
flannel、calico和canel
calico的配置依赖于对BGP等协议的理解,我们这里不去使用calico作为网络插件提供网络功能了,而是把重点集中在calico如何提供网络策略,因为flannel本身提供不了网络策略,而flannel和calico二者已经合二为一了,有个新项目叫canel。可以在flannel提供网络功能的基础之上,在额外提供calico,去服务于网络策略。
calico默认使用的网段不是10.244,calico如果被你拿来作网络插件使用的话,它工作在192.168.0.0网络,而且是16位掩码,分网络时就是192.168.0.0,192.168.1.0这样去给节点分网络。
部署calico
在kubernetes上部署calico有多种方式,在calico官方文档上有详细的介绍。
这里是在kubernetes上安装calico,我们需要参照的安装是: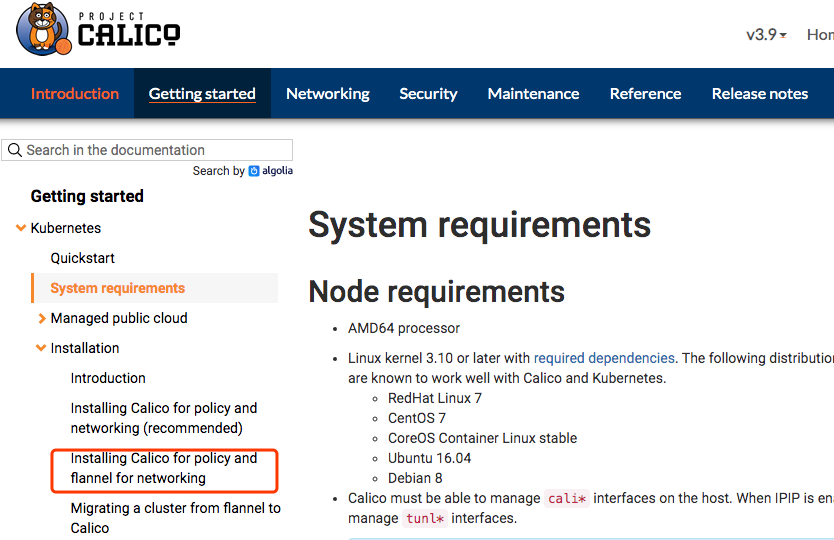
calico对集群中所有的地址分配,自己不记录,而是借助于etcd记录的。这事就比较麻烦了,k8s自己有一套etcd集群,calico也需要一套etcd集群,这样对k8s工程师不是个好事情。后来etcd支持不把数据放在自己专用的etcd中,而是调apiserver的功能,直接把所有的设置都发给apiserver,由apiserver存储在etcd中。因为k8s任何节点,任何功能、任何组件都不能直接写k8s的etcd,必须通过apiserver写,因为主要是确保数据一致性的。
对我们来说最简单的方式是使用k8s的etcd,这也是官方推荐的方式。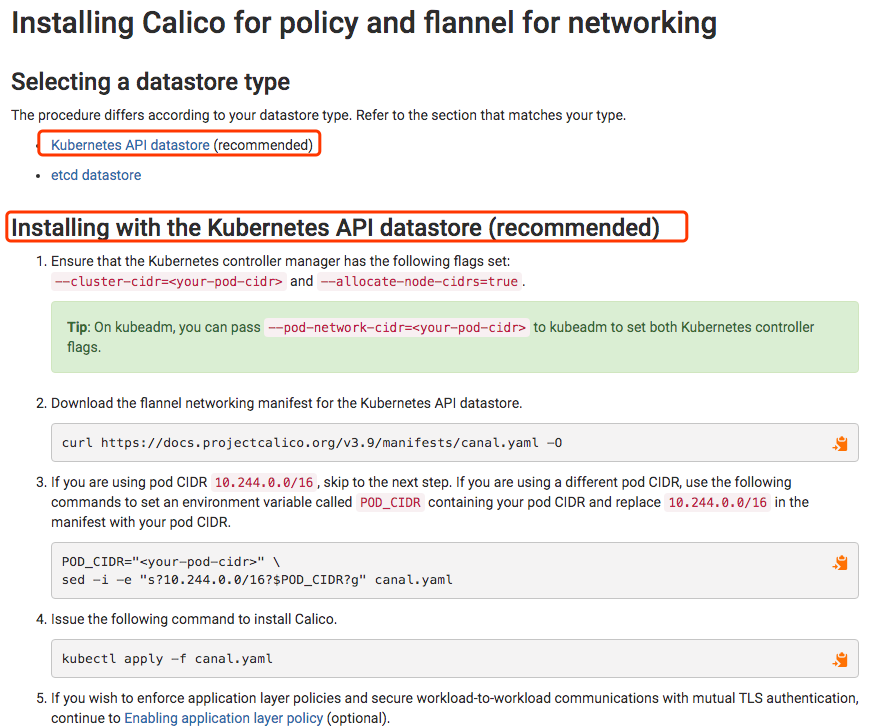
部署canel:
等待pod运行起来。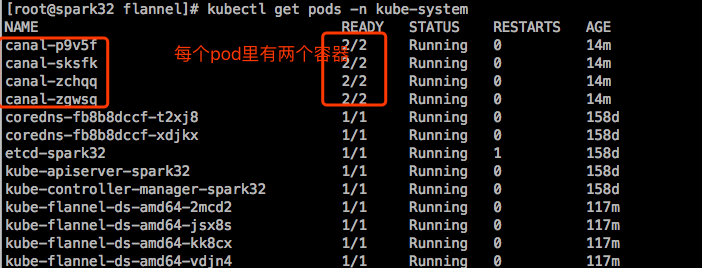
示例
所谓的网络策略(Network Policy),通过Egress和Ingress规则分别来控制不同的通信需求,Egress表示出站,Ingress表示入站。这里的Ingress和此前讲的Ingress规则是两回事。Egress表示Pod作为客户端去访问别人,或者是响应别人,就是自己作为源地址,对方作为目标地址来通信的。Ingress表示自己是目标地址,远程是源地址。
当定义Egress规则时,Pod作为客户端出站的时候去请求别人,自己的地址是固定的,端口是随机的,服务端的地址和端口一般是可预测的;当定义Ingress规则时,对方Pod来请求自己,自己的地址和端口是固定的,对方的地址和端口是没法预测的。所以我们去定义规则时,如果定义的是Egress规则,也就是出站规则,我们可以定义目标地址和目标端口,如果定义的是Ingress规则,也就是入站规则,能限制对方的地址和自己的端口。这种限制是针对哪一个Pod来说的呢?使用podSelector去选择Pod。
