
什么是存储卷
大多数和数据存储相关的应用和有状态应用都是需要持久存储数据的。容器本身有生命周期,为了使得容器将来终结后我们可以把它删除,甚至是编排到其他节点上运行,意味着数据不能放在容器自己的名称空间中。
在k8s中,Pod是运行在某个节点上的,只要不出故障,就一直会运行在这个节点上,节点故障了才会调度到其他节点,只要节点不故障,是不会走的,无非就是重启重启而已。这里就有两个问题了,一旦这个Pod故障了被删除,或者节点故障了,此时有可能编排到其他节点上了,为了突破Pod生命周期受限这种现状,我们需要把数据放在Pod自有文件系统之外的地方。
我们此前在单独使用docker时,使用存储卷,相当于把容器中的某一目录与节点上某一目录关联起来,随后容器内该目录存储的数据都存到了节点上了。当我们删了容器,在重建容器,只要这个存储卷不受影响,那么数据是没有问题的,在一定程度上拥有了持久功能。
但是这个问题在k8s上不能这么来操作,k8s是一个集群,由调度器负责调度,Pod被删掉了可能会被调度到其他节点,所以这种在节点级帮忙提供存储卷的方式来持久存储数据的逻辑在k8s上,只能说只有一定程度上的持久性,不是真正意义上的持久性。应该使用脱离节点而存在的存储设备。
为此,k8s提供了能应付各种不同类型的存储卷让我们来使用,没有持久、半持久、或真正意义上的持久功能。对于Pod来说,Pod内的多个容器可共享访问同一组存储卷,因为对k8s来讲,存储卷不属于容器,而属于Pod。在容器中挂载存储卷,如果Pod中两个容器都挂载了某个存储卷,就相当于两个容器共享数据了。Pod底层有个基础容器,不启动,靠一个独特的镜像来创建的,叫pause。所有的Pod,其网络名称空间、存储卷之类的都是分配给这个Pod的,Pod中运行的主容器是共享这个镜像的网络名称空间的,容器挂载存储卷其实是挂载这个容器的存储卷的。所以叫基础架构容器。
在Pod上使用存储卷,实际上也就是这个pause容器有了存储卷,而这个容器有存储卷,只不过是这个容器和宿主机目录建立了关联关系。而宿主机目录如果是节点本地的,那么它就随着宿主机而终结了,因此宿主机这个目录为了真正实现持久性,它应该也不是宿主机本地的,而是宿主机挂载的外部存储设备上的存储卷。当然如果这个宿主机的目录没挂载,那就是节点本地的了。只要节点不宕机,数据就是持久的。但是跨节点存储,只能使用脱离节点本地的网络设备。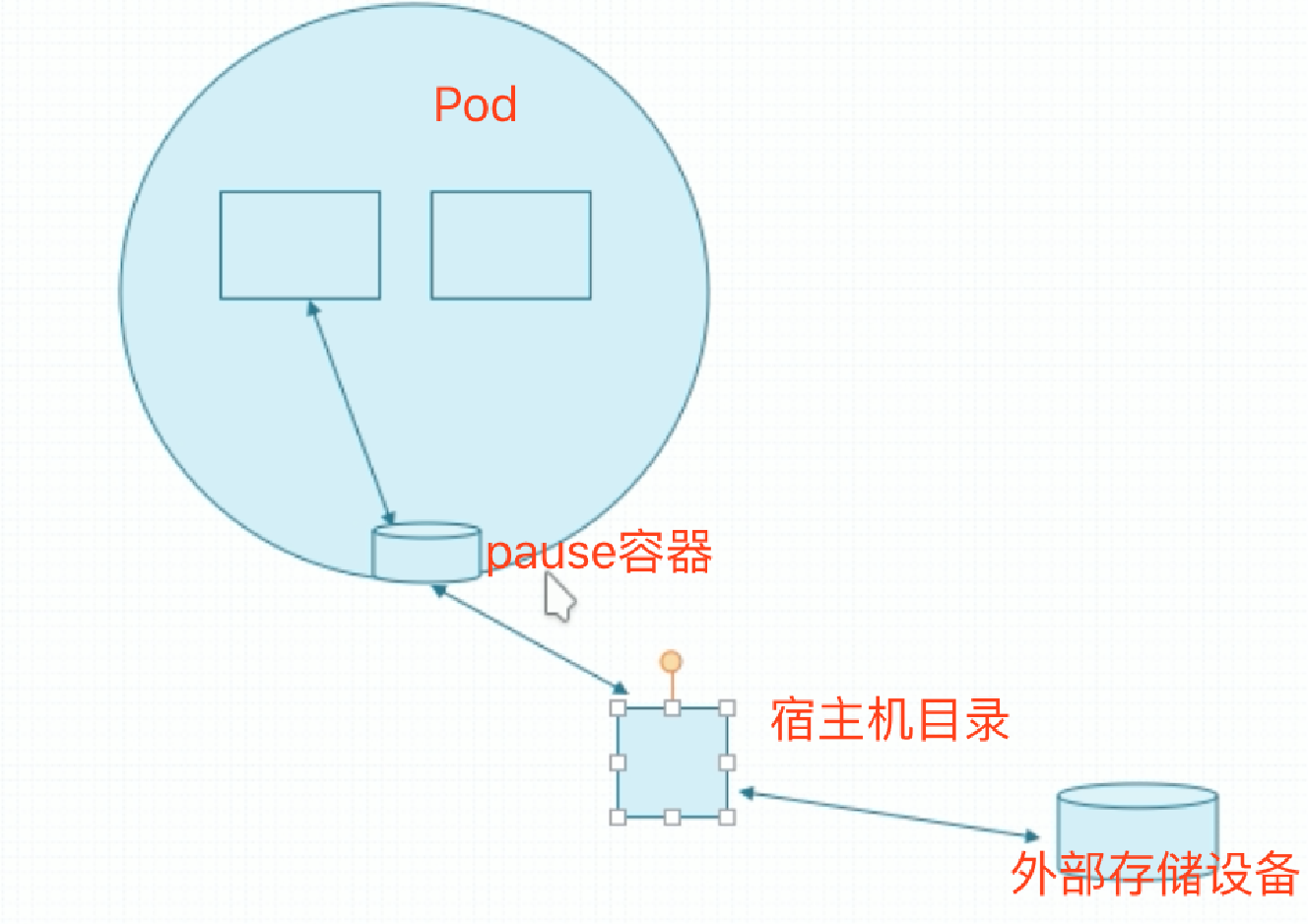
Kubernetes存储卷分类
emptyDir
给Pod分配一个存储卷,存储卷只要节点本地,当Pod被删除,节点上存储卷也会一并被删除。这个不是为了持久而设计。只是用来做临时目录使用的。
hostPath
