业务线在压测性能时,希望将应用一些图标(appIcon.do)利用Nginx缓存功能缓存下来。
Nginx缓存功能
简单来说,就是Nginx将后端服务器返回来的部分内容缓存到本地磁盘,后面客户端请求中含有这部分内容时,可以从本地磁盘取出这些内容返回给客户端。
如果Nginx本地没有缓存时,那么响应给客户端的过程是:被代理服务器先得自己磁盘IO一次,将内容取出,然后将内容通过网络IO响应给Nginx,Nginx然后在将该内容响应给客户端。
如果Nginx在本地缓存下这部分内容,当用户请求到达时,如果请求的内容中包含这些,Nginx直接从自己本地磁盘取得内容,构建响应报文,响应给客户端。
在后端服务器上(被代理服务器上),磁盘上文件是按树状结构组织的,按照文件名、按照路径去组织的。我们去查找文件时,只能把整个树状结构,就是把document_root所指向的子目录,整体装入内存。将来我们找哪个文件时,才会知道这个文件在哪个路径下,能快速定位到这个文件。
Nginx缓存是这么处理的:存储也是树状结构,但是这种树状结构格式很独特,名字是固定等级的,要么是一级路径,要么是两级路径,要么是三级路径。而且每一级路径的文件的名字是hash码的一部分,要么是两个字符,要么是1个字符,因此直接基于用户请求url的字符串,就能知道这个文件在什么地方存放的。因为缓存下来的文件名是用户请求资源的url字符串的hash码,内容是那个请求页面的正常内容。
当用户请求url时,如何判定本地缓存有没有呢?像后端服务器就只能遍历,去找树状结构路径下是不是存在。但是对于hash格式来讲,它实际上是基于路由方式来实现。对Nginx而言,通常是这么找的。把这个url编码以后,从右往左截取字符,完成路径路由。因为是16进制的,有1个字符,就有16种变化,有两个字符,就是256种变化,最多不超过3级。如果你的缓存定义分级路径是1:1:2,意味着1级子目录16个,就是说用1个字符来表示, 2级目录16个(指的是1个1级子目录下有16个),此时一共是256个,3级子目录,每个子目录有256个,每个子目录2个字符。所以从编码后的url截取字符,从右往左,截1个字符表示1级子目录,在截一个字符表示2级子目录,在截两个字符,表示3级子目录。所以Nginx去找文件的时候,直接在url路径上就这个文件在哪个路径下了。当到第三级子目录下,底下的文件肯定不止1个,有一堆,这时候就得遍历去寻找要匹配的文件了。
