
Pod控制器
Pod控制器介绍
此前使用配置清单创建Pod,都是在配置文件中定义要创建的Pod具体是什么。而后就提交给apiserver,由apiserver转交给Scheduler完成调度,由目标节点予以创建并启动相关的Pod资源。如果我们把Pod资源意外删除,Pod不会重建。
在实际应用中,去管理Pod资源时很少用自主式Pod方式。之所以介绍自主式Pod,是为了讲清楚Pod是怎么创建的,而后面介绍的控制器创建Pod时,都是内嵌了Pod模板的。也就是将此前手动管理的Pod资源的定义方式内嵌到控制器的定义结构中去。
Pod控制器是用于实现代我们去管理Pod的中间层,并帮我们确保每一个Pod资源始终处于我们所定义或者所期望的目标状态。万一这个Pod资源出现故障,首先它会尝试着去重启容器,如果一直重启有问题的话,那么可能会基于某种策略来重新委派。如果Pod的副本数量低于用户所定义的目标数量,它也会自动补全。
Pod控制器分类
ReplicationController: 最早k8s只有这一种控制器。后来发现ReplicationController设计目标过于庞大,一个想完成所有的功能。目前推荐使用ReplicaSet。
ReplicaSet: 主要是帮助用户管理无状态的Pod资源。代用户创建指定数量的Pod副本,并确保Pod副本一直处于满足用户期望的数量的状态。多退少补。支持自动扩缩容策略。主要有三个核心资源组成:
1.用户期望的Pod副本数
2.标签选择器,判定哪些Pod是自己来管理的
3.Pod资源模板:如果集群中现存的Pod副本数量不够用户定义的副本数量时怎么办?新建Pod,根据Pod模板来建立。
但是ReplicaSet却不是我们直接使用的控制器。或者说k8s不建议我们直接使用ReplicaSet,而是使用Deployment。Deployment: 也是个控制器,工作在ReplicaSet之上。也就是说Deployment不是直接控制Pod,而是通过控制ReplicaSet来控制Pod。基于此,一定是Deployment能够提供比ReplicaSet更为强大的功能。Deployment还支持滚动更新和回滚等众多更为强大的机制,还提供了声明式配置的功能。这种声明式配置使得我们将来创建资源时可以基于声明的逻辑来定义。那些所有更新的资源我们可以随时重新进行声明,随时可以改变在apiserver上定义的资源的目标状态,只要对应的资源支持动态运行时修改。
DaemonSet: 用于确保集群中的每一个节点只运行一个特定的Pod副本。这些Pod通常是用来实现所谓的系统级的后台任务。当然系统级的后台任务本可以以守护进程的方式来运行这些任务,但是这种方式,服务宕了没法恢复。把这些任务托管到k8s之上有一个好处,宕了后可以被控制器自动重启。还有一个好处,当集群中新加入节点,DaemonSet会确保集群中的每个节点精确运行一个Pod,新节点进来了,上面也会启动一个这样的Pod。所以对于DaemonSet来说,不用定义Pod副本数量了,但是Pod模板肯定是要存在的。只有有了Pod模板,才能够建立起Pod资源。另外,标签选择器也是需要的,毕竟每一个节点上有没有符合我们所指定条件的Pod资源,是要靠标签选择器来判定。
