
Kubernetes整体架构概述
master从本质上来讲主要是运行整个集群的控制平面组件的,比如三个最核心的组件:apiserver、Scheduler、Controller-manger。除此之外,master还依赖etcd这样的存储节点,最好还是个有冗余能力的存储集群。使用kubeadm部署时会把这个控制平面部署为了pod应用程序,但是是部署为静态Pod的。从本质上来讲,我们可以认为这几个pod就是简单的运行在master节点本地的守护进程,从这个角度来讲,master本身是不负责运行任何工作负载的。
所有的工作节点才是真正去运行工作负载的Pod的节点,终端用户以后在运行Pod时只需要提交给master就行了,甚至不用关心对应自己的Pod运行在哪个节点之上,因为工作节点被master组织成为一个庞大的虚拟资源池。虚拟资源池中,cpu、ram、存储卷等通通整合为统一的视角向客户端进行提供。但是对于集群管理员来讲,这个虚拟资源池不是所关注的根本,应该关心底层这些pod应该更加优化的部署在哪些节点上。当用户请求创建一个Pod资源对象时,应该运行在哪个节点上,是由控制平面当中的Scheduler来做决策的。Scheduler是可以自定义的。
当用户提交创建pod请求到apiserver后,apiserver检查权限都没有任何问题的话,接下来会把请求交由Scheduler,(Scheduler是一个守护进程,内部有很多调度算法,调度算法是可以换的,默认用的是default Scheduler,) 由Scheduler从众多节点当中选择一个匹配的节点来作为接下来运行此Pod的节点,注意它的选择结果并不是直接反应在节点之上的,它的选择结果会告诉apiserver,apiserver会将选择的结果会被记录在etcd中,然后apiserver会指挥着被选定节点上的kubelet,或者说是kubelet始终去watch着apiserver与当前节点相关连的事件变动,接下来kubelet去获取到apiserver中定义的配置清单,去创建Pod。清单中会定义镜像拉取策略,仓库地址等配置。这些都是kubelet要完成的任务。当然建议使用控制器去创建Pod。
因为Pod是有生命周期的,所以必要的时候在前端加一个service,以提供一个固定的访问端点。service并不是一个实实在在的组件,它是所有节点上相关iptables或ipvs规则,因此当用户通过kubectl或其他客户端创建一个service时,这个请求一样提供给apiserver,apiserver检查权限后,开始创建service。这个service的创建一样要存储在etcd中。在每个节点上还有个组件kube-proxy,kube-proxy会监控service资源相关的变动,然后把规则创建成节点上的iptables或ipvs规则。
kubelet和kube-proxy都需要去连接apiserver去获取某些资源定义,而apiserver可不是人人可以访问的,需要做认证、授权、准入控制。从这个角度来讲,kubelet和kube-proxy都是apiserver的客户端。而且他们之间实现数据传输时也要做数据序列化,序列化方案是protocolbuffers,Facebook还是google研发的非常底层的序列化方案。apiserver与kubectl这个客户端之间使用的序列化方案是json。
Scheduler调度过程
Scheduler要考虑哪个节点是最佳运行pod的节点,default scheduler在默认实现调度决策时是通过是三个步骤(三级)来完成的。
- 第一步,Predicate,预选。假如现在有一堆节点,先去排除不符合此Pod运行条件的节点。在k8s中,Pod中定义容器可以定义两个维度的资源限制。第一,叫资源需求,意思是每一个节点,只有满足Pod的最低资源需求才能运行此Pod。比如这个pod至少需要运行2g内存,1核cpu,这是一种资源下限。第二,资源限额。在Pod使用过程中,有可能会超出定义的需求资源,最多能到多少呢?可以做资源限额,表示最多能用多少资源。很显然,这么多节点中,不是每一个节点剩余的可用资源都能满足此Pod的需求,不能满足就排除掉。当然还有其他一些条件,比如说在定义Pod时,要求共享宿主机网络名称空间,并且Pod中容器要监听在80端口上,那么那些节点上80端口被占用的节点就不符合要求了。
- 第二步,Priority,优选。基于一系列的算法函数,把每一个节点的属性输入进去,然后去计算每一个节点的优先级,计算完后进行排序。然后得分最高的,就是选定的节点。
- 第三步,Select,选定。将pod绑定在优选后的节点上。
假如出现一种极端情况,最后最高得分者有好几个,分数是一样的,这个时候就没有倾向性了。所以选定这个步骤是不可少的,因为最高得分的不一定是一个。最高分不止一个,就从中随机选择一个界定啊。
特殊偏好:nodeName和nodeSelector。只对某一些类型的节点有倾向性。这些在预选中,就会缩小很多范围了。
特殊的调度方式
- 节点亲和调度: nodeAffinity
- Pod亲和调度和反亲和性:podAffinity podUnAffinity 有些时候我们期望某些个Pod运行在同一节点,或者是相邻的节点上,网络通信带宽可用性更大的节点。反亲和性:比如一个Pod运行了httpd,绑定在了物理节点的名称空间上,另外一个Pod要运行Nginx,也要绑定在一个物理节点上,如果这两个pod在一台主机上,同时监听80端口,就冲突了,这是反亲和性的例子。
- 污点taints和污点容忍Tolerations:这是反其道而行之的做法。一直在说Pod怎么选定哪些节点,但是也允许节点不让某些Pod来运行。可以给一些节点打上污点标识,说明这个节点是拥有不光彩、见不得人的一些事情存在。因此一个Pod是否能够运行在这些节点,就取决于这个Pod是否能容忍这些污点。我们在某些节点上打上一些污点标识,而后我们给Pod定义它的容忍污点能力,容忍哪些污点,它就能被调度到仅含有这些污点子集的节点上去。比如这个pod非常大度,能容忍10个污点,第一个节点由5个污点,正好这5个污点还是pod容忍度的子集,所以这个pod是可以运行在这个节点上的。如果这个节点后来不想让这个Pod运行了,我们可以在这个节点上多打一个污点,并且这个污点不在这个pod的容忍度内。
常见的预选策略
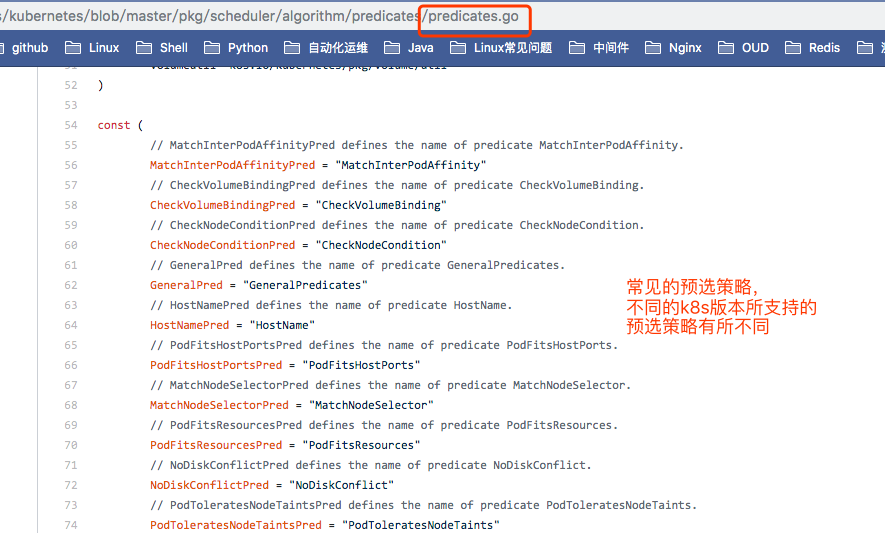
CheckNodeCondition: 检查节点本身是否正常,磁盘网络等是否可用。
GeneralPredicates:不是一个单独的预选策略,包含好几个预选策略。
- HostName: 检查Pod对象是否定义了pod.spec.hostname, 如果定义了,检查节点的hostname是否与pod定义的这个值相匹配。pod.spec.hostname这个属性并不是定义这个Pod运行在有相同hostname值的节点上。意思在对应的节点上,这个pod名称还没有被使用,要不然在一个节点上Pod是不允许同名的。因为某些Pod名称是固定的,不是随机生成的。
- PodFitsHostPorts: pods.spec.containers.ports.hostPort,port能适配节点的端口。如果Pod中容器上定义了pods.spec.containers.ports.hostPort属性,指定绑定在节点的哪个端口上,如果你的节点这个端口已经被占用了,显然这个节点不符合条件了。
- MatchNodeSelector: pods.spec.nodeSelector
- PodFitsResources: 检查Pod的资源需求是否能被节点所满足,运行此Pod的最低配置是否满足。
- NoDiskConflict: 检查Pod依赖的存储卷是否能满足需求; 但是这个不是默认启用的策略。
- PodToleratesNodeTaints: 检查Pod上的spec.tolerations可容忍的污点是否完全包含节点上的污点;
PodToleratesNodeNoExecuteTaints: 等后面讲污点和容忍度的时候在解释。检查Pod上的spec.tolerations可容忍的污点是否完全包含节点上定义的NoExecute类型的污点。污点有3重属性。就是本来pod能接纳这个节点的污点,在上面跑着,但是后来节点污点改了,改成Pod里面不包含的污点了,所以pod此时不能接纳这个节点了,默认是可以继续在节点运行的,但是NoExecute意味着不能容忍,会驱离Pod的。这个预选策略默认是不启用的。