主机路径。直接在宿主机找一个目录,与容器建立关联关系。也不具有真正意义上的持久性。如果需要真正以上的持久性,则需要连接网络连接存储。大概分3类:
(1)SAN(存储区域网络,比如iSCSI、FC协议)、NAS(网络附加存储,比如nfs协议、cifs协议以及http协议)
(2)分布式存储:或是文件系统级别、或者块设备。
文件系统级别:glusterfs、cephfs
块级别:rbd
(3)云存储:亚马逊的EBS(弹性块存储)、Azure Disk。
pvc
持久存储卷申请,简称pvc。从某种意义上来讲,它不是一个存储卷。以rbd为例,当你定义使用rbd类型的存储时,你需要定义很多相关的参数,这需要你对这个存储很熟悉。这会阻断一大部分用户来用k8s。怎么转换成傻瓜的形式来使用?pvc就是干这个事情的。
当需要创建一个存储卷时,你只需要告诉我,“我要来个存储卷”,所以叫存储卷创建申请。你不要管它底层存储系统是什么,你只需要说“我就需要这么多”就行。指定告诉它比如说需要个5g的存储空间,而不用管它那个存储到底放在哪个系统上。这叫存储及服务。
让Pod创建和底层存储解耦。关键是和pvc建立关联关系,而pvc关键是和pv建立关联关系,而pv关键是和存储系统建立关联关系。解释如下:假如一个Pod创建调度到某个节点上,我们在Pod上定义一个pvc,它是一种存储卷类型,pvc要关联到当前这个Pod所在名称空间真正存在的pvc资源,这个pvc只是个申请,申请要与pv建立关联关系,pv是真正存储系统之上的一段存储空间,pv与后端存储建立关联关系。但是这个pvc与哪个pv建立关联关系时,怎么可能有个pv放在那等你来用呢?要做到这一步,用户在创建申请之前,先提需求,然后后端存储工程师或者k8s管理员把这些pv创建好。但是如果是公有云呢?有很多租户在上面跑着,压根不知道他们什么时候要创建pv。因此如果要做到按需创建,我们pv也不建了,我们把所有的存储空间抽象出来,抽象为一个抽象层,叫存储类。当用户创建pvc需要用到pv时,它能够向存储类申请说,“你帮我创建出来”,存储类会帮它生成刚好符合用户请求大小的pv来,并让二者建立关联关系。像这种pv由用户的请求触发而动态生成,我们称为pv的动态供给。而这里需要依赖一个前提:要定义好存储类。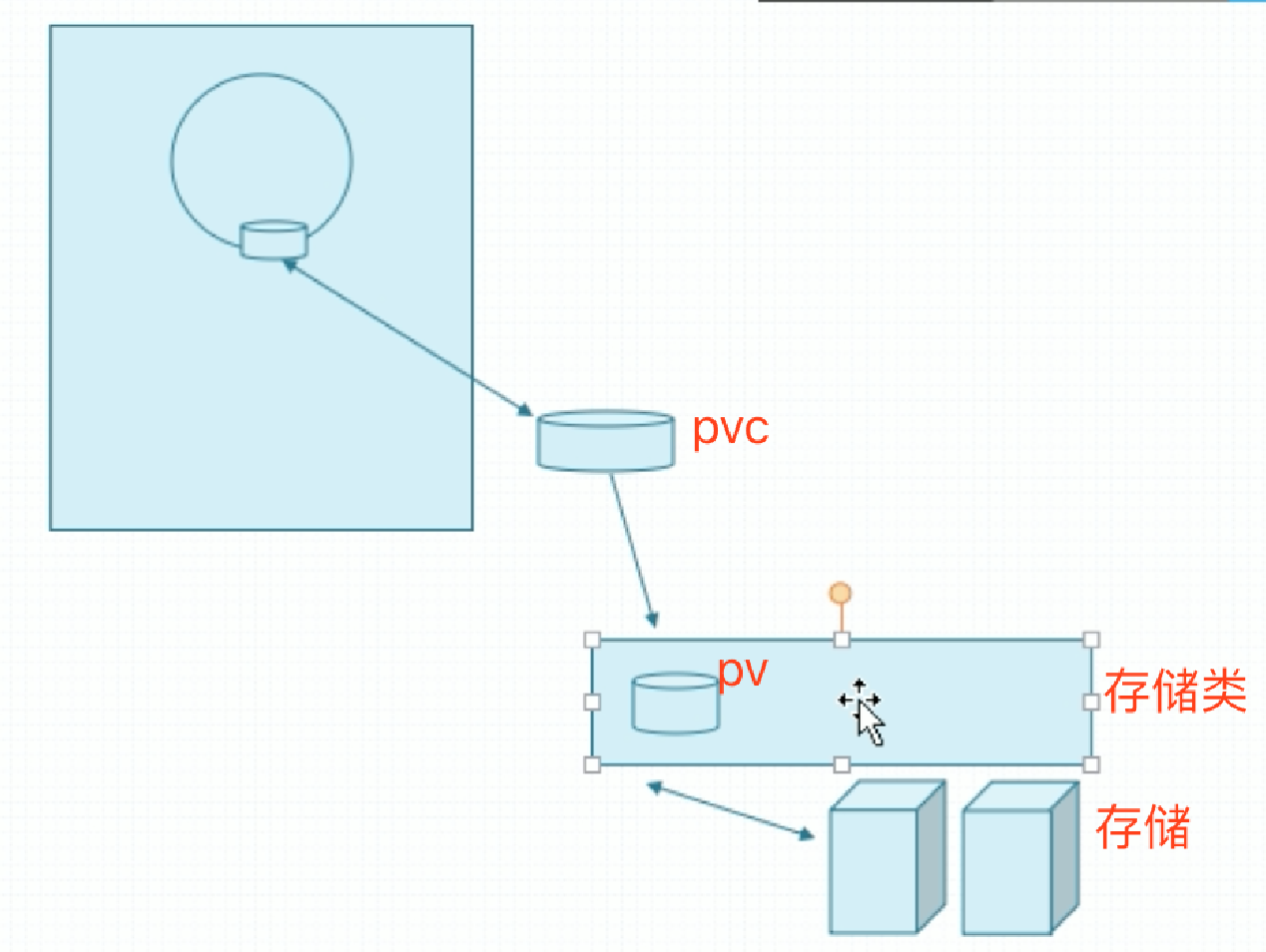
什么叫存储类?存储按照其综合服务质量可以分为好几个级别,有的又慢又笨,称为Bronze存储,有的速度算中间,我们对性能没有太高要求,称为Silver存储,而有些特别快,ssd之类组成的,称为Gold存储。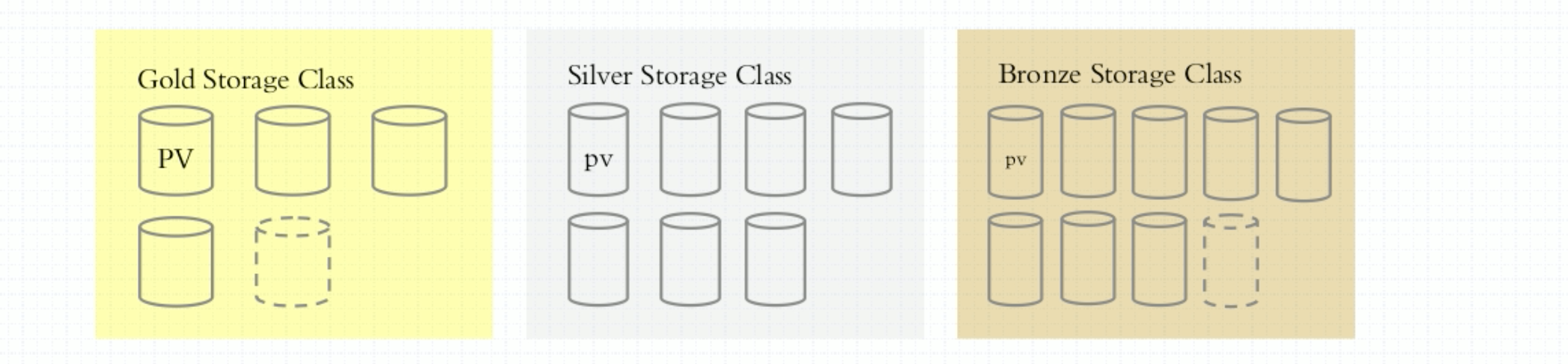
