
Service介绍
为了给客户端提供一个固定访问端点,因此在客户端和服务端(Pod)之间添加了一个固定的中间层,这个中间层称为service。这个service的名称解析强依赖于在k8s集群之上部署的一个附件叫k8s的DNS服务。较新版本中,使用的是CoreDNS。1.11之前的版本用的是kube-dns。
Kubernetes要想能够向客户端提供网络功能,需要依赖于第三方的方案。在k8s新版本中可通过cni(容器网络插件标准接口)来进行接入任何遵循这种插件标准的第三方方案。
在Kubernetes集群中有三类网络:
- node network
- pod network
- service network(cluster network):虚拟的地址,Virtual IP。
在每个节点上,有个组件叫kube-proxy。这个组件将始终监视着master上apiserver中有关service资源的变动信息。随时要连到apiserver上获取任何一个与service资源相关的资源变动状态。这种是通过Kubernetes中固有的一种请求方法叫watch来实现的。一旦有service资源的内容发生变动,包括创建、修改、删除,kube-proxy都要把它转换为当前节点之上的能够实现service资源调度到后端特定Pod资源上的规则。这种规则可能是iptables,也有可能是ipvs,取决于service的实现方式。
Service工作模型
service的实现方式在Kubernetes之上有三种模型。
userspace模型
