
scheduler调度过程概述
scheduler在实现调度时,分为三步实现调度过程。首先是预选,从所有节点当中选择基本符合条件的节点;而后在众多符合条件的节点当中,在使用优选函数去计算各自的得分并且加以比较,并从最高得分的节点当中随机选择出一个作为运行Pod的节点。这就是控制平面当中scheduler所实现负责的主要工作。
同时如果在某些调度场景当中,我们期望通过自己的预设去影响它的一些调度方式,比如把Pod运行在一些特定的节点之上,可以通过自己的预设操作来影响scheduler的预选和优选的过程,从而使用调度操作能符合我们的期望。
此类的影响方式通常有3种,我们通常称为高级调度设置机制:
节点选择器: nodeSelector, nodeName
节点亲和调度: nodeAffinity
示例1:nodeSelector
|
|
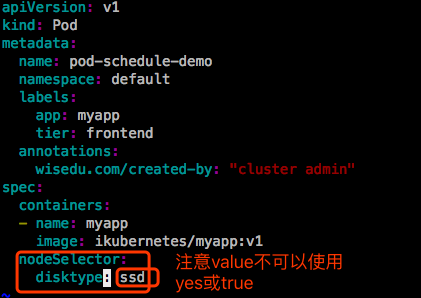
此前在集群中一个节点ubuntu31上打上过标签 disktype=ssd,所以这个Pod运行会运行在这个节点上。打标签和删除标签的方式如下:
当从node节点上删除这个 disktype=ssd 标签,只要删除前pod已经运行在这个节点上,那么删除这个标签,pod依然会运行着,不会因此而终止。
现在来修改下这个pod的nodeSelector的值,需要先删除这个pod,修改完重新apply一下这个清单文件:
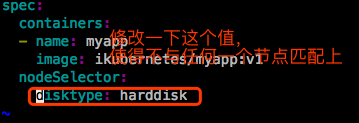
此时pod一直处于pending状态。这也就意味着nodeSelector是强约束,在预选阶段就不能满足了。
给集群中其中一个节点打上该标签,pod立马被调度到这台节点上运行了:
|
|
示例2:pods.spec.affinity中nodeAffinity
|
|
|
|
- preferredDuringSchedulingIgnoredDuringExecution <[]Object>
倾向,尽量满足的条件。不满足也行。尽量运行在满足这里定义的亲和条件的节点上。 - requiredDuringSchedulingIgnoredDuringExecution
|
|
- matchExpressions <[]Object>
A list of node selector requirements by node’s labels. 匹配表达式的 - matchFields <[]Object>
A list of node selector requirements by node’s fields. 匹配字段的
下面定义示例yaml文件:
清单中定义的是硬亲和性,目前还没有节点拥有标签zone,并且值在foo和bar内。
找一个集群中的节点打上一个标签 zone=bar:
删除标签和pod:
下面定义一个软亲和性的清单文件(即使定义的条件不满足,也会勉为其难地找一个节点运行pod):
删除这个pod:
示例3:pods.spec.affinity中的podAffinity和podAntiAffinity
一般是出于高效通信的需求,偶尔需要把一些pod对象组织在相近的位置,比如运行在同一节点,同一机架,同一区域,同一地区等等,这样子pod和pod通信效率更高。
主要目的是把pod运行在一起,或不运行在一起,其实通过节点亲和性就能达到目的。比如3个Pod,NMP,使用3个同样的节点标签,而后我们在节点上打标签的时候就确保它3个选择的标签的节点就在同一个位置,就在同一个机架上,也能达到这个目的。但是为何还要定义pod亲和性和反亲和性呢?是因为使用节点亲和性去限制pod,它不是一种较优的选择方式,需要精心布局节点是被打上什么标签的才能实现目的。这种方式使用起来可能难度较大。