如果我们自己是一个对于存储系统非常了解的人,创建Pod时可直接使用存储空间,如果你不是特别了解,或者我们将来有很多用户、终端用户对于存储技术知之不多的话,那么这个时候我们就应该尽可能地给他们做成动态供给的方式,让他们使用pvc来使用。
存储卷示例
存储卷只是在Pod上定义的,容器中要想使用还得挂载和绑定。第一在Pod中要定义volume,这个volume要指明关联到哪个存储设备上去的,第二要在容器中使用volumeMounts,然后你才能使用。
emptyDir
emptyDir不需要依赖任何外部设备。
查看定义emptyDir的相关字段:
|
|
|
|
查看容器中挂载存储卷的相关字段:
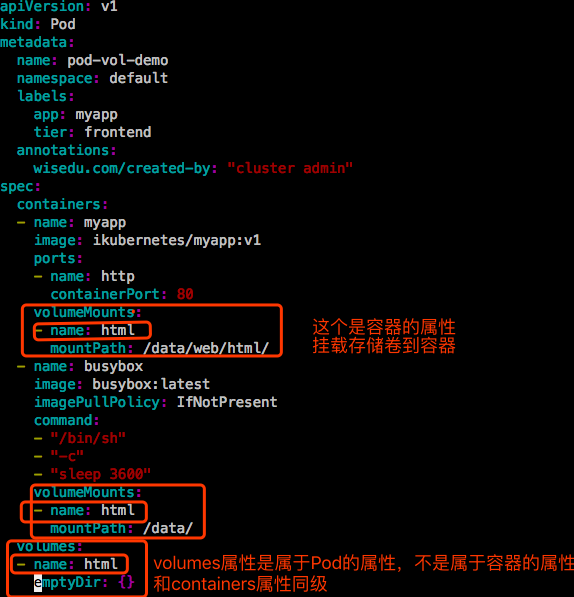
【示例1】:定义个emptyDir类型的存储卷,并让Pod内的容器挂载这个存储卷。
1.先定义Pod的存储卷。emptyDir的两个属性medium和sizeLimit可以都不指,都为空,使用默认值,磁盘空间,大小不限制。空代表了一个映射,用{}。因为要映射数据,就是键值,键值。
2.然后定义容器挂载这个存储卷,哪个容器用,哪个容器挂载。
进入Pod中的busybox容器:
接着进去Pod中的另一个容器myapp:
【示例2】:一个Pod中两个容器,一个容器是主容器,另外一个容器辅助容器。辅助容器每隔2s帮我们在一个共享的存储当中往一个网页文件添加新内容,主容器能够用这个新内容加载后响应给请求者。
【注意】:是先挂载存储卷,后启动主容器。
|
|
访问:每隔2s生成一行新的数据。
但是emptyDir有个特点,只要把Pod删除了,哪怕Pod重建在同一个节点上,数据也不会继续存在的。emptyDir的生命周期同Pod。
gitRepo
把git仓库当做存储卷来使用。并不是Pod真正把git仓库当存储卷来使用,它只不过是把git仓库中的内容,比如说找github或者私有的git服务器,git仓库里一般有数据,可以把网站的源代码放在仓库里,而后当Pod创建时,会自动地连接到这个仓库之上,但是这个连接要依赖于宿主机上有git命令来命令,因为它是基于宿主机来决定的,让宿主机把整个仓库克隆到本地来,并且把它作为存储卷定义在Pod之上。但是,gitRepo是建立在emptyDir之上的。
gitRepo本质上来讲还是emptyDir,也是个空目录,对Pod而言也就是上来建立个空目录,仍然是一个空的存储卷,但是所不同的地方在于,要把指定的仓库的内容clone下来,并且扔到这个空目录里面来。因此主容器就可以把这个用户当做服务用户的数据来源。但是你做的修改是不会同步到git仓库里面去的。如果在你的Pod运行过程中,git仓库发生改变了,Pod内存储卷的内容也不会改变。这种持久需要你本地推送到远程仓库才行。
hostPath