所谓用户空间可以理解为用户的请求。看下图。一是来自于用户内部的请求,Client Pod发请求,请求某个服务时,一定先到达当前节点内核空间的iptables规则,这个iptables规则其实就是service规则。这个service规则,它的工作方式是请求到达Service IP以后(iptables),由service先把它转为本地监听在某个套接字上的用户空间的kube-proxy,由它来负责处理,处理完后在转给Service IP,最终代理至这个service关联的相关Pod。kube-proxy是工作在用户空间的进程。所以被称为userspace。这种方式效率很低,原因在于先要到内核空间,然后然后回到当前主机上的用户空间,由kube-proxy封装请求报文代理完以后在回到内核空间,然后有iptables规则进行分发。效率很对。因此后来就到了第2种方式。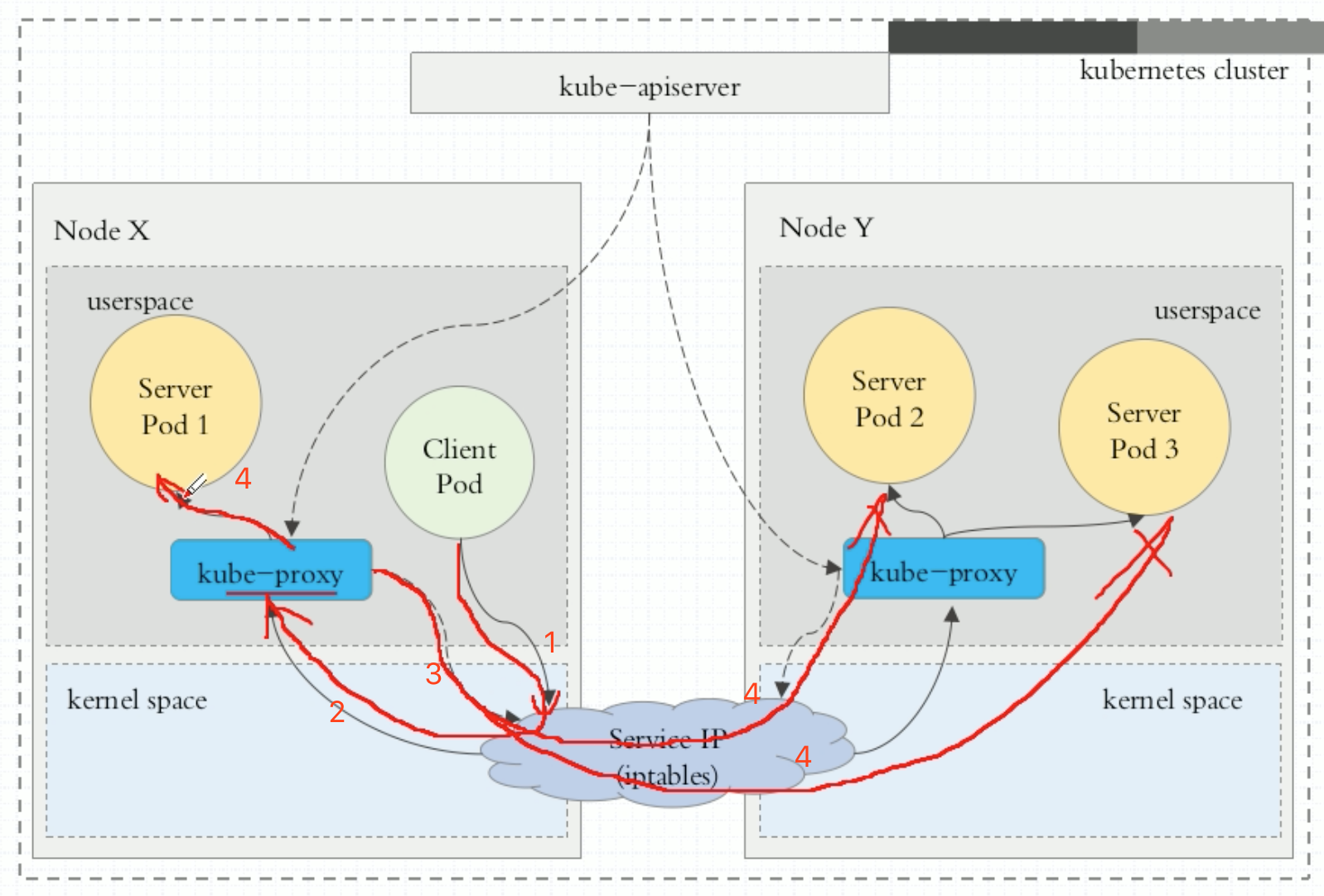
iptables
客户端IP请求service时直接请求service IP,这个请求被本地内核空间的service规则所截取,进而直接调度给相关的后端Pod。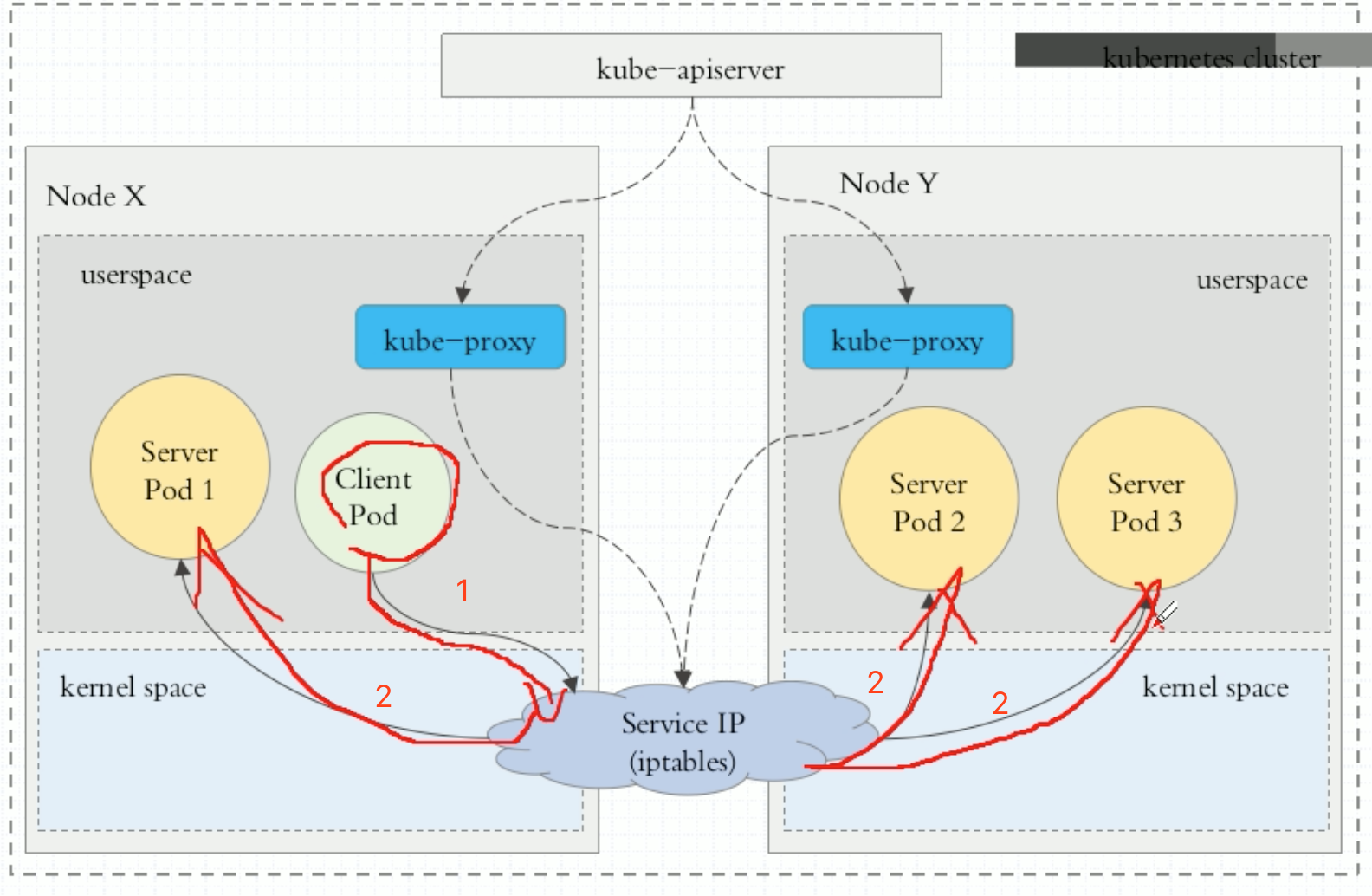
ipvs
client请求到达内核空间后,直接由ipvs规则来调度。直接调度给后端的Pod。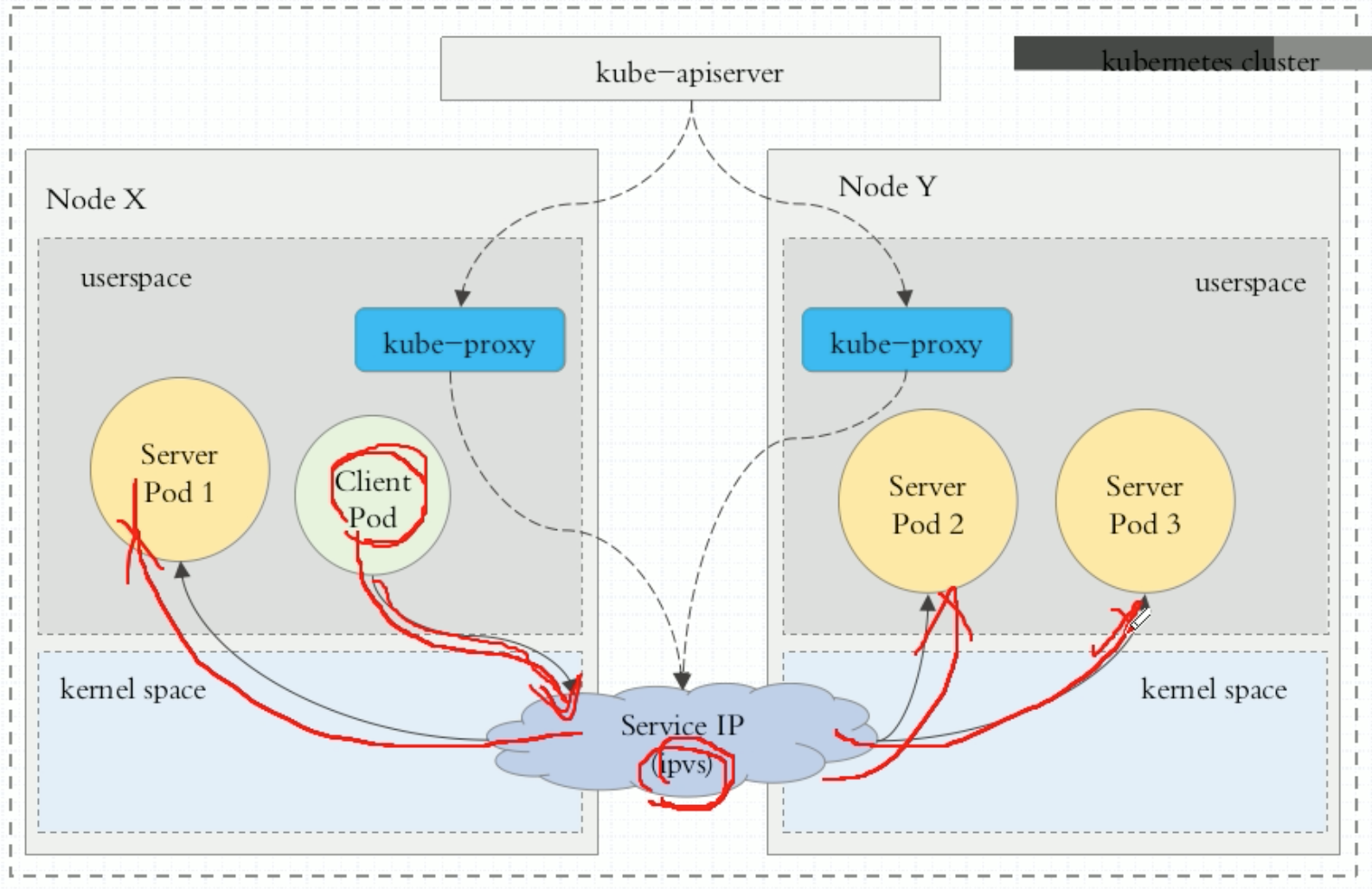
在安装配置Kubernetes集群时,设定service工作在什么模式下,它应该就会生成对应的模式的规则。1.1及之前的版本用的是userspace,1.1-1.10之间用的是iptables,而1.11默认使用ipvs。当然如果安装时没有激活ipvs,它会自动降级为iptables。