用于确保集群中的每一个节点只运行一个特定的Pod副本。其实还有另外一个需求,我们也可以根据自己的需求在集群中的部分节点上,每一个节点只运行一个Pod副本。比如说要监控ssd硬盘的Pod,如果不是所有节点都有ssd,就没必要在没有ssd硬盘的节点上运行这个Pod了。
无论是Deployment还是DaemonSet,都有这么几个特点。一是服务都是无状态的,二是这些服务必须是守护进程类的,就是必须持续地运行在后台。但是有的时候我们有这种需求,比如对数据库做备份操作,这种备份操作可以自己手动启动一个程序来运行,也可以在k8s上启动一个Pod来实现。备份结束了,这个Pod就没必要运行下去了。能实现这种功能的叫Job。
Job: 也是控制器。要不要重建Pod,就看任务是否完成。只能执行一次性的作业。
Cronjob: 周期性任务。Job只是一次性运行。对于Cronjob来说,如果前一次任务还没结束,下一次任务时间已经来临了,怎么办?所以Cronjob要去处理这个问题。
StatefulSet: 管理有状态应用。而且每一个Pod副本都是被单独管理的。它拥有着自己独有的标识和数据集。一旦这个Pod出现故障了,新的Pod加进来之前,我们可能需要做很多初始化操作。
假设要管理redis cluster,cluster中几个Pod,没办法取代任何一个。这种场景中我们关注的是个体行为。每个个体都要被单独对待。而不像Deployment,假如运行了3个Nginx,任何一个Nginx挂了,调度器生成一个新Pod,把配置文件一改启动起来就可以了。但是redis cluster中任何一个Pod故障了,新生成一个Pod,是取代不了之前那个的。
看起来很美好,把每个Pod当做个体来管理。但是用StatefulSet去定义管理Redis、Mysql、Zookeeper,配置方式肯定不一样。配置主从复制操作步骤肯定是不一样的。部署方式也是不一样的,没有什么共通的规律可循。因此StatefulSet最多给我们提供了一个封装控制器,这个封装指的是我们需要人为地把我们需要手动做的操作,那些复杂的操作逻辑定义成脚本,放置在StatefulSet的Pod模板的定义之中。每一次Pod故障发生后,通过脚本能自动恢复回来。难度比较大,试想一下,MySQL主从,那个代表从的Pod副本宕了,怎么能够重建个Pod副本过来,让这个Pod副本能够作为从节点。一个运行很久的MySQL,里面会有大量的数据,我们需要先从主节点做备份,备份后恢复到从节点。而且备份的时候还需要记下binlog的文件名和位置。随后在从节点上启动时还要指定从指定文件的指定位置开始。这些操作要封装成脚本实现。Pod副本创建时自动实现。好不容易开发成功这个StatefulSet,后面还有redis集群。redis主从和mysql是不一样的,又是另外一套脚本。而且脚本未必能考虑到所有情形。
所以有状态应用在k8s托管管理是极其麻烦的,原因在于有状态应用的运维技能要求非常高,运维操作步骤是各不相同的。没办法抽取共同特点,并定义模式来工作。只能每一种应用分别、单独地对待。k8s还支持一种特殊的资源叫TPR。
TPR: Third Party Resources, 从k8s 1.2+开始支持第三方资源, 但是到1.7又被废了。因为有了更新的功能叫CDR。