对于Nginx缓存来讲,它的数据存储分为两个部分,第一部分是放在内存中的hash表,以便于一个url请求来的时候,做hash计算后去查表。如果hash表中没有,就不会去缓存在本地文件系统磁盘里找这个文件了。所以有没有命中在内存中就能判断了。第二部分是放在本地磁盘上的目录结构,一旦有,就路由到那个目录下,那个数据就在那。所以这个查找过程速度无与伦比,第一基于内存,第二它是hash值,时间O(1),恒定,从100个中找1个和在100万中找一个所需要的时间几乎是等同的。
使用Nginx缓存
缓存空间得先定义,后使用。比如说在内存中用哪段空间来存hash表,用多大内存。磁盘上用哪段文件路径来存放目录树。
查缓存也有讲究,http的请求方法有GET、HEAD、POST、PUT、DELETE,后3种方法没必要查缓存。因此对每一种请求过来,我们先判定方法,这个方法如果不支持从缓存里找,就不用看缓存了。一般只对GET和HEAD启用缓存。
而且并不是所有GET和HEAD的资源都应该缓存。如果用户GET一个资源的时候, 用户第一次来访问时,服务器setcookie,这个就不应该缓存下来。还有一种场景,用户去请求一些资源时,服务器要求输入用户名和密码,这些内容也不应该缓存。因此不是GET和HEAD的所有资源都要缓存的,对于用户的私有信息,不应该缓存下来。
还有一些服务器端在响应时就说了,有些资源不能缓存,告诉代理服务器不能缓存,代理服务器也不应该缓存。服务器在响应时,为了避免代理服务器缓存下来,会告诉代理服务器这些资源是no store,基于cache control来定义。
浏览器是可以使用shift+f5强刷的,强制刷新就要求发请求报文时,no cache,意思是不能从缓存中给我响应。
再考虑一种场景,第一个用户请求资源时使用的是http 1.1的协议,取得的内容被Nginx缓存下来了。第二个用户使用http 1.0的协议去请求了,它两也不一定能完全兼容。所以还得考虑协议版本。协议版本不一样时,没准也不能使用缓存来响应。
缓存空间是有限的,存满了,这就需要cache_manager进程了,根据LRU(最近最少使用算法)将此前没有用的缓存对象清除出去。