把Pod所在的宿主机之上的、脱离Pod中容器的名称空间之外的、宿主机的文件系统的某一个目录与Pod建立关联关系。在Pod被删除时,这个存储卷是不会被删除的。所以只要同一个Pod能够调度到同一个节点上来,在Pod被删除以后,重新调度过来以后,对应的数据依然是存在的。如果要使用hostPath,就要指明在宿主机上哪个路径,万一宿主机上这个路径默认不存在,到底要不要新建取决于type字段。
访问:https://kubernetes.io/docs/concepts/storage/volumes#hostpath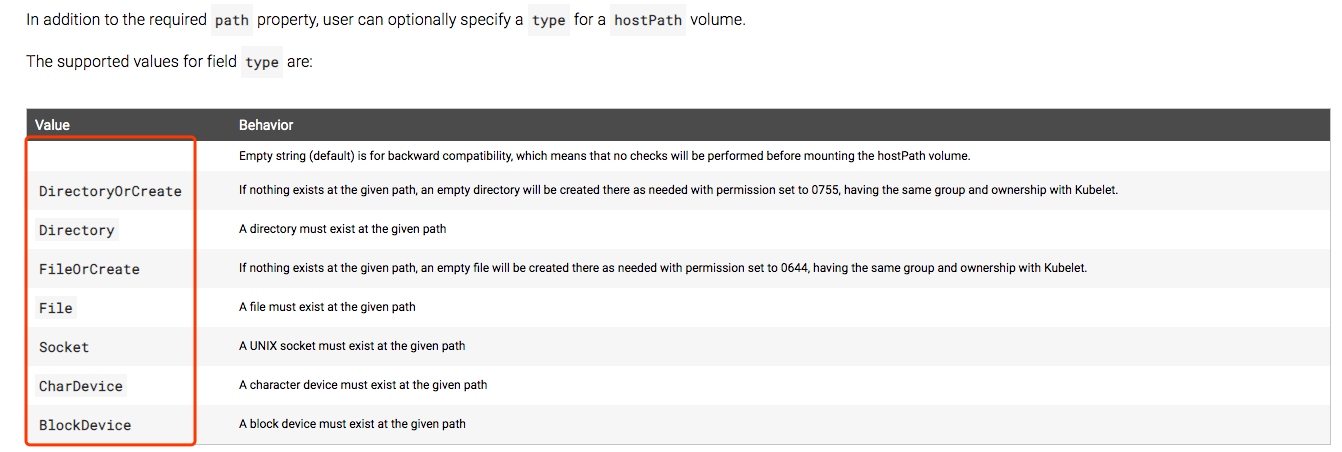
- 空:为了兼容老版本的
- Socket: 必须是一个socket类型的文件
- CharDevice:必须是一个字符类型的设备文件
- BlockDevice:必须是一个块类型的设备文件
【示例】:hostPath示例。
在k8s集群的每个node节点上都创建如下的目录和文件,因为我们不清楚这个Pod会被调度到哪个节点上:
在index.html中写入当前主机的主机名。
|
|
现在我们来删除这个pod,在重新创建这个pod,看看存储卷是否依然存在。
但是这种持久只是节点级的持久,如果节点宕机了,数据也就没了。因此跨节点调度时,数据还是会丢失的。
nfs
以NFS为例,做一个共享存储。然后让三个节点挂载这个共享存储。
现在有1个节点:172.20.0.76 作为 nfs server。
将来集群中的node节点 hadoop16、spark17、ubuntu31要将nfs server上的相应目录挂载到本机的,所以要确定这几台node节点支持nfs。
1、安装nfs server
定义共享目录:
|
|
在这个共享目录下创建个文件:
下面手动找个节点去挂载下试试可否挂载:
要确保挂载节点都要能驱动这个存储设备。安装下工具。
|
|
卸载:
【注意】;这里在k8s集群node节点宿主机上不需要挂载,在容器里取挂载这个NFS server导出的目录。
【示例】:nfs存储卷示例。
- path: NFS server上导出的路径。
|
|
|
|
接下来删除这个pod,然后重新创建这个pod,即使这个pod被调度到其他节点,都能正常工作:
假设这里改成新建Deployment,里面有多个Pod,Deployment中template都定义挂载这个存储卷,nfs是否支持多路读写。nfs支持多客户端同时挂载,支持多客户端同时写操作。因为nfs server有持锁能力。
虽然这使得Pod有了真正意义上的持久能力,但是万一nfs server宕机了?数据一样会丢失,nfs不是一个分布式存储,没有冗余能力。应该使用glusterfs、ceph(rbd、cephfs)这样的自建的分布式存储,再不然使用云端存储。ceph可以直接提供restful的接口给k8s用。
pvc
我们上面在使用NFS的时候,就得指定NFS的共享路径、NFS服务器地址之类的,所以很多要使用Pod的人,比如就是要运行一个应用程序,这个程序就要持久存数据,假设用户能做出镜像来,但是还得让用户去懂各种各样的存储,这是有点难为用户了。因此我们可以把这个所谓的存储功能隔离开来。就像k8s向用户提供所谓的运算能力,用户不用担心自己的应用程序怎么被启动的,运行在哪里,因此简化了部署操作的过程。存储能力也是这样子的,我们定义成生产者-消费者模型,有人去生产存储空间,有人去消费就行,不需要了解背后是什么。现在我们要用存储空间,得自己先去做,找个nfs服务器,创建nfs服务,提供存储空间。
能不能这样子,让存储工程师来管理存储服务,让k8s管理员来管理k8s。作为用户来讲,我们只需要创建Pod。如果Pod中需要用存储,我们只需要说“要用存储”就可以了,这就是所谓的pvc要帮我们达到的效果。但是pvc的使用逻辑比较复杂。我们可以这样来组织我们的存储,我们在Pod中定义pvc类型的存储卷,告诉要用多大的存储卷,而pvc类型的存储卷必须与当前名称空间中的pvc建立绑定关系,而且pvc必须pv建立绑定关系,而pv应该是某个真正存储设备的存储空间。所以pv和pvc这两个东西是k8s之上的抽象的、但也算是标准的资源。pvc是一种资源,pv也是一种资源,他们的创建方式和创建Ingress、Service几乎没有什么太大的区别。它们就是标准的资源。
但是用户需要怎么做呢?存储工程师把存储这一端,每一个存储空间先划分好,k8s管理员需要把每一个存储空间映射到系统上做成pv,pv是划分好的一个个大小的存储空间,一个pvc与pv建立关联关系后,完全占有这个pv。用户就自己定义Pod,在Pod中定义使用pvc就可以了。pvc可以是用户去定义,也可以是k8s管理员去定义,pvc是属于当前名称空间的资源。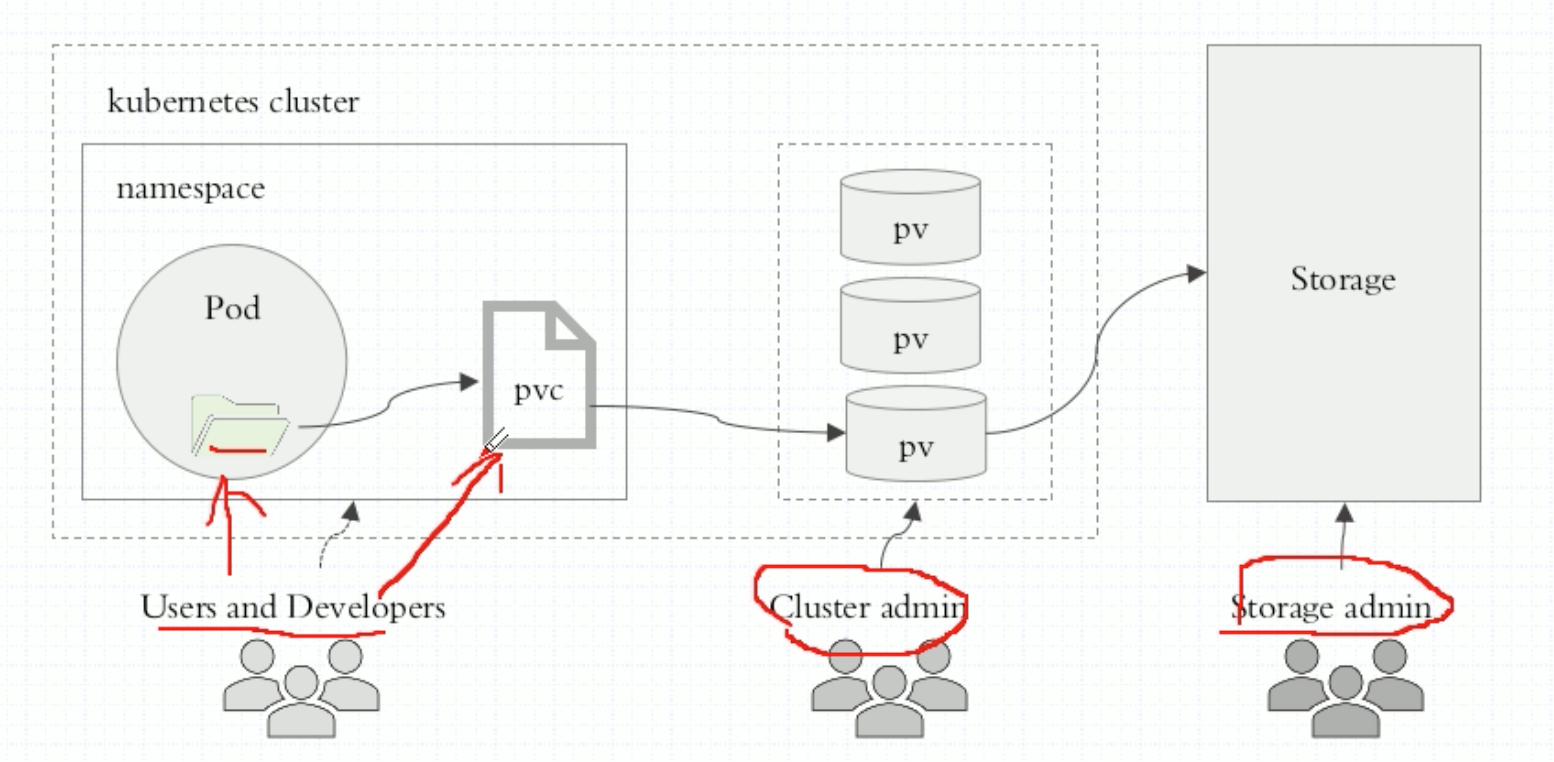
|
|
pvc也是标准的k8s资源。下面看看pvc定义使用的一些字段:
- accessModes <[]string>
访问模型,无非就是支不支持多人同时访问之类的。
https://kubernetes.io/docs/concepts/storage/persistent-volumes#access-modes-1 - resources
- selector
- storageClassName
存储类名称,后续在谈。 - volumeMode
后端存储卷的模式。 - volumeName
卷名称,后端persistentVolume(pv)的name。精确选择,就是要绑定哪个pv。也可以用选择器来选定。
pv也是标准的k8s资源。
