
容器的资源需求和资源限制
定义在容器级别的属性pods.spec.containers。目前支持定义CPU和内存资源。
CPU: CPU资源属于可压缩型的,一个Pod或一个容器在获取本应该获得的CPU资源却获取不到时,无非就是等待就行了。
CPU的单位:在k8s之上,1颗逻辑CPU可以化为1000颗millicores,我这里称为毫核心或微核心。比如:500m=0.5CPU。
内存: 但是对内存来讲不是如此,假如它所需要用到的内存资源不够时,有可能会因为内存资源耗尽而被kill掉。因为内存资源属于非可压缩性资源。单位为E、P、T、G、M、K 和 Ei、Pi、Ti、Gi、Mi、Ki,i表示1024。
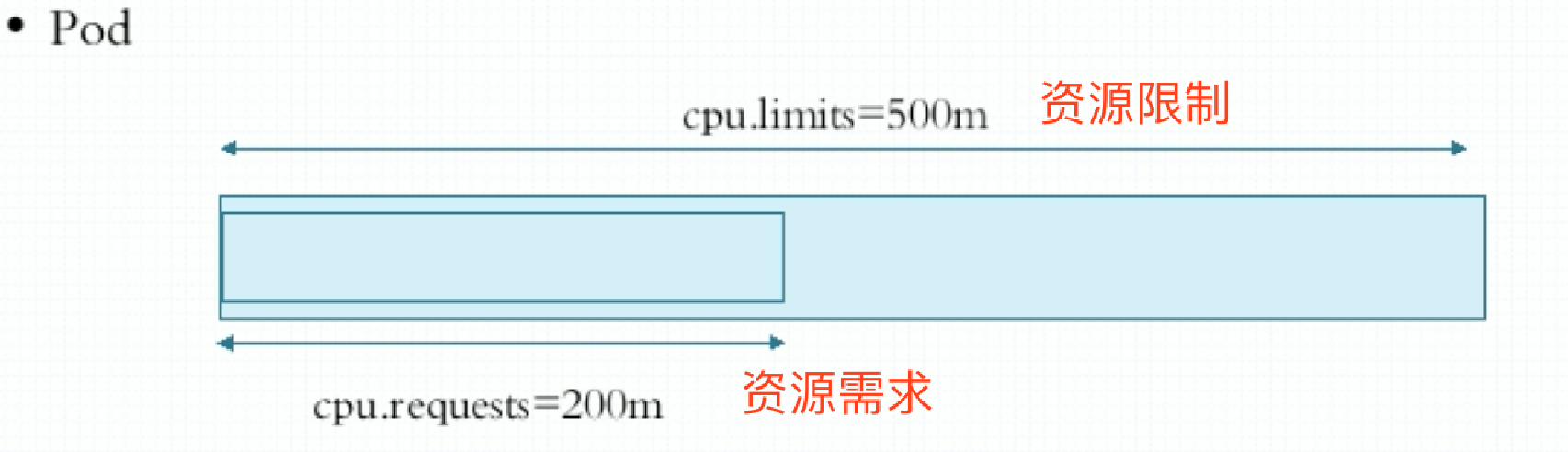
在定义资源需求时,最好把资源限制也定义了,防止容器中的应用程序因为bug或其它原因把CPU都吃掉。
示例
|
|
|
|
|
|
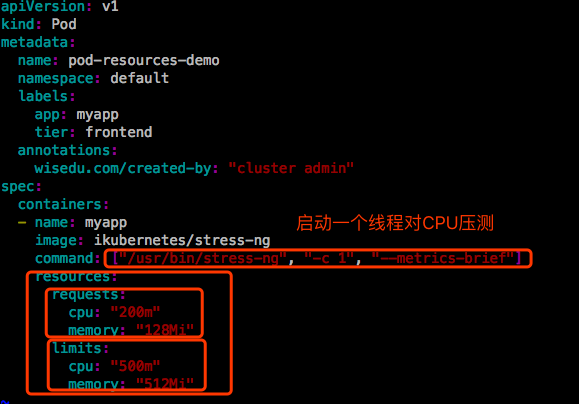
pod运行在节点spark17上,这台服务器是4核CPU。而这个pod内的主程序占用CPU比例为13%,其实是12.5%,500m是0.5CPU,也就是1/8。
【说明】:容器的可见资源量和可用资源量不是一回事,在容器内使用free命令看到的是整个节点上的内存,而不会仅仅是当前容器中的内存,这会有问题的。比如,在一个容器中运行一个jvm,jvm上很多程序在跑起来要分堆内存的,如果在容器中看到的内存可用量不是容器的最大限额,而是节点的内存量,可能使用节点可用内存的%几十,这就比较麻烦。计算结果很可能会吞掉整个容器的内存都不够。所以目前来讲,在容器的资源限制,在这个维度上还是存在一些问题的。
|
|
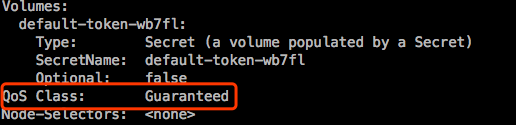
QoS Class: 服务质量 类别。
在容器中限制了资源以后,系统会自动分配属于一个QoS类别。一般有3个类别:
- Guranteed: 确保保证。
这类Pod具有最高的优先级。最先可被运行起来
一个Pod中的每个容器同时设置CPU和内存的requests和limits,并且满足requests=limits
cpu.limits=cpu.requests
memory.limits=memory.request - Burstable: 一个Pod中至少有一个容器设置CPU或内存资源的requests属性。
这类Pod具有中等优先级。 - BestEffort: 一个Pod中没有任何一个容器设置了requests或limits属性;
最低优先级别;
创建一个新的清单文件,将requests和limits中的值都设置为一样:
|
|