CDR: Custom Defined Resources, 用户自定义资源。从k8s 1.8+开始支持。自定义资源可以把我们运维操作技能封装进去,定义成一种特殊类型的资源,或者把我们要管理的目标资源的管理方式定义成一个独特的管理逻辑来实现。我们还可以借助CoreOS研发的叫做Operator的东西来实现灌进去我们的运维技能。
Operator:实现的灌进去的运维技能比StatefulSet要强大的太多了,但是到今天为止,成熟的Operator支持的也不过是etcd,promethus等几个。
k8s现在难就难在使用门槛太高。每一次创建资源都需要自己写配置清单才行。任何一个系统,如果不把用户当傻瓜的话,注定用户不可能太多。为了解决这样的问题,k8s后来提供了一种功能叫Helm,头盔,外壳。Helm跟Linux上的yum一样。以后在部署应用程序,比如要在k8s之上部署redis cluster,刚才那样写要写半天,现在有人写好了,我们直接helm install就ok了。当然我们用的不是install命令,而是传一些参数告诉它,要创建什么样的存储卷,利用多少空间来存数据,以及我们要创建几个规模的集群。
目前Helm诞生还不超过3年,即便如此,大量主流的应用在Helm上已经有了。我们可以直接使用Helm就可以安装了。
查看ReplicaSet帮助文档
简称rs。
【注意】:截至目前为止,rs在使用时的apiVersion是apps/v1,explain时看到的显示的是旧版本,帮助文档没更新到最新。
rs.spec下定义的主要是replicas、selector和template这3个字段。其中,template就是定义Pod的模板。
这里的metadata和spec是Pod的metadata和spec。
ReplicaSet示例
示例1:创建ReplicaSet
先清理掉集群中无用的Pod。
【示例】:
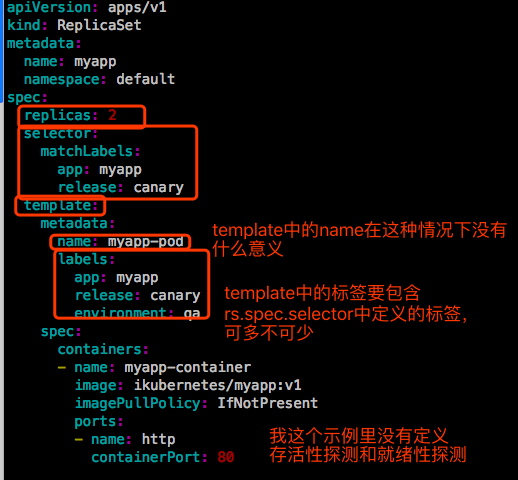
【说明】:
1、rs的metadata和Pod的metadata很类似,rs自己也是个资源,也可以有标签,也可以有注解。如果需要的话自己定义就行。这里为了结构清晰一点,就不写了。
2、spec.selector是个标签选择器,它是一个对象,支持两种挑选方式。第一种是基于等值的标签选择,matchLabels。它是个map,可以给定多个键值。第二种叫matchExpressions。
3、spec.template也是个对象,嵌套的字段有两个:metadata和spec。template中定义的的metadata中标签要包含selector中的标签,否则创建的Pod不符合自己的选择器,没有意义。当然也可以在template中定义多余的标签。
4、对于容器来讲,一般要做存活性探测和就绪性探测的,这里为了结构清晰和简单,就没写。
现在删除一个Pod,看控制器是否会自动重新创建一个Pod: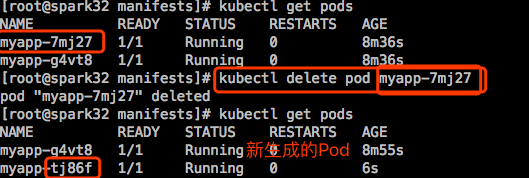
创建一个别的Pod,并为这个Pod打上标签,使得这个Pod可以被上面创建的RS的标签选择器选中:
|
|
结果这个新创建的Pod pod-demo被终止删除了,RS始终保持被选中的Pod的副本数量为我们在清单文件中定义的值2。
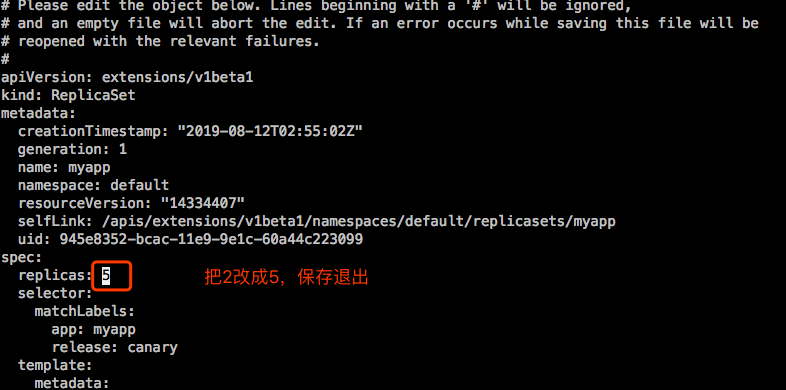
