果能够回滚到第35个会比回滚到开头好多了,这就需要SAVEPOINT。我们可以在事务中设置多个保存点,给保存点设置个名字。
mysql> SAVEPOINT identifier
mysql> ROLLBACK [WORK] TO [SAVEPOINT] identifier
示例1:演示事务回滚
【注意】:MySQL数据库默认启动了自动提交的功能,也就意味着哪怕你手动不提交,也会自动提交的。但是当我们显式启动事务时,MySQL就不会自动帮我们提交。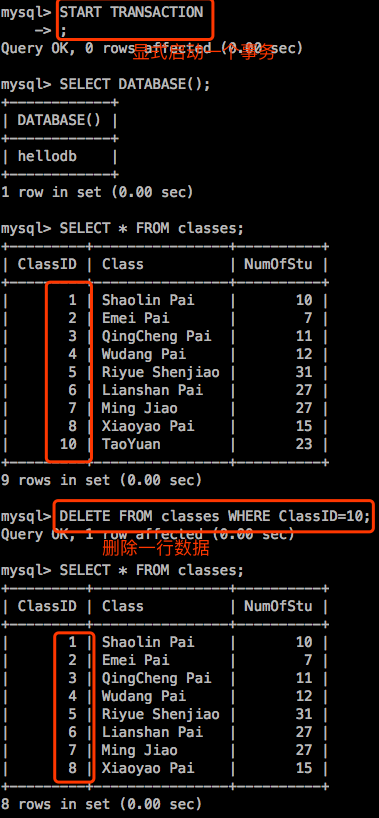
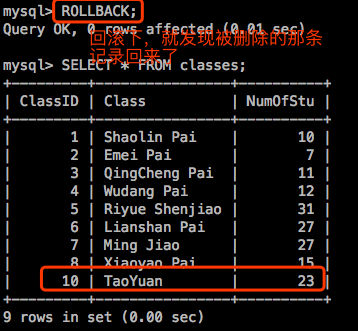
示例2:演示SAVEPOINT
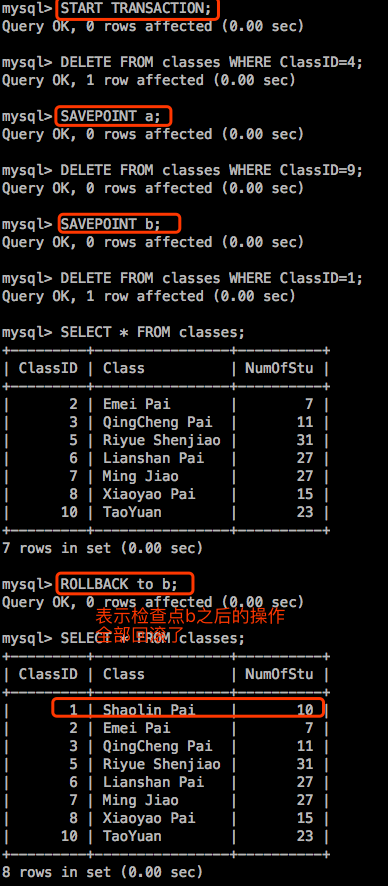
如果没有显式启动事务,每个语句都会当作一个独立的事务,其执行完成后会被自动提交。自动提交会带来性能上的很大影响,因为每一个语句都自动提交,都会产生一个I/O。
mysql> SHOW GLOBAL VARIABLES LIKE '%commit%';
+--------------------------------+-------+
| Variable_name | Value |
+--------------------------------+-------+
| autocommit | ON |
| binlog_order_commits | ON |
| innodb_api_bk_commit_interval | 5 |
| innodb_commit_concurrency | 0 |
| innodb_flush_log_at_trx_commit | 1 |
+--------------------------------+-------+
5 rows in set (0.00 sec)
mysql> SELECT @@global.autocommit;
+---------------------+
| @@global.autocommit |
+---------------------+
| 1 |
+---------------------+
1 row in set (0.00 sec)
mysql> SET GLOBAL autocommit = 0; 注意这么改对当前会话没有影响,因为我改的是全局的。
如果关闭自动提交,请记得手动启动事务,手动进行提交;
事务隔离级别演示
MySQL默认的事务隔离级别是可重复读。查看MySQL的事务隔离级别:
mysql> SHOW GLOBAL VARIABLES LIKE '%iso%';
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| tx_isolation | REPEATABLE-READ |