而 pv.spec 与我们定义存储卷时的 pods.spec.volumes 一模一样。只不过把此前应该定义在Pod上的,现在定义在pv上了。
创建pvc后,系统就会去找符合等价的pv,找到就绑定,找不到就会一直pending,挂起。
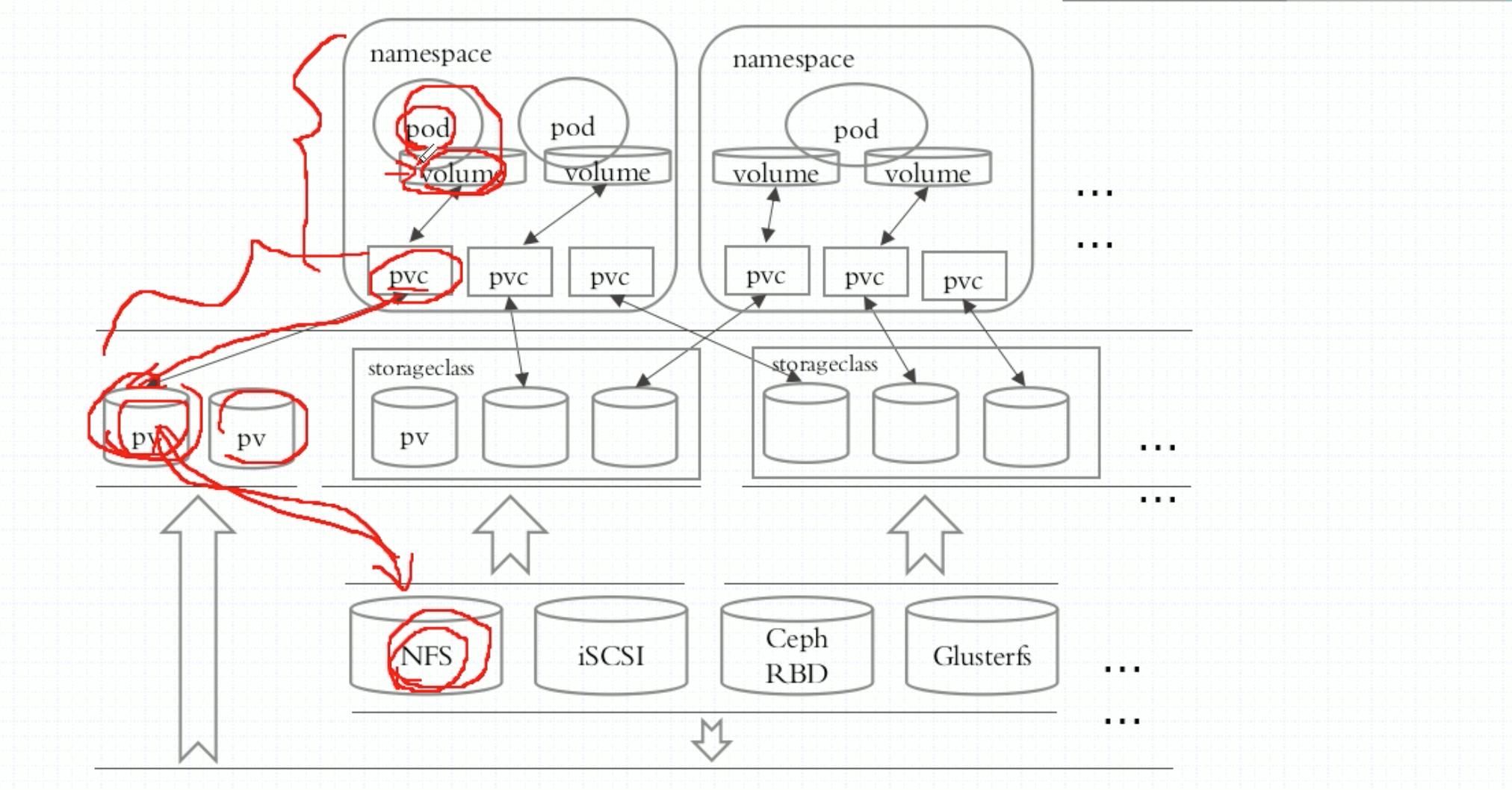
存储工程师将存储划分了很多个存储空间,然后k8s集群管理员把这些存储都引入到集群中来,定义成pv。随后k8s用户创建Pod,在创建Pod之前,要先创建pvc,这是个claim,这个claim表示要在当前k8s集群中找一个能符合我们条件的存储空间来用。而后系统就在pv里面找哪个合适,然后分给它。pv和pvc是一一对应关系,意思是说如果某个pv被某个pvc占用了,意味着这个pv就不能被其他pvc占用了。会显示这个pv的状态是binding。但是一个pvc创建以后,这个pvc就相当于一个存储卷了,这个存储卷却可以被多个Pod所访问,多路访问。到底支持不支持多个Pod同时访问,你要定义这个pvc的访问模式。因此我们在创建pvc的时候,最好底下有匹配的pv存在,如果不存在就绑定不了了,绑定不了,pvc的状态就是pending。直到有符合条件的pv出现。
【示例】:我们在nfs上先准备几个空间,然后把它们做成pv放在那里,然后用户才能使用pvc去申请绑定和使用它们。
先把上面的示例中的Pod删除了:
在nfs server服务器上执行如下操作:
我们先把这5个存储定义成pv。正常使用的场景中,这部分工作是k8s管理员做的。
定义一个nfs格式的pv:
重要字段:
- accessModes <[]string>
AccessModes contains all ways the volume can be mounted. More info:
https://kubernetes.io/docs/concepts/storage/persistent-volumes#access-modes
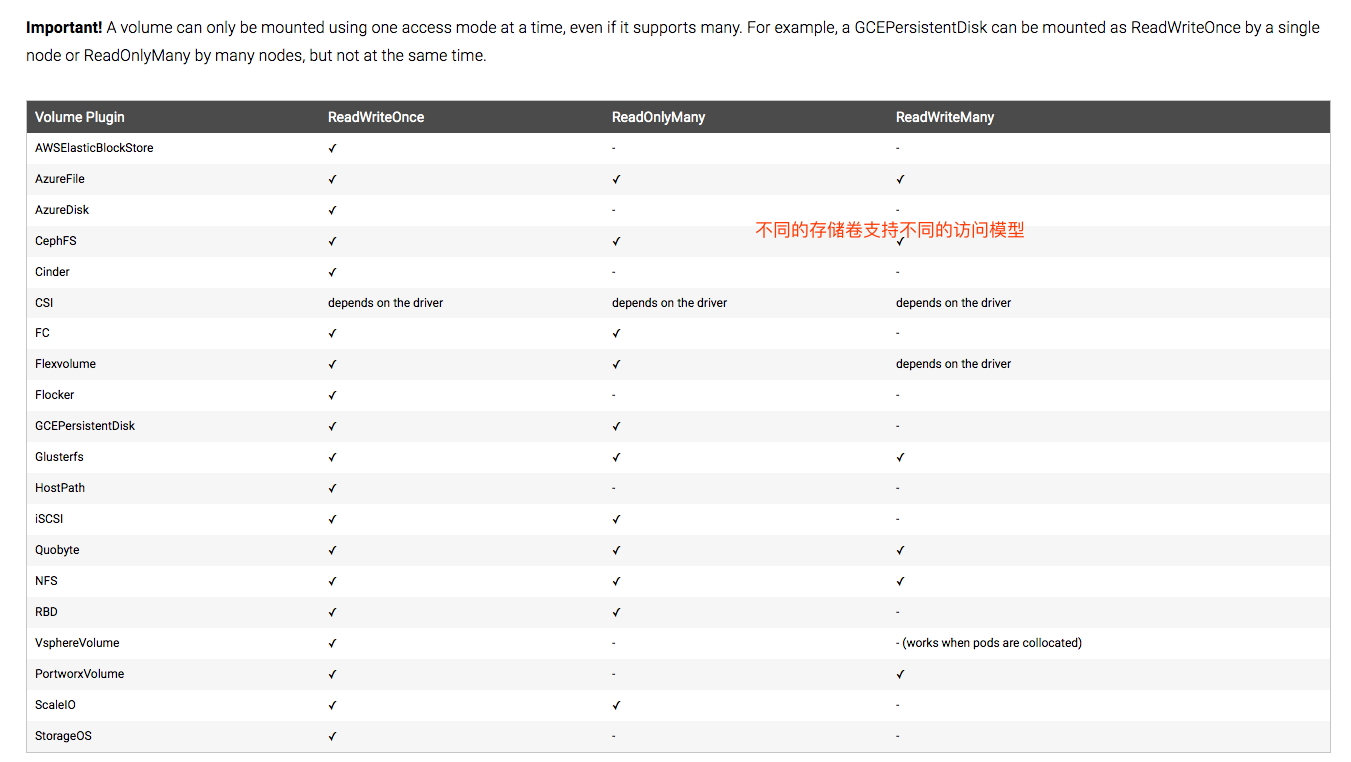
看表中,NFS这3种模型都支持。accessModes 是个列表,意味着我们可以同时定义支持3种模型。但是即使支持多种访问模型,但是挂载时只能选定一种模式。
- capacity
A description of the persistent volume’s resources and capacity. More info:
https://kubernetes.io/docs/concepts/storage/persistent-volumes#capacity
对于存储空间来讲,它其实只有1路能输出的资源限制功能,叫Storage,无非就是存储空间是多大。支持这么几种单位。