当系统上资源不够用时,会优先终止BestEffort类别的Pod,以腾出资源来确保另外两类Pod中的容器能够正常运行。假设系统上只有Burstable和Guranteed时,Burstable类别有很多Pod,先终止哪一个?因此需要有一种计算标准去终止。其实在k8s代码中有一段设置的是尽可能把它对应的request资源占用量比例较大的给关掉。比如现在有两个Pod,以内存为例,第一个Pod中limits是1Gi,requests是512Mi,此时已经占了500Mi,不会一上来就立马占用了512Mi。第二个Pod中limits是2Gi,requests是1Gi,此时已经占了512Mi。这两个Pod终止的是第一个,因为第一个占据的量已经接近它的requests的量了。认为第二个Pod是比较温和的,声称要1Gi,目前只用到了512Mi。而第一个声称要512Mi,现在已经用了500Mi。
Heapster
heapster介绍
在k8s上创建运行了Pod后,想知道Pod到底占用了多少资源了,比如定义了limits为512Mi,requests是256Mi,现在想看看到底用了多少了。docker有命令docker status,k8s之上也有命令可以看kubectl top。但是现在没法用。这个top命令的使用依赖于集群上部署一个叫 heapster 的附件。包括此前部署的dashboard上有些资源使用显示也是依赖heapster的。
统一的资源指标收集和存储工具,至少有个收集功能,当用户需要看的时候,它能联系到每一个节点上,通过每个节点上本地的agent来获取到这个节点之上的每一个进程甚至是节点本身的资源用量。传统的k8s集群中默认使用的指标采集和存储工具叫heapster,但是heapster只是个汇聚工具。在每个节点上运行的有一个组件叫kubelet,kubelet是可以获取当前节点上由它来创建和管理的各种资源对象尤其是Pod的相关信息数据的,但是真正完整去采集节点级和Pod的数据是kubelet当中的一个子组件,也是kubelet的插件叫 cAdvisor。早期的kubelet版本中1.8之后,这个cAdvisor已经是kubelet内建的功能了。cAdvisor专门负责收集当前节点上各Pod上的各容器以及节点级各种系统级资源指标的占用量。比如节点级的CPU、内存和存储用量,以及Pod级的各CPU、内存和存储用量。收集完后早期版本是支持单节点查看,现在不支持了。以前cAdvisor是监听在节点的4194端口,现在已经关掉了,不需要用户主动连接它来收集,而是由它来报告,报告给heapster。
heapster早期是专门为cAdvisor在每个节点上采集的数据为一个统一的存储工具。我们在集群上托管运行一个Pod,heapster。然后每个cAdvisor会去主动向heapster报告采集到的数据。heapster可以将数据缓存到内存中,但是内存是有限的,只能缓存一段时间的数据,以供kubectl top查看。如果想长期存储,得靠另外一个组件,heapster调用外部的时序数据库系统,叫InfluxDB。以后还可以查看历史中的信息数据。不过得借助另外一个工具来查看,grafana。grafana是可以把InfluxDB当数据源的。
但是从k8s 1.11开始,heapster已经废弃了,转向了新的监控模型:metric-server。