如果某个service背后的Pod资源发生改变了,比如Pod多了一个,这个Pod的信息会立即反应到apiserver上,apiserver会把信息更新到etcd上,kube-proxy会检测到apiserver上这个变化,并将该变化立即转为iptables规则。转换是动态的,而且是实时的。
kubernetes集群安装完成后,默认有个service的名称叫 kubernetes。集群内的各种Pod需要和Kubernetes集群的apiserver联系时都要通过这个地址联系的。
Service字段解释
Service简称svc。
依然是这5个一级字段。
svc.spec下有几个重要字段:
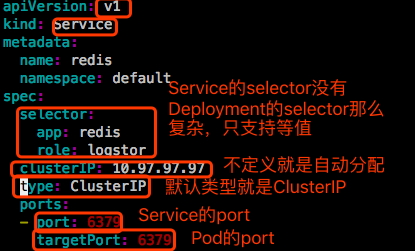
- ports <[]Object> Service的哪个port和后端Pod的端口建立关联关系。
- selector
- clusterIP
集群IP,这个IP是动态分配的。可以用这个字段定义固定地址。但是给定后,就无法修改了 - type
service类型。如果有必要的话,要指定type。ExternalName, ClusterIP, NodePort, and LoadBalancer。Defaults to ClusterIP. - ClusterIP:分配一个集群IP地址,仅用于集群内通信
- NodePort:接入进群外部的流量
- LoadBalancer:这表示把k8s部署在虚拟机上,而虚拟机是工作在云环境中,而云环境支持LBAAS,叫负载均衡级服务的一键调用,创建软负载均衡器使用的