我们使用Ki、Mi,Gi,不要像硬盘生产厂商那样子,说是500GB,是以1000为单位的,拿回来一看可能只有480GB。
|
|
【注意】:定义pv的时候一定不要加名称空间,因为pv是属于集群级别的,不属于名称空间,属于整个集群。但是pvc是属于名称空间级别的。namespace不能嵌套,namespace也是属于集群级别的资源。所谓集群级别的,意思就是不能定义在名称空间中。
|
|
RECLAIM POLICY:回收策略。
比如说某个pvc和某个pv绑定了,在里面存数据了,但是后来这pvc被删了,此时绑定就不存在了。一旦绑定不存在以后,这个pv怎么处理?它里面还放着数据呢。
- Retain:表示保留。pv默认就是这个策略。
- Recycle:回收,表示把里面数据都删了,pv给其他pvc绑定。
- Delete:解绑后,把pv也删除了,当然数据也没了。后面这两种都很危险。
下面定义pvc,然后给pod使用。
重要字段解释:
- accessModes:必须是想绑定的pv的accessModes的子集。
- resources:pv的值要大于等于这个值才能是候选之一的pv
|
|
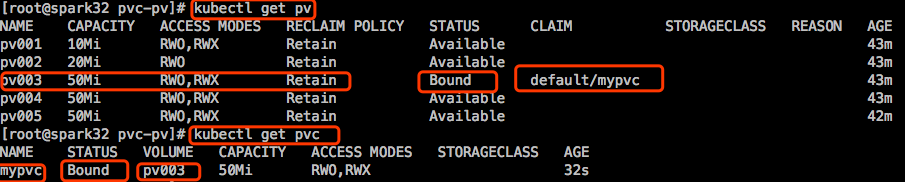
将来一般删Pod时不会删pvc,只要pvc不删除,pv就算你定义的策略为回收或删除,pv也会一直在那,数据也在那。pvc不属于节点,存储在etcd中的,只要etcd不出问题,pvc就不会有问题。k8s资源,只有Pod是需要运行在节点上的,所有的其他资源基本都是保存在apiserver的存储,叫集群状态存储etcd中。
【注意】:
- 当pvc被Pod挂载时,我们直接删除pvc是删除不了的,除非先删除相应的Pod。
- 假设pv的回收策略是Retain,当删除了pvc后,pv状态会从Bound变成Released,数据依然在pv对应的存储空间上。虽然 pv 中的数据得到了保留,但其 PV 状态会一直处于 Released,不能被其他 PVC 申请。为了重新使用存储资源,可以删除并重新创建 这个pv。删除操作只是删除了 PV 对象,存储空间中的数据并不会被删除。
假如现在要请求使用30G的pvc,目前这5个pv是满足不了条件的,所以得事先联系管理员,告诉他要用这么大,事先帮我们创建好。不然pvc就pending了,从而Pod也就pending了。因此我们要比较灵活地解决这个问题,动态供给。意思是定义好存储类,而后用户创建pvc的时候,动态地给他生成一个pv,pv事先是不存在的。