CheckNodeLabelPresence: 检查节点上指定标签的存在性。取决于用户定义,标签是用户自己定义的。这个预选策略默认不是启用的。
CheckServiceAffinity: pod可能会属于一个或多个service,根据当前Pod对象所属的service已有的其他pod对象,其中有一部分已经调度到这个节点上了,有些节点并没有运行此service关联的Pod。将相同service的pod对象尽可能放置在同一个节点上。这个默认不是启用的。
MaxEBSVolumeCount:检查节点上已挂载的EBS存储卷的数量是否超出了最大设定值。EBS是亚马逊的弹性块存储。如果你的k8s使用EBS存储卷,一般来讲一个节点上最多只能挂载39个存储卷。有定义,默认就是39个。
- MaxGCEPDVolumeCount:google的GCE存储
MaxAzureDiskVolumeCount:亚马逊的存储AzureDisk –这3个都是启用的,这3个都是CNCF成员
CheckVolumeBinding: 检查节点上已绑定和未绑定的pvc是否满足Pod对象的存储卷需求
NoVolumeZoneConflict: Zone,机房逻辑范围划分
CheckNodeMemoryPressure:检查节点内存是否存在压力。如果一个节点上内存资源已经比较紧缺了,表示这节点不符合条件,肯定是倾向压力不大节点。
- CheckNodePIDPressure:检查节点PID数量压力多大,PID资源紧缺。
CheckNodeDiskPressure:磁盘IO是否过大
MatchInterPodAffinity:Pod和Pod之间也是有亲和性。检查节点是否满足Pod的亲和性或反亲和性。到底用哪个,取决于你定义的是亲和性还是反亲和性。
调度器默认启用了的预选策略,是要检查所有启用了的预选策略。满足所有启用了的预选策略,节点才是满足条件的。
常见的优选函数
LeastRequested: 最少请求的节点。计算比率的。
1(cpu((capacity-sum(requested))*10/capacity)+memory((capacity-sum(requested))*10/capacity))/2BalancedResourceAllocation: CPU和内存资源被占用率相近的胜出;
- NodePreferAvoidPods:
节点倾向不要运行pods,根据节点是否有注解存在。如果给定的节点没有以下这个注解信息,得分为10,而且权重为1万,权重非常高。
节点注解信息“scheduler.alpha.kubernetes.io/preferAvoidPods” - TaintToleration: 将Pod对象的spec.tolerations列表项与节点的taints列表项进行匹配度检查,匹配条目越多, 意味着节点污点越多,得分越低;
- SeletorSpreading: 标签选择器分散度。查找与当前Pod对象匹配的sevice、replication controller、ReplicaSet、StatefulSet等,看看与这些选择器匹配到的现存的Pod对象所在的节点有哪些个,已经运行此类pod对象越少的节点得分越高。spread:散开。
- InterPodAffinity: Pod亲和性。遍历Pod对象的亲和性条目,并将那些能够匹配到给定节点的条目的权重相加,结果值越大,得分越高。用pod自己去评估每个节点,能在多大程度上满足这个pod的亲和性,假如第一个节点它有两条能满足,第二个节点有三条能满足,显然第二个节点得分越高。
NodeAffinity: 节点亲和性。根据Pod中的nodeSelector对节点进行检查,能成功匹配的数量越多,得分越高。
MostRequested: LeastRequested相反。两者不能同时使用。
- NodeLabel: 节点标签。根据节点是否拥有特定标签来评估得分。只关注标签,不关注值,标签存在就得分。
- ImageLocality: 根据满足当前Pod对象需求的已有镜像的体积大小之和。比如一个Pod内有3个容器,节点上镜像都有的得分最高。事实上不是这么算的,根据镜像体积来算的。
最后三个默认没有启用。
预选是一票否决,只要有一个策略不满足,节点就不符合了。
优选函数是计算总得分的。每个函数都评估,然后将函数得分加起来。