- ExternalName:把集群外部的服务引入到进群内部来
svc.spec.ports
- name
port的名称 - nodePort
指定节点上的端口,这个不用定义,因为只有service的类型是NodePort时,节点端口才有用 - port
-required- 这个service对外提供服务的端口 - protocol
不指定就是TCP - targetPort
Pod的端口
Service示例
示例1:ClusterIP类型的Service
|
|
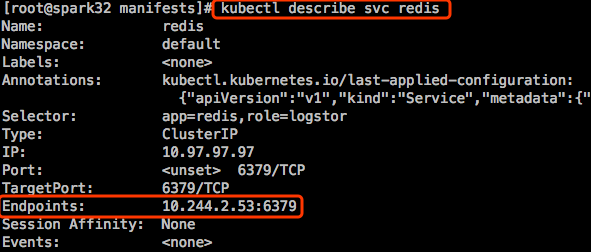
其实service到pod是有一个中间层的,service不会直接到pod。service是先到endpoints。endpoints也是一个标准的Kubernetes资源对象,endpoints就是地址+端口。然后再由endpoints关联至后端的Pod。只不过作为我们来讲,可以理解为是从service直接到pod。事实上我们可以手动为service创建endpoints资源。
service创建完,只要k8s集群内的dns附件存在,那么我们就可以直接解析服务名。每个service创建,都会在集群dns中动态添加相应的资源记录。
资源记录: SVC_NAME.NS_NAME.DOMAIN.LTD.
集群的默认域名后缀:svc.cluster.local. 如果我们没有改这个特定域名后缀,每一个服务创建后对应的都是这种格式。比如:
redis.default.svc.cluster.local.