示例2:扩容
kubectl scale 或者 kubectl edit rs的清单文件
示例3:更新升级
更新升级:更新升级无非是去改容器的镜像文件的版本。
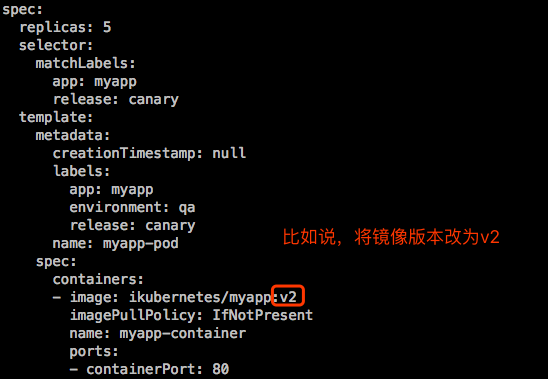
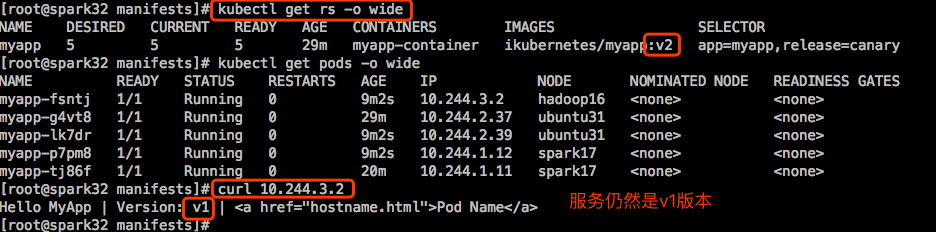
改了控制器的template中的镜像版本,Pod资源并不会被改掉,因为Pod资源不会被重建,只有重建的Pod资源,它的版本才会改掉。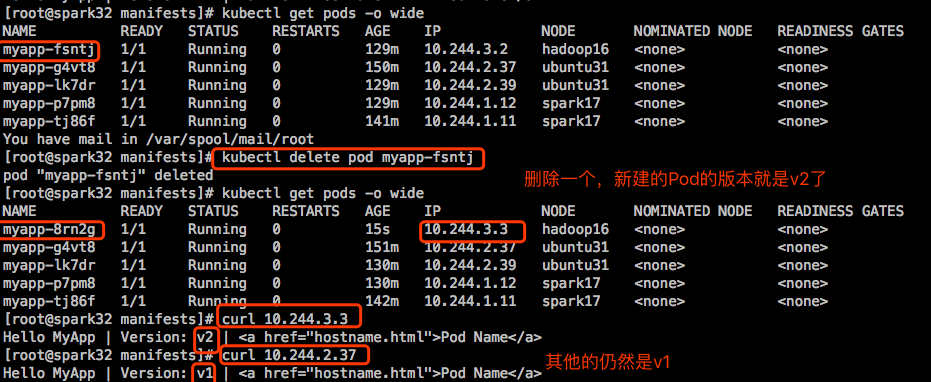
删除一个,一个重建,发布完成;
删除一个,一个重建,发布完成;
删除一个,一个重建,发布完成;
…
这是“灰度发布”。但是这需要我们人为参与进来。节奏我们自己能掌握,如果只删除一个,这叫金丝雀。那些被导向到v2的就是小白鼠,试试新版本有没有问题,两天以后,没人反应有问题,那就可以全部升级了。这是金丝雀发布。
当然也可以一次性把所有Pod都删除了,但是一次性全删除了,一定会影响在线访问的。这种发布有点暴力,虽然更新也很快。最妥当的更新是用蓝绿的方式进行。在创建一个rs,新的rs的标签选择器可以和老的rs的标签选择器不完全一样,但跟前面的service都能兼容。即service关联的pod既来之rs1,也来自rs2。我们先创建rs2,在删除rs1,这就是蓝绿发布。
或者先创建rs2,等rs2就绪了,修改service,将service匹配rs2,不在指向rs1。这样才是真正意义上的蓝绿。但是仍然需要我们自己去规划部署。有一个组件就是建立在rs之上完成的,叫Deployment。Deployment就是帮我们干这个事情的,能提供滚动式、自定义更新。Deployment建立在rs之前,一个Deployment管理多个rs,但是当前正在使用的只有1个。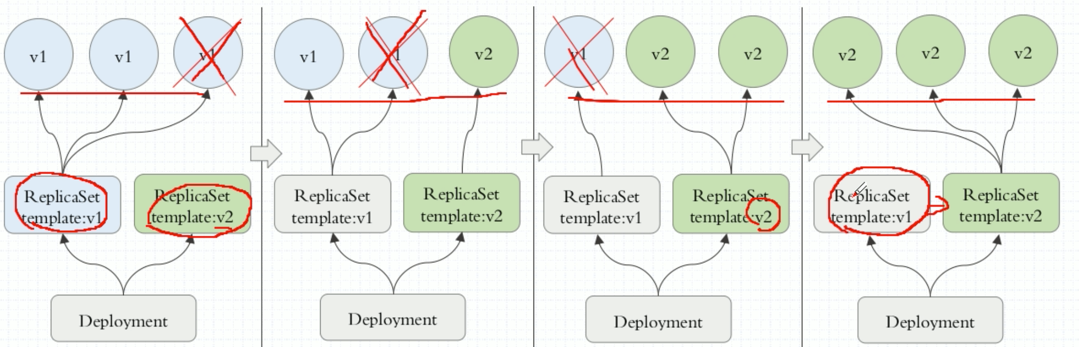
而且Deployment提供声明式更新配置,声明式创建一般使用apply,而不使用create。对于apply管理的,还可以patch打补丁来实现修改,而不用使用edit。我们完全可以在命令行中通过纯命令方式来直接完成对应资源版本内容修改。说白了就是可以使用POST方式来提交内容来进行修改,而不是直接改配置文件。直接通过打补丁的方式来修改。
Deployment除了可以实现滚动更新,还可以控制更新节奏和更新逻辑。假如说ReplicaSet有5个Pod副本,刚才手动更新是这么更新的,删除1个,由rs自动创建1个,在删1个,在自动创建1个。有这么个场景,假如这5个刚刚能满足用户访问需求,我们通过service将用户流量调度到这5个Pod上。删1个,这4个不足以承载这么大的流量。怎么办?不删又不能更新。如果支持先加1个,在删1个。加1个是违反Pod管理机制的,副本数是精确反应在清单中定义的数量,加1个就多了1个,所以这里是需要临时加1个。所以临时加几个,怎么加是可以控制的。我们不但可以指定在滚动更新期间,最多能够多出我们期望副本数量几个,还能定义最多能少于副本数量几个。
控制逻辑可以实现 灰度、金丝雀、蓝绿发布。
滚动更新时,定义liveness和readiness是很重要的,不然一启动就就绪了。