+---------------+-----------------+
1 row in set (0.00 sec)
mysql> SHOW GLOBAL VARIABLES LIKE 'tx_isolation';
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| tx_isolation | REPEATABLE-READ |
+---------------+-----------------+
1 row in set (0.00 sec)
mysql> SELECT @@global.tx_isolation;
+-----------------------+
| @@global.tx_isolation |
+-----------------------+
| REPEATABLE-READ |
+-----------------------+
1 row in set (0.00 sec)
示例3:演示”读未提交”
mysql> SET GLOBAL tx_isolation='READ-UNCOMMITTED';
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW GLOBAL VARIABLES LIKE '%iso%';
+---------------+------------------+
| Variable_name | Value |
+---------------+------------------+
| tx_isolation | READ-UNCOMMITTED |
+---------------+------------------+
1 row in set (0.00 sec)
重新打开两个shell,连接进mysql:注意进去后两个shell要各自先启动事务。然后在到第一个会话执行操作。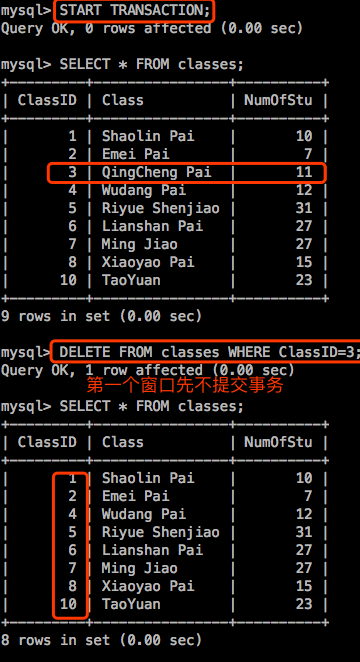
在打开一个shell,连接进mysql: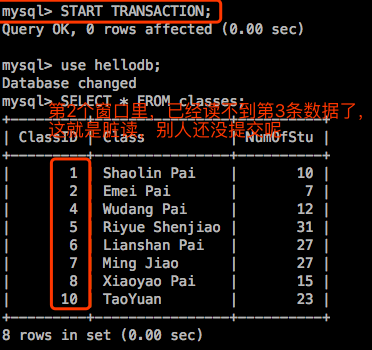
下面第一个会话回滚事务:
mysql> ROLLBACK;
Query OK, 0 rows affected (0.00 sec)
到第2个会话中,再次查询:
第2个会话回滚事务。
mysql> ROLLBACK;
Query OK, 0 rows affected (0.00 sec)
示例4:演示”读提交”
mysql> SET GLOBAL tx_isolation='READ-COMMITTED';
Query OK, 0 rows affected (0.00 sec)
重新打开两个shell,连接进mysql:注意进去后两个shell要各自先启动事务。然后在到第一个会话执行操作。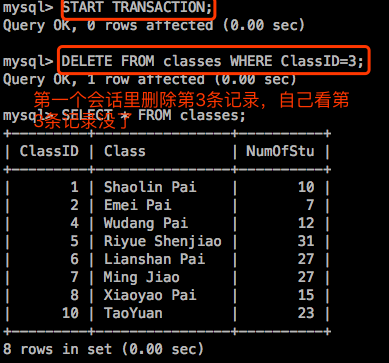