示例2:NodePort类型的Service
字段nodePort可以不指定,但是如果指定请确保指定的每一个节点的nodePort都不能被占用。这个端口默认是动态分配的,从30000-32767之间。当然如果你确保两个节点上的80没被占用,你在清单文件中指定80也是可以的。
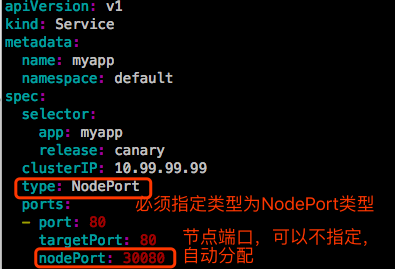
Service的80端口映射到节点的30080端口。
集群外通过节点IP和PORT访问服务:
示例3:LoadBalancer类型的service
假如你在阿里云上买了4个虚拟机,同时也买了LB服务LBAAS。在这4个虚拟主机上部署k8s集群,这个k8s集群可以与底层的公有云IaaS的api做交互,k8s具有这样的能力。调的时候能够去请求创建1个外置的负载均衡器。1个master,3个node。3个node上都使用同一个nodePort对外输出服务,它会自动请求底层IaaS的api,用纯软件的方式做一个负载均衡器,并且为这个负载均衡器提供的配置信息是这3个节点的节点端口上提供的服务。这样外部客户在访问时直接访问LBAAS,由它来调度到3个nodePort上。nodePort先代理给service,由service在集群内部负载均衡至Pod。OpenStack也支持LBAAS。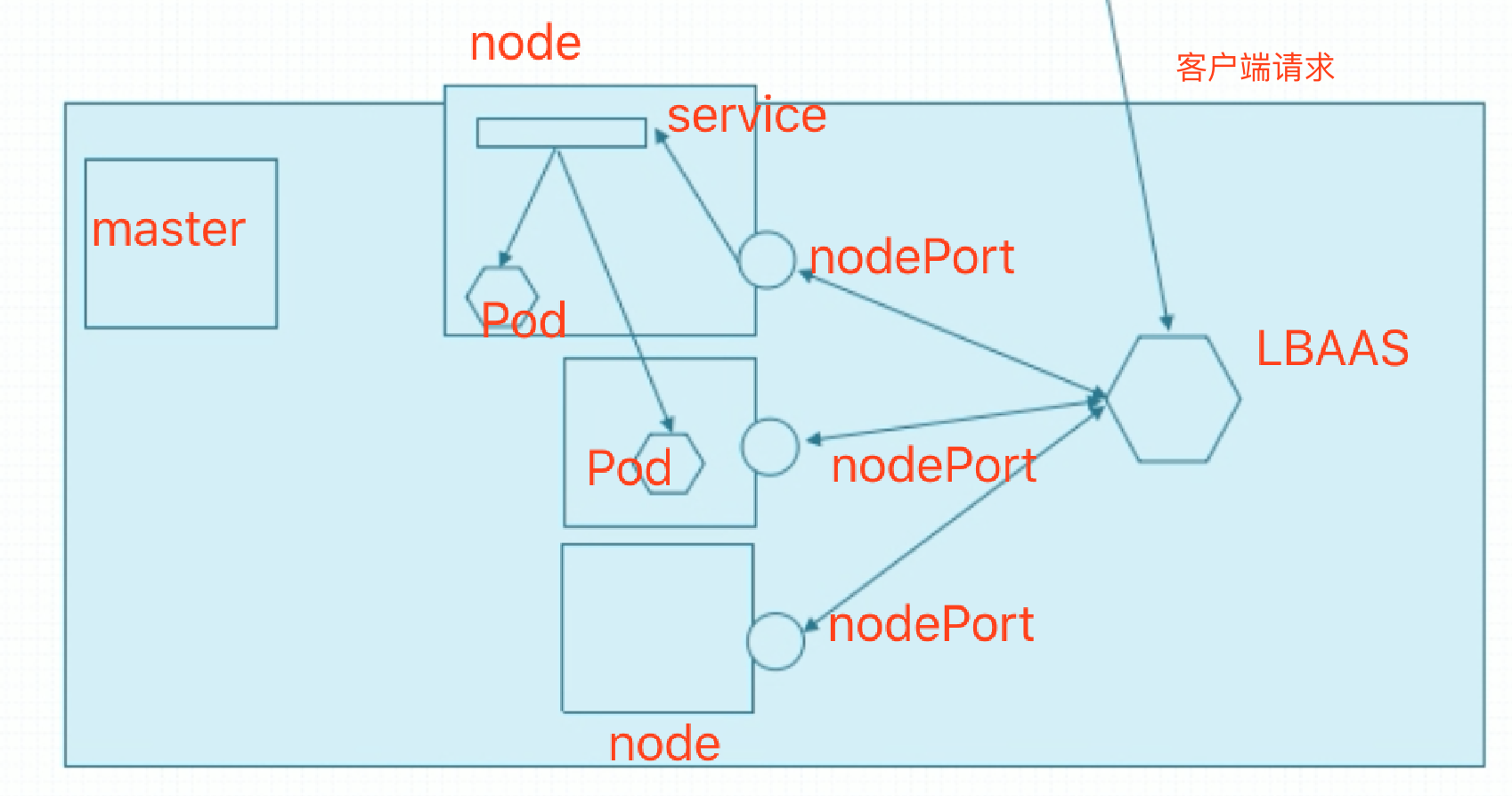
示例4:ExternalName类型的service
集群中建立的Service的endpoints不是集群内的Pod,而是集群外的服务。
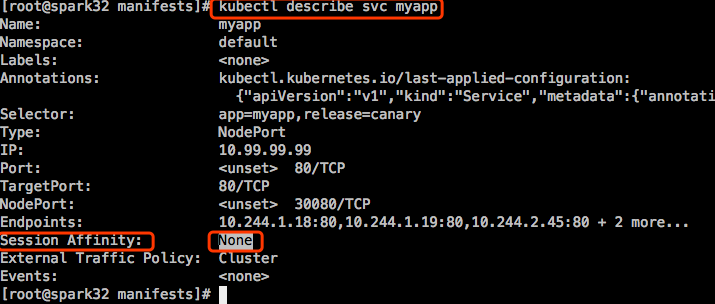
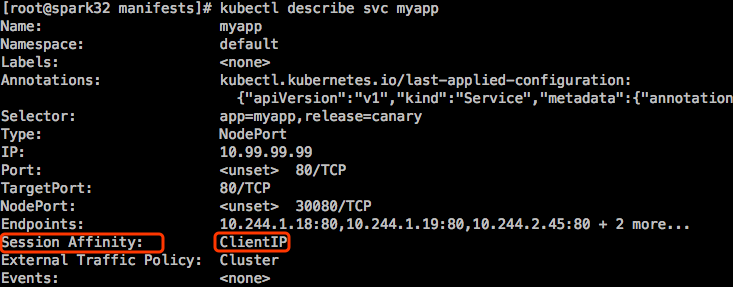
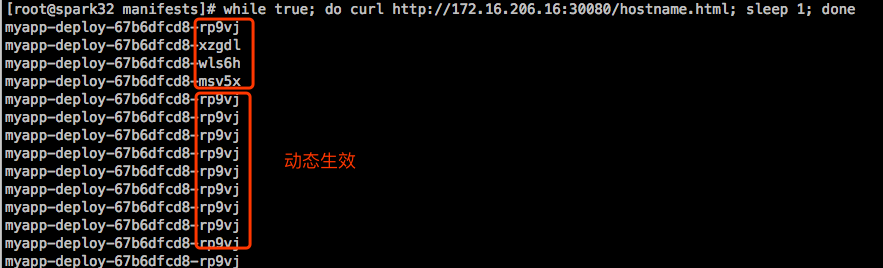