缓存指令
Nginx缓存指令说明:http://nginx.org/en/docs/http/ngx_http_proxy_module.html
缓存相关的有多个指令,proxy_cache打头的。缓存得先定义,后使用。下面来介绍一些常用的关于缓存方面的指令。
定义缓存:path [levels=levels] 这个目录下分几级子目录,每一级用几个字符来表示。
比如:
缓存内容,是按需创建目录的。而不是一开始把所有目录都创建出来。现在只是把缓存定义了,还没调用。上面定义的目录/data/nginx/需要事先创建好。
调用缓存指令:
对于调用缓存来讲,至少需要3个参数。
- 首先得声明调用(proxy_cache指令),使用哪块缓存空间。(实践过了,如果之定义这一条指令,没有任何东西会被缓存下来)
- 缓存时把什么当key,这也是是必须要给的。proxy_cache_key
- 哪些内容能存,存多长时间得自己来定义。哪些东西不能存,哪些方法不检查缓存也得自己定义,虽然你不定义有默认值,但是也得定义出来 proxy_cache_methods、proxy_cache_valid
比如:
其中最后一项配置解释下:
如果我们把内容缓存下来以后,后端服务器找不着了,也就是后端服务器不在线了,此时能不能用缓存内容来响应。也就是指明什么情况下可以使用过期的缓存来响应。比如后端服务器响应error,后端服务器连不上timeout
缓存实例
【实例】:Nginx实现缓存图标
先创建缓存目录:
mkdir /opt/nginx_cache
定义缓存: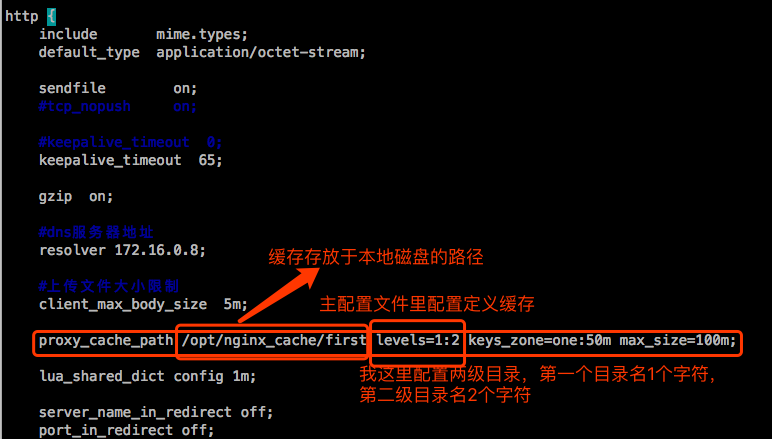
使用缓存:
重载Nginx。此时缓存目录/opt/nginx_cache/first/目录下没有任何内容。
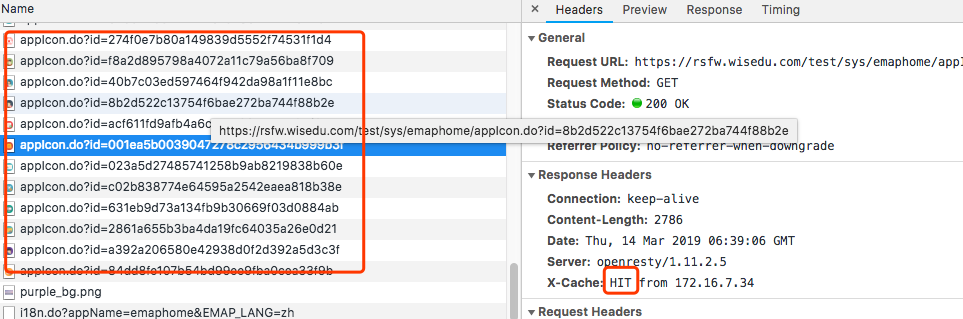
浏览器访问,打开F12查看:
第一次访问时,都是MISS。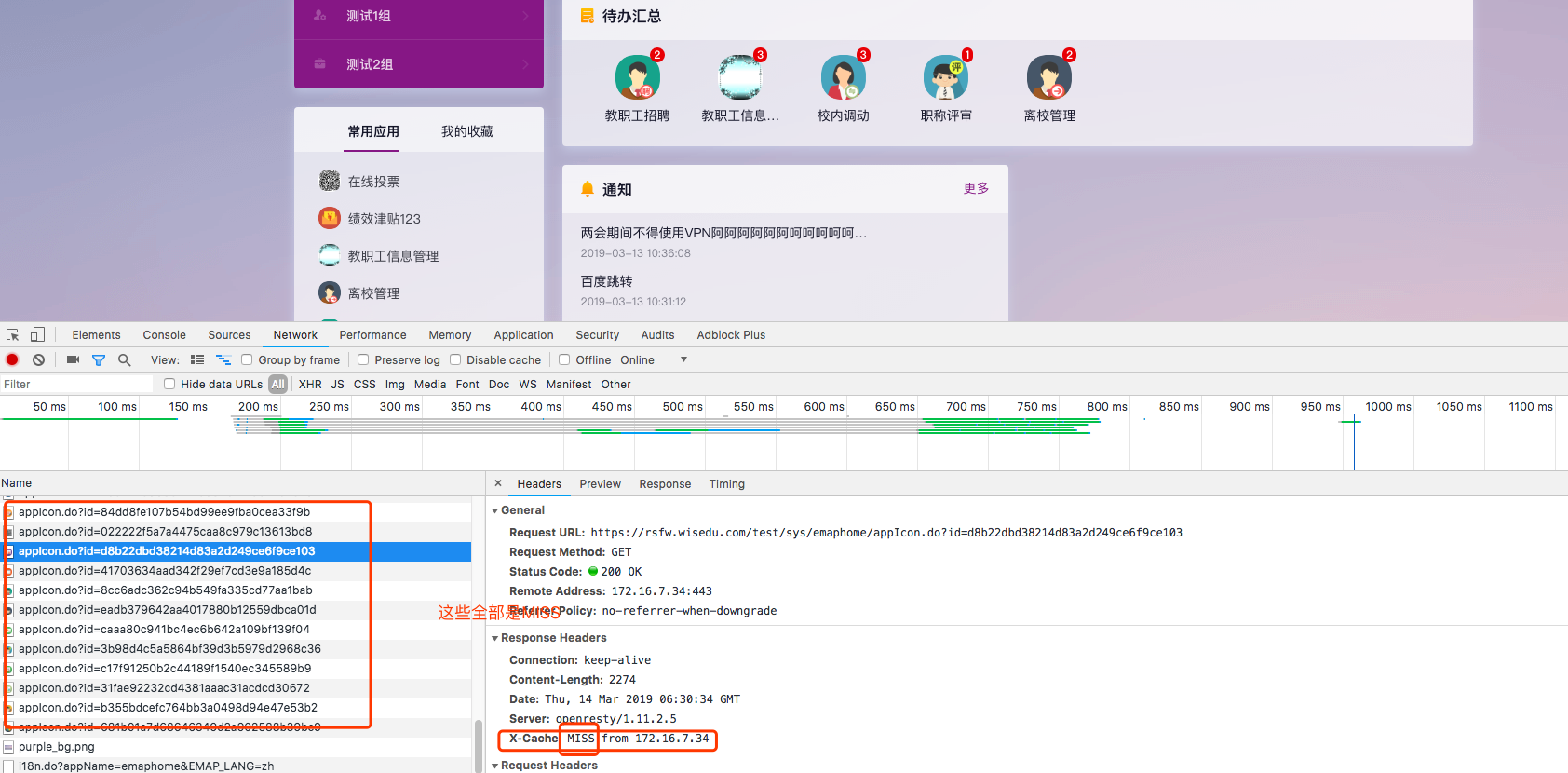
此时查看opt/nginx_cache/first/目录下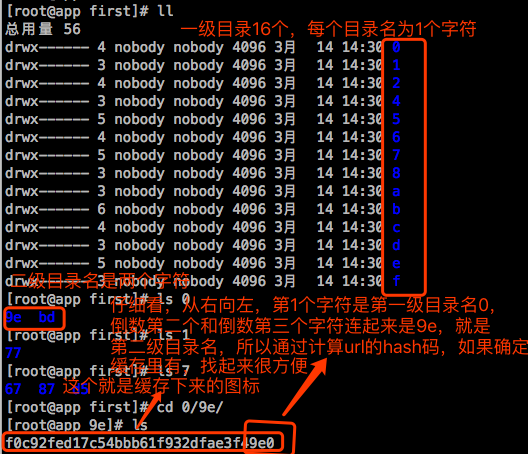

再次刷新页面,就可以看到是命中了。