较理想的方式是,允许调度器把第一个Pod随机选择一个位置,但是第二个Pod就要根据第一个pod所在的位置来进行调度。Pod的亲和性并不强制一定要在同一个节点,相近的就可以了。所以要定义什么叫同一位置,什么叫不同位置。
如何判定是哪些节点是相同位置,哪些节点是不同位置是需要定义的。比如现在有4个正常运行的主机,当第一个Pod运行在第一个节点上之后,如何判定第2、3、4节点是否可以运行与第一个Pod亲和的Pod?比如NMP是亲和的,N被放在了第一个节点,M是应该放在第一个节点上,还是其他节点都不能放?Pod的亲和性并不强制一定要在同一个节点,非要把NMP放在同一个节点,假如这个节点资源不够,这样也不是一个最佳选择。比如我们定义,把N、M、P分别运行在一个节点上,只要这3个节点在一个机柜内,那就认为这是满足亲和条件的。所以在定义Pod亲和性时必须有个判断前提,Pod和Pod要在同一位置和不要在同一位置的判断标准是什么。因此什么叫同一位置,什么叫不同位置就很关键了。当以节点名称来判定这几个节点是不是同一位置,很显然这4个节点都是不同的位置。节点名相同的就认为是同一位置,不同的就认为是不同位置。所以如果把N这个Pod运行在节点1上,M和P也是会被调度到节点1上的。
换个判定标准,比如判定是否是同一位置的标准是:节点标签rack(机架)相同的就是同一位置。比如rack=rack1,两个节点都有这个标签,并且值为rack1的,那么两个节点就是同一位置。另外两个节点的标签是rack=rack2。所以此时假如第一个Pod运行在第一个节点上,也就是rack=rack1的节点上,那么M和P可以运行在第一个和第二个节点上。
podAffinity
Pod亲和性也有硬亲和性和软亲和性。
|
|
- labelSelector
- namespaces <[]string>
namespaces specifies which namespaces the labelSelector applies to (matches against); null or empty list means “this pod’s namespace” 指明labelSelector匹配到一组pod到底是哪个名称空间的,不指意味着与要创建的新pod一个名称空间的 - topologyKey
-required-
位置拓扑的键,用来判定是不是同一个位置。用哪个键来判定是不是同一位置
接下来定义两个pod,第一个是基准,第二个跟第一个走。
每一个节点都有个标签叫 kubernetes.io/hostname。
|
|
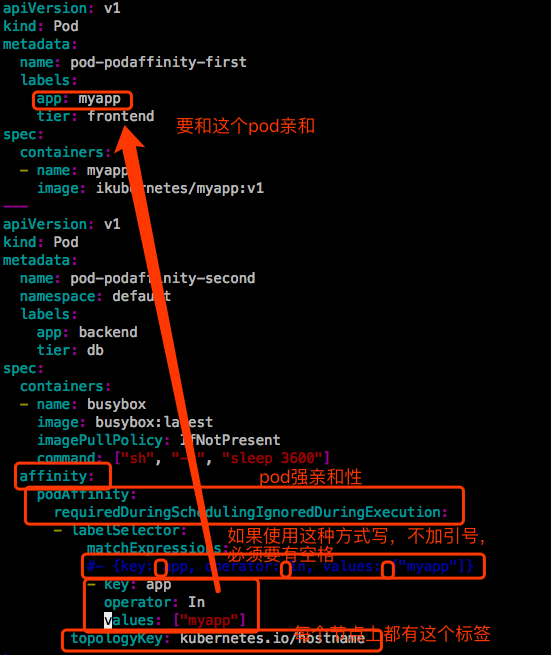
两个pod都运行在第二个节点上。
删除这两个pod:
podAntiAffinity
podAffinity和podAntiAffinity区别是:二者的标签的值不能是相同的。
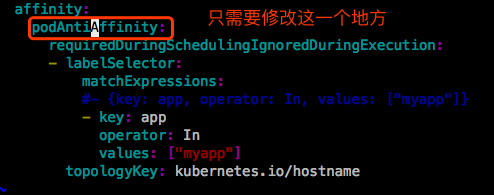
一定不在同一个节点上。
将集群中的三个node节点,都打上同一个标签 zone=foo,其中spark32为master节点:
修改 pod-podantiaffinity-demo.yaml 中topologyKey的值: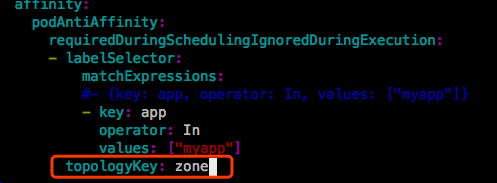
