
StatefulSet介绍
简称sts。
不同的分布式系统运维管理逻辑和运维操作过程是不尽相同的。因此没有办法有一种控制器把每一种功能都同步进来,让我们非常简单地去操作这些有状态应用。即便有了StatefulSet,我们用StatefulSet去实现真正功能控制时也是极其麻烦的。StatefulSet即便在一定程度上能实现有状态应用的管理,但是我们需要自行把对某个应用的运维管理过程写成脚本注入到StatefulSet的文件中,才能使用。
好在Kubernetes支持叫做TPR,后来变为CRD了,第三方资源或自定义资源。甚至于还支持其他更为复杂的机制,比如叫api聚合。当我们使用api聚合时,就需要自己去修改k8s源代码,增强我们自己所需要的功能。好在k8s很有弹性,支持非常灵活的扩展功能。后来CoreOS提供了一个组件叫Operator。我们可以把操作封装到这个组件中。
StatefulSet管理有以下几个特点的Pod:
1、稳定且惟一的网络标识符;
2、稳定且持久的存储;
3、有序、平滑地部署和扩展;
比如像redis的主从集群,应该先启动主节点,然后在启动从节点。从节点如果没有先后顺序,可以一下子全启动,如果有先后次序,可能要求串行来,先启动一个从,在启动第二个从…
4、有序、平滑地终止和删除;
比如现在要缩减redis集群的规模,现在的架构是一主八从的,在关闭的时候应该把这个8个从节点先关掉,而且关的时候,如果启动的时候是串行启动的,关的时候也得串行关。比如8个从节点,名字分别是r1-r8,应该先关r8,在关r7,逆序来进行。
5、有序的滚动更新;
假如仍然是主从服务器,应该先滚动更新从节点,而且是逆序的。先更新r8,在更新r7。。。把所有的从都更新完了,在去更新主节点。因为从节点的版本高的特性能兼容版本低的,反过来不行。当然更新完后要确保它们的特性能互相兼容,如果不兼容,更新谁都不行。
一般来讲,一个典型的StatefulSet由3个组件组成:
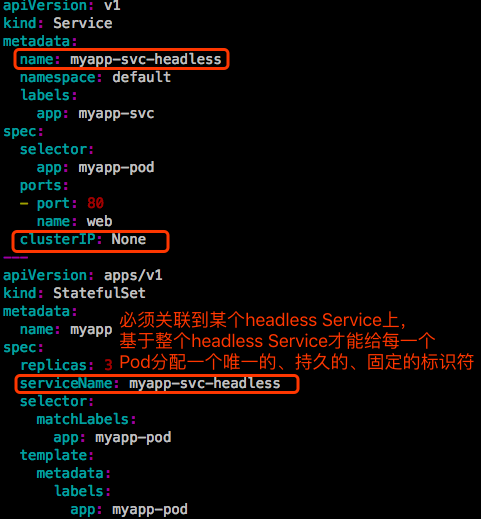
- headless service:之前使用Deployment的时候,Pod是没有顺序的,随机字符串。我们无法识别这些Pod的顺序。因此是无序的。但是在StatefulSet中要求这些Pod必须是有序的。多个Pod有主从之分,启动时有顺序r1-r8,终止时也有顺序r8-r1。每一个节点,每一个Pod都不能随意被别的所取代。比如r6因为有故障重建了,那它重建还应该是r6。尤其是redis cluster最容易理解,redis里面有很多槽位来存数据,比如第一个节点1-5000,第二个节点5001-10000,第三个10001到16383。第一个节点挂了,随后替换出来的时候它没有顺序了,这事情就很麻烦。因为只有靠数据才能识别它是管理哪些槽位的。因为Pod的IP地址会变化的,所以我们不以IP地址来识别,而是以Pod名称来识别。所以Pod名称不能变。在有状态的集中,每一个Pod的名称都不能变,删了Pod,被重建的Pod的名称还必须得是此前Pod的名字。所以Pod的名称是作为识别Pod唯一性的标识符。这个标识符必须稳定持久有效。怎么能保证Pod标识符持久稳定有效呢?这个时候就需要用到headless service来确保我们解析的名称是直达后端Pod的IP地址,并确保给每一个Pod配置一个唯一的名称。
- StatefulSet控制器:
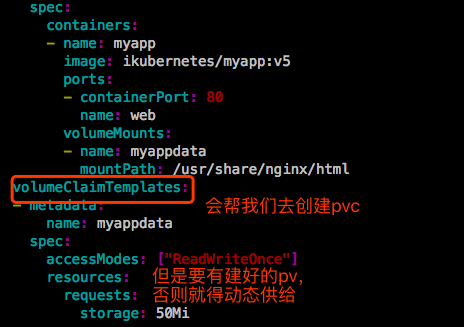