pvc申请的时候,未必有现成的pv正好符合pvc在申请中指定的条件。因此k8s有意设计了这么一种工作逻辑,能够让pvc在申请pv时,不针对某个pv进行。或者说是针对某个存储类(StorageClass)进行,存储类也是k8s之上的一个标准资源,借助这么个中间层,来完成资源分配。意思是k8s管理员可以事先把存储管理员准备的众多的存储设备,可能有NFS、glusterfs、ceph、rbd、甚至是一些云端的存储,把这些提供好的存储空间,我们事先不做pv,把这些存储资源做一个分类,根据综合服务质量,或者根据哪怕是I/O性能等等,做一个简单的分类。
比如有两个节点的NFS集群,把这两个NFS所能提供的存储空间分为一类,另外我们还有一个ceph的rbd集群,我们将这个集群定义成另一个分类。这就是存储类。我们分类可以根据自己评估的任何维度,甚至地理位置等。然后我们定义出来这个类StorageClass。随后pvc申请pv时,不在针对某个pv直接进行,而是针对存储类来进行。假如说ceph集群我们定义为Gold StorageClass,NFS集群定义为silver StorageClass。我们向金牌存储类中申请,就在金牌存储类中给pvc动态创建一个pv来。
对这些存储设备,有一个前提,必须支持restful风格的请求的创建接口才行。比如NFS,我们上面输出了v1,v2,一直到v5。这几个大小都是定义时设定好了,但是pvc在申请时你之前是不知道大小的。存储工程师只提供了存储服务器,或者说是存储集群,在这个存储上没有任何已经划分好的卷,以NFS为例,在NFS server上并没有一个导出的v1,v2… 假设服务器本地有一块硬盘,我们可以把它划分成很多分区来,每一个分区输出一个共享点。但是现状是分区还没创建呢,更别提共享点了。而后我们在NFS前端定义好restful风格的接口,用户可以通过api直接请求,请求什么呢?
1.在磁盘上划分一个刚好符合pvc大小的分区;
2.编辑exports文件,把对应的分区挂载至本地的某个目录上,并且导出。
3.动态创建出一个pv,刚好使用刚才导出的空间。
但是NFS是不支持刚才描述的功能的,只是举例子说明动态供给是怎么工作的。有些存储是支持的,比如ceph。比如我们准备了很多本地的磁盘,大概一共4PB的空间,但是这4PB不是拿来直接用的,将来在划分成子单位,子单位一般叫image。每个image相当于一块硬盘或一个分区。当我们想申请一个20GB的pv时,我们通过ceph的restful接口请求,立即划分成一个大小为20G的image,把它格式化完成,而后通过ceph导出出来,接着在集群中定义成20G大小的pv,接着跟pvc绑定。所以后端存储设备得支持restful风格的管理接口,才能实现动态pv供给的。、
glusterfs也可以。比ceph要简单多。但是glustefs自身不携带restful风格的接口,你得找一个第三方项目在上面补一个restful风格的接口。