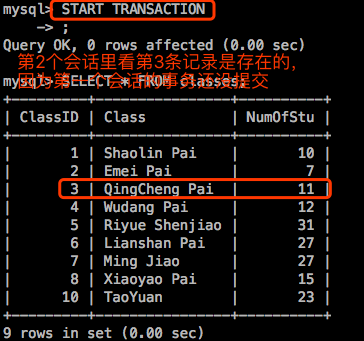
此时如果第一个会话中的事务回滚了,那么第二个会话看到的还是第3个数据是有的,这是很正确的;
但是如果第一个会话中的事务提交了,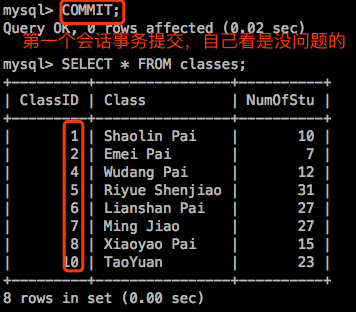
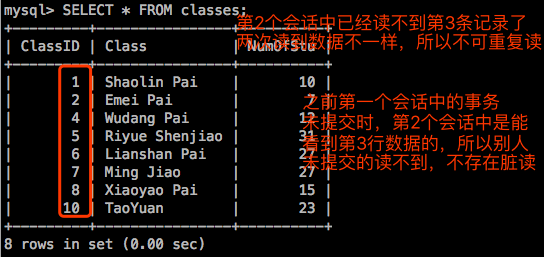
同一个事务中多次读取的结果不一样,这就是不可重复读。所以脏读了就一定不可重复读,因为你每一次都能读到别人直接修改的数据。所以”读提交”在同一个事务中多次读取仍然可能是不一样的。
示例3:演示”可重读”
mysql> SET GLOBAL tx_isolation='REPEATABLE-READ';
Query OK, 0 rows affected (0.00 sec)
重新打开两个shell,连接进mysql:注意进去后两个shell要各自先启动事务。然后在到第一个会话执行操作。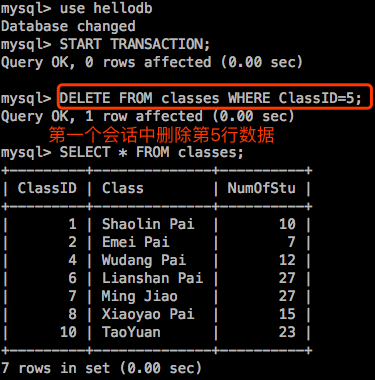
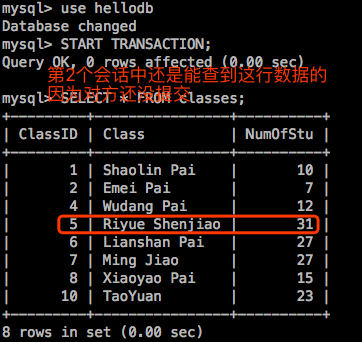
但是如果第一个会话中的事务提交了,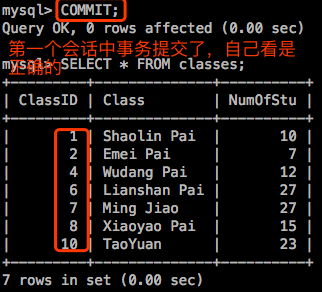
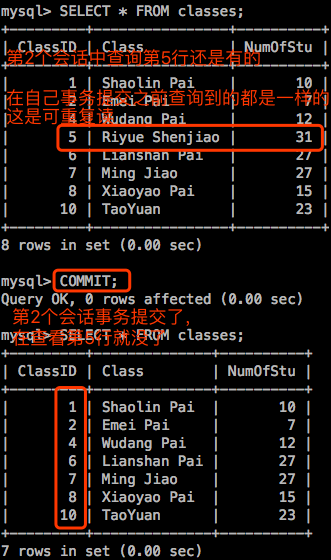
虽然”可重读”解决了不可重读的问题,但是仍然没有解决幻读的问题。
示例4:演示”串行化”
mysql> SET GLOBAL tx_isolation='serializable';
Query OK, 0 rows affected (0.00 sec)
重新打开两个shell,连接进mysql:注意进去后两个shell要各自先启动事务。然后在到第一个会话执行操作。

只能等对方提交或者回滚,你才能查看结果。串行化解决了幻读的问题,但是性能太差了。
【建议】:对事务要求不特别严格的场景下,可以使用读提交。要想让配置永久生效,要改配置文件。
事实上mysql是怎么实现的?为什么别人提交了,对可重读来讲,还不能看到数据。这就是MVCC机制。
MVCC:多版本并发控制
对于可重读等机制来讲,每个事务启动时,InnoDB为会每个启动的事务提供一个当下时刻的快照,后续的所有操作都是在快照的基础上执行的。因此不管事务执行多长时间,在同一个事务中看到的数据是一致的。
为了实现此功能,InnoDB会为每个表提供两隐藏的字段,一个用于保存行的创建时间,一个用于保存行的失效时间(就是哪个事务删除过)。
实际上里面存的不是时间,里面存储的是系统版本号;(system version number)。每启动一个事务,InnoDB存储引擎就会给这个事务创建一个当下时刻的快照,并且为对应所读取的数据的快照启动一个新版本号,+1。
MVCC只在两个隔离级别下有效:READ COMMITTED和REPEATABLE READ。