- volumeClaimTemplate:存储卷申请模板。大多数有状态副本集都会用到一个功能,都会用到持久存储。仍然以redis为例,做一个redis cluster在3个Pod存储数据不一样,对分布式系统,它的最大特点就是数据是不一样的,所以这3个Pod能不能使用一个共享的后端存储。比如我做了一个NFS存储卷,3个Pod多路读写同一个存储卷肯定是不行的。如果是web服务,网页文件放在同一个存储卷上,3个Pod都挂载这个存储卷,向客户端提供服务是没有问题的。但是3个redis的Pod使用同一个存储卷是不行的,3个Pod存的数据是不一样的,因此不能使用同一个存储卷,每个Pod应该有自己专用的存储卷。这些数据有可能是重名的,一重名就覆盖掉了,所以不能使用同一个存储卷。如果在Deployment中的Pod的template中定义一个存储卷,如果你Deployment中定义的Pod副本是5个,那么这5个Pod使用的将是同一个存储卷。因此我们基于Pod的template创建Pod是不适用的。这就为什么要定义volumeClaimTemplate的原因。这样我们创建每一个Pod时,它会自动生成一个pvc,从而请求绑定一个pv,从而有自己专用的存储卷。
StatefulSet示例
之前NFS服务器输出了5个目录。
|
|
先清理掉集群上的deploy、svc、pod、pvc资源。
对于pv,我这里用的是默认策略:Retain,之前有个pv被pvc绑定了,虽然删除了这个pvc,pv变成了Released状态,但是这个pv依然不能为其他pvc所用。
只能先删除了这个pv,然后在重新创建pv。
示例1:创建StatefulSet demo
|
|
|
|
如上所示:Pod的名称不再是随机的了。
volumeClaimTemplate做了两件事:
- 第一为每一个Pod定义了volumes
- 第二在Pod所在的名称空间中自动创建了pvc 【注意】:直接删除这个StatefulSet,是不会删除生成的pvc的
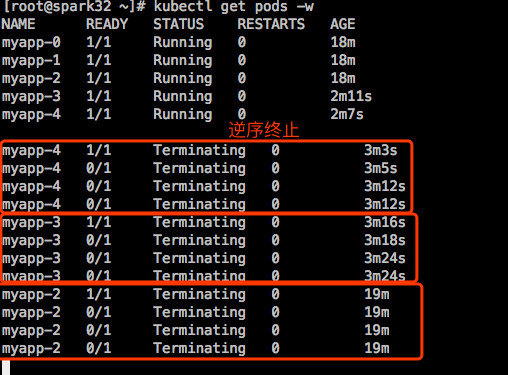
删除StatefulSet,看看pod是否是倒序删除的:
在一个终端上监控着pods:
在另一个终端上删除这个StatefulSet:
这样看不明显,重新创建下,看下创建过程:
只要使用同一个StatefulSet去创建,创建后就会绑定相应的pvc上去。
对于StatefulSet来说,也支持动态更新,或者叫滚动更新,也支持扩容和缩容。比如从现在的3个扩展到4个,它会为第4个Pod专门在创建个pvc,满足5Gi空间的pvc。而后创建个有名字的Pod,使得它能够正常工作起来。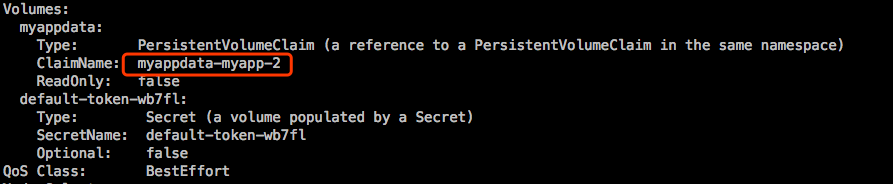
解析Pod的名称时,Pod必须跟上它无头服务的名称:
pod_name.service_name.ns_name.svc.cluster.local
在本示例中:myapp-0.myapp.default.svc.cluster.local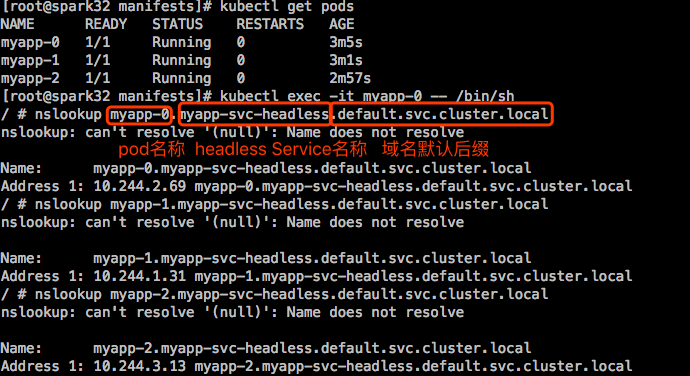
每一个Pod名称是固定的,DNS中能解析,所以我们靠这唯一名称去识别它以后,跟它的固定名称的pvc保持对应关系,pvc的名字隐含了pod的名字,使得pvc能够持续地给同一个Pod使用。
示例2:扩容缩容
使用scale或patch。
现在有5个pv,还有2个没用,扩展到5个Pod,扩展的时候是先扩展第4个,在扩展第5个。
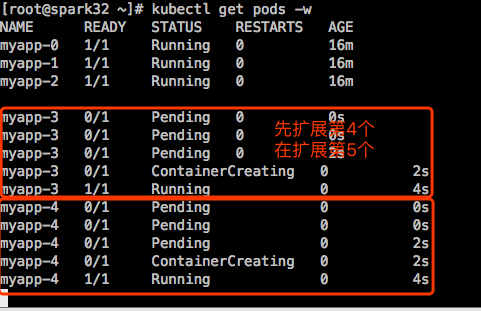
接着缩减至2个:
示例3:升级StatefulSet中的应用程序版本
使用set image。
更新分区:
假设现在有5个Pod,这5个Pod是有标识符的,分别叫myapp-0到myapp-4。如果定义partition为5,意味着编号大于等于5的将会被更新。比如这里定义为5,那就都不更新。定义为4,那就myapp-4会被更新,其他不会被更新,这叫金丝雀发布。随后我们发现这myapp-4向客户端提供服务没有任何问题,接下里在手动打补丁,把partition改成0。
先把StatefulSet扩展到5个。
sts默认更新策略是RollingUpdate,但是没有定义partition,默认为0。

以上演示的都是无状态应用,如果真正要用有状态应用,会很麻烦。