Service会话绑定
service在实现负载均衡时还支持 sessionAffinity。默认是None,不做会话绑定。
headless Service
Pod也是有名称的,Pod的主机名就是Pod的名称。所谓无头,就是去掉service对应的clusterIP,解析service时解析到后端Pod的IP。这种service就叫headless service。
|
|
Valid values are “None”, empty string (“”), or a valid IP address. “None” can be specified for headless services when proxying is not required.
|
|
看看解析情况:
直接解析到了Pod的地址。看看此前创建的Service myapp的解析:
它就是解析到了Service的IP。
@10.96.0.10表示不使用本地的dns解析,10.96.0.10是集群CoreDNS的地址。
StatefulSet用到的就是headless Service。
Service的问题
service有个问题,通过nodePort访问时需要做两次转换,另外无论是iptables还是ipvs,都是四层调度。因此如果我们要建一个https服务的话,每一个myapp都得配置为https的主机,因为四层调度是没有办法卸载https会话的。Kubernetes还有一种引入集群外部流量的方式。叫Ingress。
Ingress资源是一种七层调度器,因为它利用一种七层Pod来实现将外部流量引入到内部来。事实上它也脱离不了service的工作。可用的解决方法有Nginx、Haproxy等。还有Traefik。
k8s之上调度用的更多的还是Nginx。