将来,如果每个名称空间托管了不同的项目,甚至不同客户的项目,可以给名称空间设置默认策略,在一个名称空间内,所有Pod可以无障碍通信,但是跨名称空间都不被允许。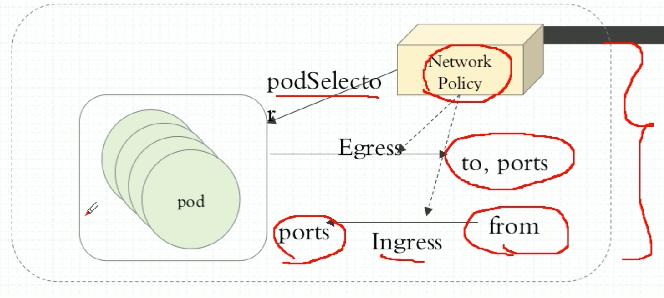
|
|
|
|
字段解释:
- egress <[]Object>
- ingress <[]Object>
- podSelector
- policyTypes <[]string>
策略类型:假如当前策略中既定义了egress,又定义了Ingress,哪个生效呢?它两其实不冲突,一个控制出站,一个控制入站。但也可以在某个时刻只让一个方向的规则生效。policyTypes就是干这个事情的。给哪个就代表哪个生效,如果都给了,代表都生效。
假如定义规则的时候只写了Igress,而policyTypes中既写了Egress,又写了Ingress。Egress没定义啊,表示Egress默认规则生效。如果Egress默认规则是拒绝的,那么所有的出站都是拒绝的,如果Egress默认规则是允许的,那么所有的出站都是允许的。
|
|
|
|
以上这种定义,表示Ingress规则生效,但是没有任何显式定义的规则,就意味着默认是拒绝所有的,而policyTypes里没有加Egress,意味着Egress默认是允许所有的。
在dev环境创建上面定义的networkpolicy:
此时dev名称空间里还没有Pod,创建Pod:
访问下这个Pod内的服务,发现不能访问:
现在修改dev名称空间的策略,允许所有入站。
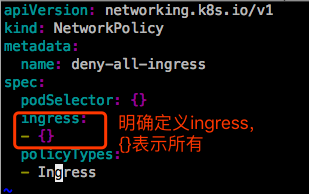
现在就可以访问了:
放心特定的入站流量:只允许访问dev名称空间的一组pod。
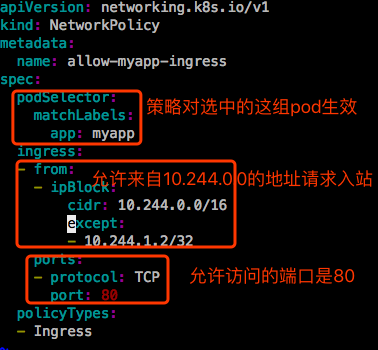
访问:
但是443还是能访问,把deny-all-ingress这个策略删除掉,这个策略里放开了所有的入站:
这下就访问不了443了。
在dev创建另一个Pod,看看这个规则是否对这个pod生效:
很显然,上面设置的策略只对podSelector选中的pod生效。
官方文档示例:
其中,ingree的规则如下:对于含有标签”role=db”的Pod的TCP的5978端口
- default名称空间下的含有标签 “role=frontend” 的Pod可以访问
- 含有标签 “project=myproject” 名称空间下的Pod可以访问
- IP地址在 172.17.0.0/16,除了172.17.1.0/24网络内的,可以访问
如果pod作为客户端的话,应该允许访问外面所有的服务,出站应该放行所有。入站控制哪些进来就行。
如果想苛刻一点,就是拒绝所有入站,拒绝所有出站,单独放行。但是拒绝所有出站,拒绝所有入站会有问题,会导致同一个名称空间中被同一个podSelector选中的Pod与Pod也没法通信了。所以设置完拒绝所有入站,拒绝所有出站后,还应该加上一条,本名称空间出,然后又到本名称空间的pod是被允许的。就是放行同一个名称空间的pod之间通信。这样内部通信就没问题。