第一个Pod在运行,第二个Pod处于pending状态。
示例4:污点调度
污点就是定义在节点上的键值数据。键值数据有三类:标签、注解、污点。污点是运行在节点上的,不像标签和注解,所有资源都能用。
这就给了节点选择权,给节点打一些污点,pod不容忍就不能运行上来。我们需要在Pod上定义容忍度。容忍度tolerations是Pod对象上的第三种键值数据。
- effect
-required-
当Pod不能容忍这个污点时,要采取的行为是什么。taint的effect定义对Pod排斥效果: - NoSchedule:仅影响调度过程,对现存的Pod对象不产生影响;
- NoExecute:既影响调度过程,也影响现在的Pod对象;不容忍的Pod对象将被驱逐;
- PreferNoSchedule: 不能容忍,但是没地方运行也可以过来运行。最好不,表示也可以。
在Pod对象上定义容忍度的时候,还支持两种操作。等值比较和存在性判断。所谓等值比较,需要在key、value、effect上完全匹配。存在性判断表示二者的key和effect必须匹配,但是value可以使用空值,即判断存在不存在与否即可。一个节点可以配置多个污点,一个Pod也可以有多个容忍度。只不过二者匹配时要遵循如下的逻辑。
比如在Pod上定义了3个容忍度,在节点之上定义了2个污点,这个pod一定能运行在这个节点上吗?不一定,pod容忍了其中一个污点,另外一个没有容忍,这种情况是可能的。要逐一检查节点的污点,节点的每一个污点都必须被Pod容忍。如果某个污点被Pod的容忍度匹配到了,那么这个污点就过了,检查下一个。如果存在污点不被pod所容忍,就要看这个污点的条件了。如果这个污点的行为是PreferNoSchedule,那么事实上还是可以运行在这个节点上的。但是如果这个污点的行为是NoSchedule,就一定不能被调度到这个节点上了。
此前在运行pod时,没有一个pod会被调度到master节点上运行,是因为master上默认就有污点,我们定义的Pod都没有去定义容忍度去匹配master节点上的这个污点。master是用来运行集群控制平面组件的,可以看看这几个Pod,肯定定义了容忍度去匹配这个污点。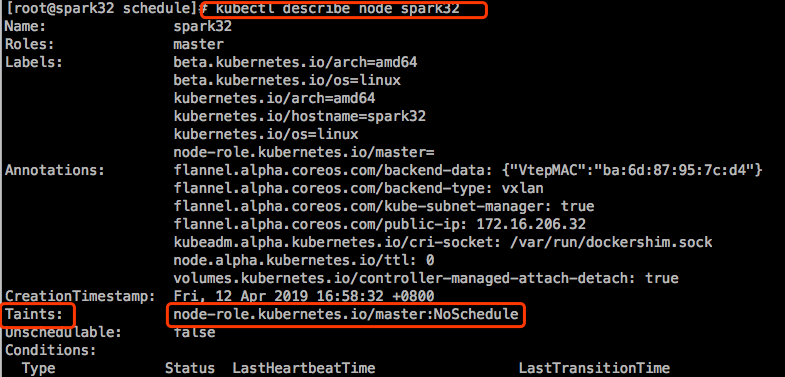
master节点上打的污点,value为空值,即判断表示存在不存在。
看下api-server这个pod中定义的容忍度:
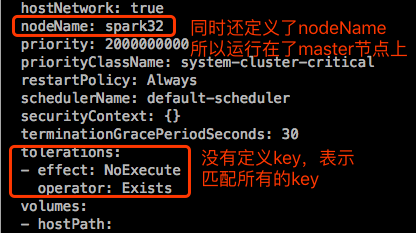
管理节点的污点:
现在集群中有3个node节点,给其中两个node节点打上污点如下:
定义一个Deployment,不定义其中Pod的污点容忍度:
|
|
这样这个Deployment中的Pod都运行在没打污点的那个节点上。
将没打污点的节点hadoop16也打上污点,并且effect为NoExecute:
运行在hadoop16上的pod被驱逐了。
下面看看如何在pod上定义tolerations。
- tolerationSeconds:被驱逐时可以等待多久被驱逐,默认是0,立即驱逐。
修改deploy-taint-demo.yaml,定义tolerations:
|
|
运行在了spark17和ubuntu31节点上。将spark17上污点的effect改为NoExecute:
如果想让pod调度到spark17和hadoop16上,必须使得effect值也一样。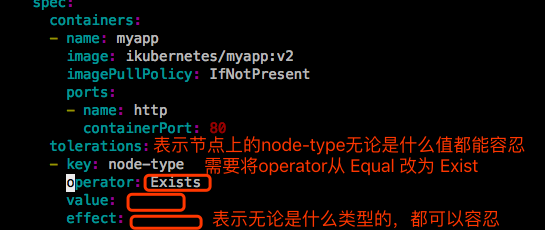
去掉三个节点上的污点: