
docker的4种常用的网络模型
- bridge
- joined:共享使用另外一个容器的网络名称空间
- open:使用宿主机网络名称空间。
- none
无论是哪一种方式,跨节点容器之间进行通信时,必须使用NAT机制来实现。出宿主机时做源地址转换,必须拿着物理机的地址出去。
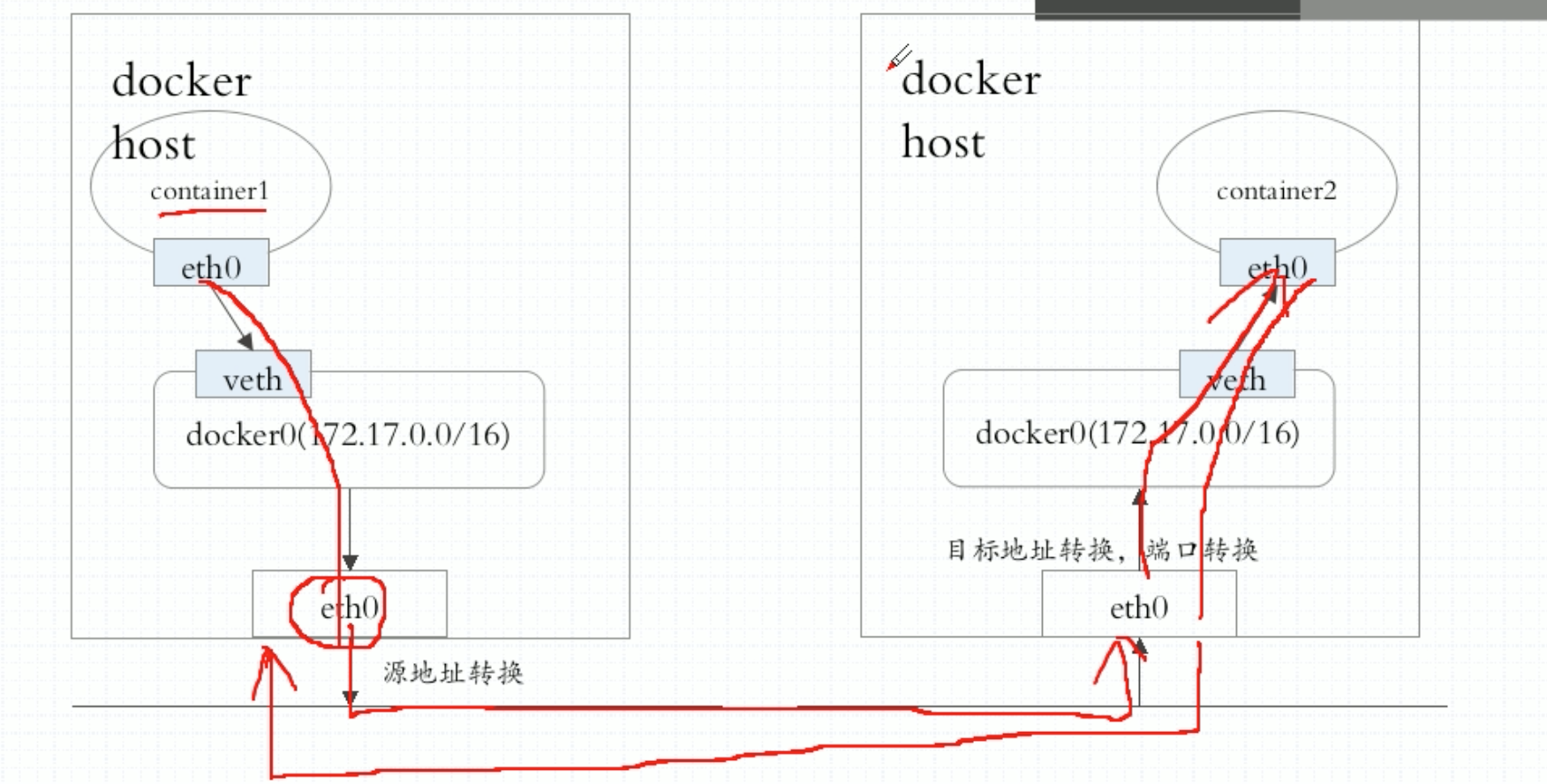
在上图中,左边节点上有个container1,container1用纯软件的方式生成一个网络接口,通常是veth格式的网络接口,一半在容器上,一半在宿主机上并关联到docker0桥上来了,很显然是个私网地址,需要在报文离开本机时做源地址转换SNAT。同样的,如果container2想被别人访问到,需要做DNAT把服务暴露出去。
所以如果是contaner1和container2通信,那就需要两级NAT转换了。所以网络通信性能很差,container1其实一直不知道自己访问的是谁,它本意访问的是container2,但是目标地址只能是节点2的eth0的地址。container2也不知道是谁访问的自己,一直收到的都是节点1的eth0地址。
所以这种通信方式实在是效率低,而且很难构建我们真正需要的通信网络模型。因此k8s作为一个编排工具来讲,本身就必须要让容器运行在多个节点之上,而且是以Pod的形式。各Pod之间是需要进行通信的。
Kubernetes网络通信
1.容器间通信: 同一个Pod内的多个容器间的通信, lo
2.Pod通信: Pod IP <–> Pod IP。k8s要求直达,不允许做任何地址转换,要使用自己的IP与对方的IP直接通信。意思是通信双方所见的地址就是通信双方的地址。
3.Pod与Service通信: PodIP <–> ClusterIP。他两不在同一个网段,但是通过本地的iptables或ipvs规则能实现通信。如何启用ipvs,之前讲的有点问题,系统上有个configMap,kube-proxy,这里面定义了kube-proxy到底使用哪种模式工作。但是注意ipvs取代不了iptables,因为ipvs只能拿来做负载均衡,做NAT转换这个功能就做不到。
4.Service与集群外部客户端的通信。
k8s的网络实现不是自己来实现的,要靠网络插件来实现。通过CNI标准实现的插件都可以在k8s上使用。
CNI: 有几十种现有的解决方案,常用的如下:
- flannel
- calico
- canel:flannel和calico拼凑起来的
- kube-router
…
无论是哪一种插件,他们去试图解决以上4种通信时,所用的解决方案无非是以下几种:
- 虚拟网桥:bridge,纯软件的方式实现虚拟网卡,接入到网桥上去。每一对虚拟网卡,一半留在Pod之上,一半留在宿主机之上,并接入到网桥中去使用。甚至接入到物理接口上,使用物理桥接的方式。
- 多路复用: MacVLAN。基于MAC的方式去创建VLAN,为每个虚拟接口配置一个独有的MAC地址,使得一个物理网卡可以承载多个容器使用,这样他们就直接使用物理网卡并基于物理网卡中的MacVLAN机制进行跨节点之间进行通信。
- 硬件交换: SR-IOV,单根IO虚拟化。网卡支持硬件交换。一个网卡支持直接在物理级虚拟出多个接口来,叫单根IO虚拟化。现在市面上很多网卡都支持单根IO虚拟化。它是创建虚拟设备的一种很高性能的方式。一块网卡能虚拟出硬件级多块网卡来,然后我们可以让每个容器使用一个。
这几种方案里硬件交换的性能最好。而MacVLAN是一个网卡基于VLAN方式构建多个网络,也算可行。而虚拟网桥不得不靠叠加的方式来确保Pod通信是从Pod IP直接到Pod IP。很多情况下,用户期望创建L3或L2的逻辑网络子网,就需要借助于叠加的网络协议来实现。所以多种解决方案中,第一种虚拟网桥我们确实可以实现更为强大的控制能力,但是对网络传输来讲有额外的性能开销,毕竟是要使用隧道网络,或者称为叠加网络,需要多封装IP首部或者多封装MAC首部,具体看是几层隧道。不过一般来讲,我们使用叠加网络时,控制平面还没有很好的标准化,用起来彼此之间可能有很多不兼容。另外,我们如果要使用VXLAN这种技术,叫扩展的VLAN技术,可能会引入更多的开销,但是这种方式给了用户更大的腾挪空间。
使用CNI时要用到的配置文件:
kubelet 或者 /etc/cni/net.d/ 下找配置文件
任何其他网络插件部署上来后,一般都是把配置文件放到 /etc/cni/net.d/ 目录下,从而可以被kubelet所加载,从而能够被kubelet作为必要时创建一个Pod,这个Pod应该有网络和网卡,kubelet调 /etc/cni/net.d/ 指定配置文件中定义的网络插件,由网络插件代为实现地址分配、接口创建、网络创建等。
目前flannel仍然占据着主要份额,毕竟简单。但是flannel有缺陷,在k8s之上网络插件不但要实现网络地址分配、管理等功能,还应该实现网络策略,可以控制Pod与Pod之间能不能通信。k8s之上存在名称空间,但是这个名称空间并不隔离Pod的访问,虽然隔离了用户权限。flannel是不支持网络策略的。
而calico的部署确实比flannel复杂很多,但是calico不仅支持地址分配、管理等功能,还支持网络策略。因此虽然calico复杂,但是仍然受到很多用户接受。另外,calico在实现地址转发的方式中,可以基于BGP的方式来实现二层网络转发和三层网络路由。性能上比flannel好,但是flannel也是三层网络方式,默认网络是叠加。
使用时可以同时使用flannel和calico,用flannel来实现网络功能,用calico来实现网络策略。
flannel介绍
flannel默认使用的VXLAN的方式来做后端网络传输机制的。如果基于宿主机桥接通信,那么Pod就应该可以借助虚拟网卡实现报文交换了,但现在我们要组成一个叠加网络。那就意味着两台主机之上应该有个专门用于叠加报文封装的隧道,这个通常是被叫做flannel.0,flannel.1这样的接口,如下:
这个接口专门用来封装隧道协议报文的,物理网卡的mtu是1500,而flannel.1网卡的mtu为 1450,要留出来一部分,因为要做叠加时有额外的开销,把额外的开销留出来了。而额外的空间不是不被占用的,而是留给隧道使用的。
另外ifconfig里还看到cni0接口。cni0是被当前主机作为隧道协议上在本地通信时使用的接口。但是要创建完Pod后,这个cni0接口才会出现。
在两个主机的flannel接口之间要构建一个额外添加了报文传输通道,使用两个节点上的Pod之间通信借助这个传输通道来实现,就好像两个Pod之间直接通信了。这个通信使用的功能就是所谓的flannel.1接口,每次通信报文之外在封装一个二层或三层或四层的报文首部,这取决于工作模式。默认情况下用的是VXLAN技术,外层的隧道使用的VxLAN协议,扩展的虚拟局域网。扩展的虚拟局域网在实现报文通信时,可以理解为类似四层隧道这样的协议。正常传输一个以太网帧的时候,应该是在二层链路层直接进行传输以太网帧报文。那这个报文真正传输报文怎么传的?当一个帧发过来的时候,它要经由这个隧道接口在额外封装一个首部,第一VxLAN首部,而VxLAN首部之外,还有个UDP首部,借助于UDP来传输。UDP之外是IP首部,IP之外又有个以太网首部,所以这几层都是额外的开销。所以说基于VxLAN,性能可能会比较低,但好处在于可以独立管理一个网络,而且彼此之间跟物理网络是不相干扰的。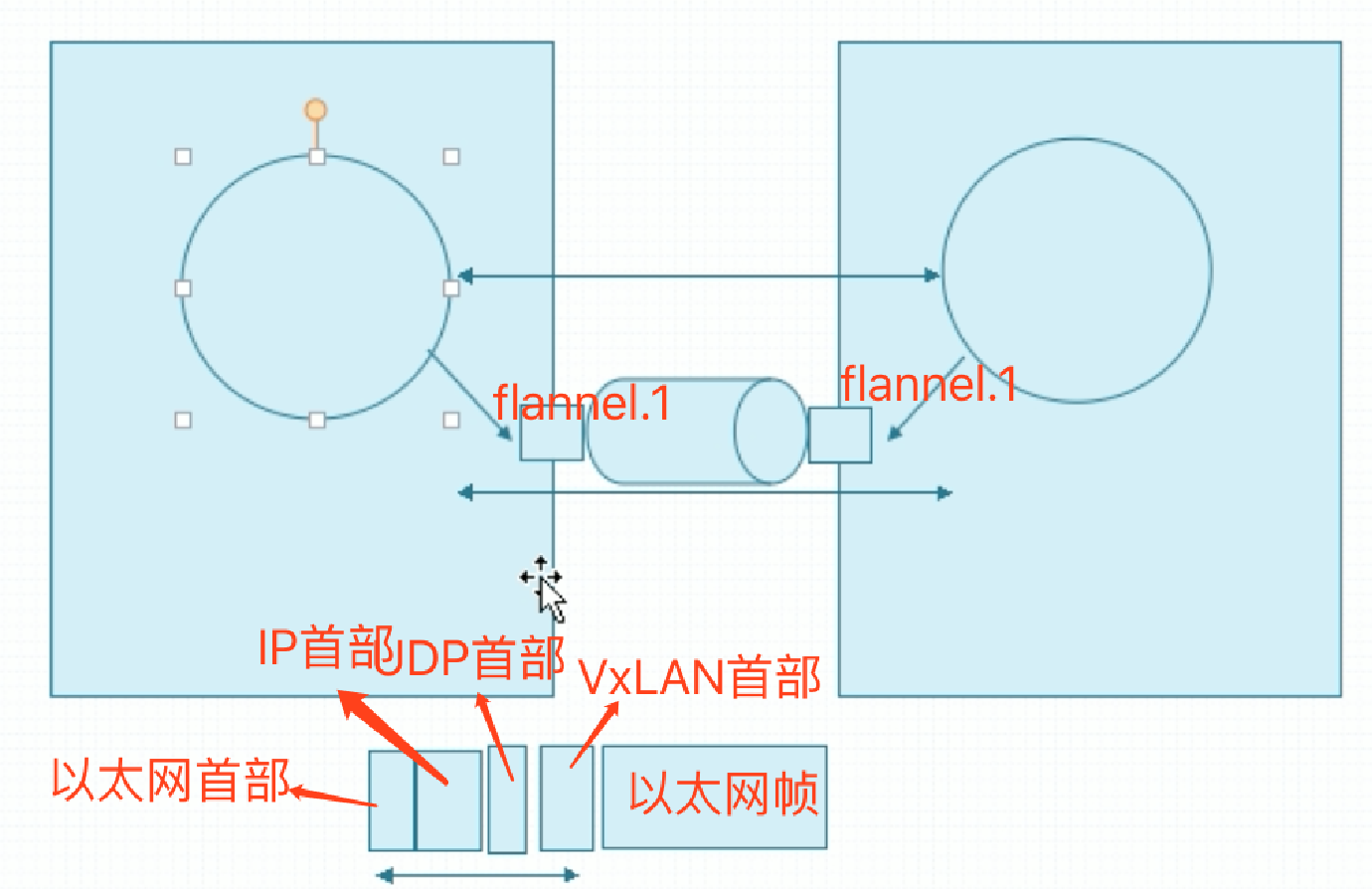
以上只是flannel网络后端传输的第一种方式,所以flannel支持多种后端承载方式,就是报文是怎么发过去的:
- VxLAN
- (1) vxlan
- (2) Directrouting:如果源Pod所在的节点与目标Pod所在的节点在同一个二层网络中,就是在同一个网咯中,那么大家直接使用host-gw通信,但是假如源Pod所在的节点与目标Pod所在的节点不在同一个网络中,就是中间有路由的,那么就自动降级为VxLAN叠加隧道进行通信。
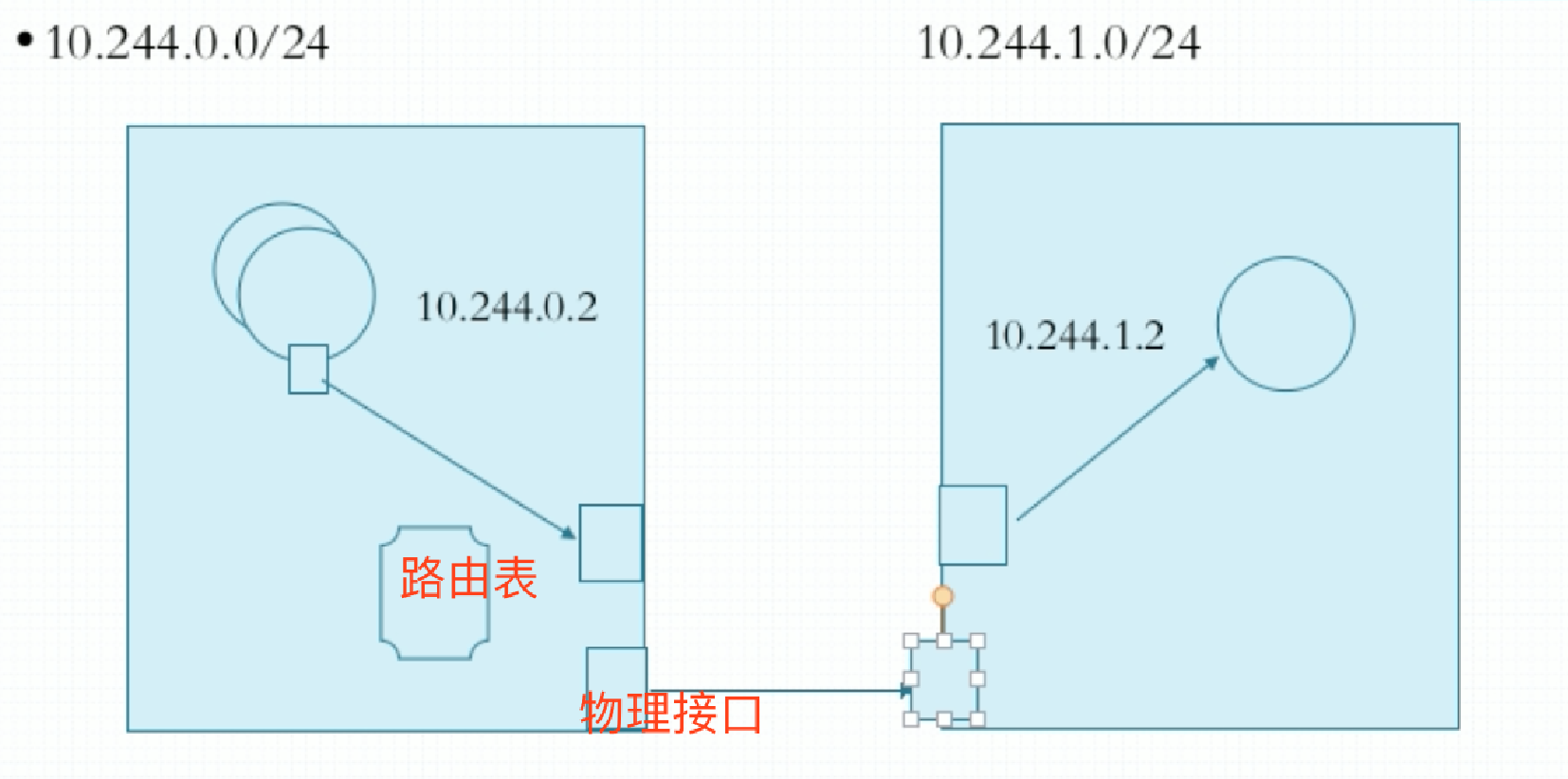
- host-gw: Host Gateway。两个节点上的Pod各自拥有一个网段,我们把主机自己所在的网络接口当做是网关来使用。在物理机上创建一个虚拟接口,每一个Pod也有个虚拟接口,Pod的虚拟接口在传输报文时,不是通过隧道承载传送过去的,当它需要传输报文时,发现目标主机不是本地的,它把报文传给物理机上的虚拟接口,把它当做网关来用,这个网关看到报文后要查路由表,这个路由表中记录了到达哪个网络要发给谁。比如发给10.244.1.0网络的要发给对端主机的物理网卡,然后经过物理网卡就发出去了。对端的物理网卡收到后一看是本物理机的另外一块虚拟网卡接口,所以报文传给那个虚拟网卡接口,然后在传到到Pod的虚拟接口。这里面没有使用叠加,报文通过路由就到达对端主机了,把主机所在的节点所在的地址额外加一个接口当网关,但是这样子就使得路由表很大。这种方式比vxlan性能要好很多,几乎没有什么多余的开销,除了本地路由之外。但是默认没有使用这种方式,因为有个缺陷,要求k8s节点必须在同一个二层网络中,如果两台主机之间要有路由,就没办法定义清楚了,不知道发哪去了。
- UDP: 就用纯粹的UDP报文进行传输,这种比VxLAN方式性能更差。因为它是用普通的UDP报文转发的,不是VxLAN专用的UDP报文转发的。
flannel刚刚被发明出来的时候,Linux内核不支持VxLAN,Linux内核级没有VxLAN模块,而那个时候host-gw又有很高的门槛,所以早期flannel用的是UDP,最差的方式。因此在网上产生了一种偏见,认为flannel性能很差,现在使用host-gw方式的性能比calico性能都要好。
部署flannel
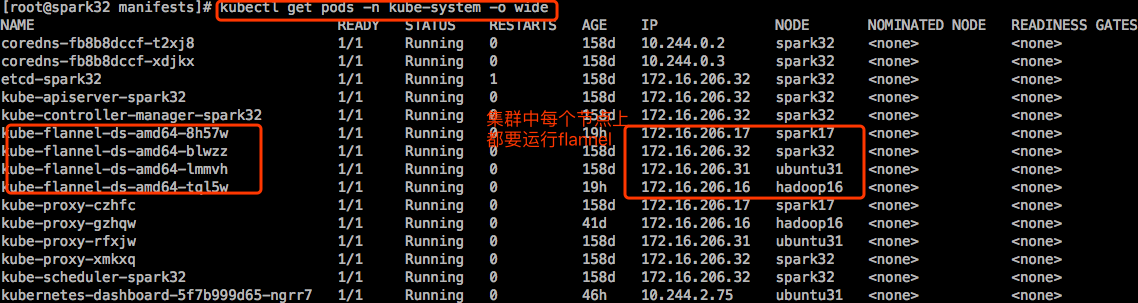
flannel本身和k8s没有关系,它事先等存在,没有网络插件,k8s没法跑起来。他是被kubelet所调用的。凡是有kubelet的节点上都应该部署flannel。kubelet存在是为了运行Pod,而Pod就需要网络,而网络是kubelet调用flannel或者其他网络插件来实现网络功能。
flannel可以部署为系统的守护进程,也可以部署为k8s之上的Pod。当部署为k8s之上的Pod时,一定是个DaemonSet,在每一个节点上运行一个Pod副本,而且这个Pod副本是直接共享宿主机的网络名称空间的,这样Pod才能设置宿主机网络名称空间的。不然的话,就不能代为在Pod中运行又能改宿主机的网络接口了,比如创建个cni,每一个Pod启动时还能创建另外一对虚拟网卡,有一个在宿主机上,还能添加到桥上去,这些功能如果flannel不能共享宿主机网络名称空间的话,显然是做不到的。
当我们使用kubeadm部署k8s集群的时候,部署flannel是作为Pod托管在k8s之上的。

配置flannel时使用的是configMap,用来配置这几个Pod是怎么来运行的。有个configMap叫 kube-flannel-cfg。
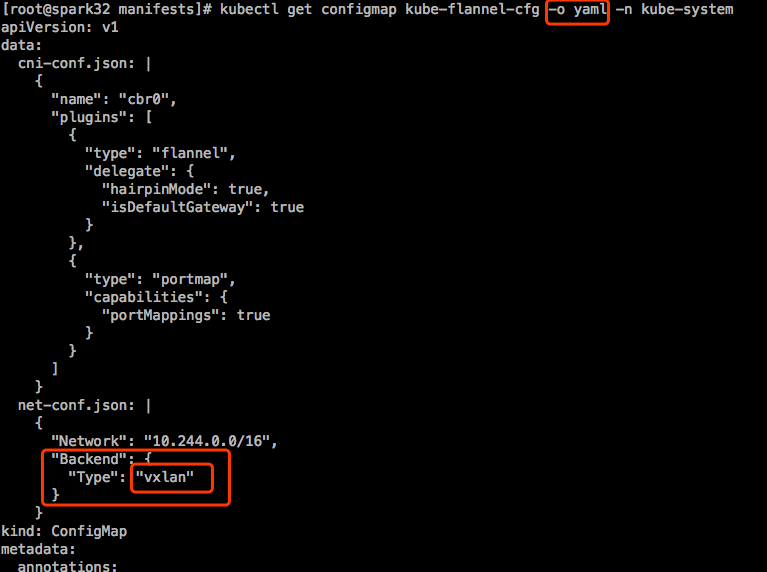
也可以配置为Directrouting方式。
flannel的配置参数
Network: flannel使用的CIDR格式的网络地址,用于为Pod配置网络功能。这个是个全局的网络,通常是8位或16位掩码的。然后这个全局网络会划分成子网,每个节点使用一个子网。比如:
123456789101110.244.0.0/16 ->master节点: 10.244.0.0/24node01节点: 10.244.1.0/24...node255节点: 10.244.255.0/24意味着整个集群最多256个节点。10.0.0.0/8 ->10.0.0.0/24...10.255.255.0/24意味着整个集群最多2^16=65356个节点。 太大了,一般可以使用12或16位掩码,自己配置。注意要留出service使用的网络,比如service使用10.96.0.0/12,pod可以使用10.10.0.0/12。SubnetLen: 把Network切分子网供各节点使用时, 使用多长的掩码进行切分, 默认为24位;
- SubnetMin:10.244.10.0/24 子网中地址段中最小是多少给节点使用。比如如果是10.244.0.0/16网络,那么最小是10.244.0.0/24,最大是 10.244.255.0/24
- SubnetMax: 10.244.100.0/24
- Backend: vxlan, host-gw, udp。各Pod之间怎么通信。
示例1:抓包看flannel的默认vxlan报文通信
|
|
进入ubuntu31主机上运行的pod:
打开另一个终端,进入spark7主机上运行的pod,然后ping ubuntu31上的pod的IP:
在打开一个终端,连接ubuntu31和spark17,分别在上面抓icmp包:
|
|
两个主机上都抓不到icmp报文。因为报文到物理接口上时已经被封装成UDP报文了,实际上是通过cni0或者flannel.1接口来接入的。所以报文到达这些接口的时候,应该还没有被隧道转发,至少是在它自己网卡的前后端还没有被隧道转发。
|
|
Pod的网络接口都桥接到cni0,因此在cni上抓包应该都没被隧道封装。

虽然这里看到的是10.244.1.55直接到10.244.2.92,但是实际上报文在被送达到flannel.1接口的时候,报文先从cni0进来,从flannel.1出去,然后借助于物理网卡发出去。
抓取到达物理网卡上的报文: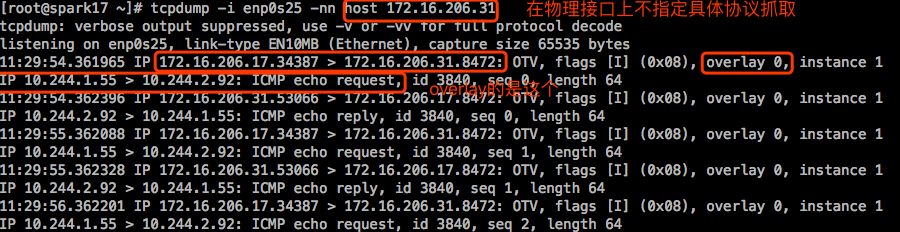
不支持抓取vxlan:
示例2:配置使用Directrouting的通信方式
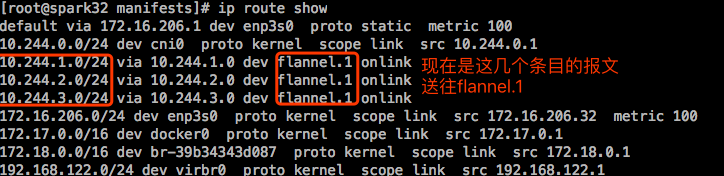
先看下当前主机的路由表:
|
|
需要把配置的内容应用到集群中,这实际上是configMap中的数据,所以需要把它定义成独立的configMap,或者合并到flannel现在用的configMap中。
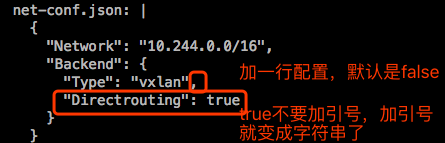
看下现在的路由表:
这两条路由条目应该是送往物理接口才对,改完没有生效。
把pod删除,重新创建,然后在查看路由表:
还是不行。
此前安装flannel时是kubectl appy -f,而我们这里修改是kubectl edit,不建议这么做,可能不会直接生效。现在去下载flannel的yaml文件,直接改这个文件,在apply一下。
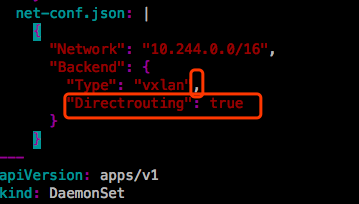
还是没有生效。
只能删除flannel,然后重新创建了:
【注意】:正常在生产环境不能这么搞,flannel一删除,所有Pod都不能运行了,因为没有网络。系统刚装完就要去调整flannel。
等flannel的pod都终止完成,在重新创建:
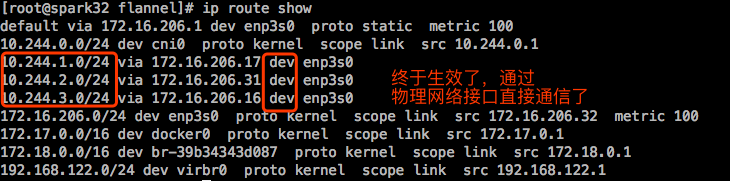
在测试下跨节点通信:
在物理节点上抓ICMP包,这时能抓到了:
这和物理桥接很相像了。但是如果两个节点是跨网段的,会直接降级为overlay。
如果想要使用host-gw模式,修改如下: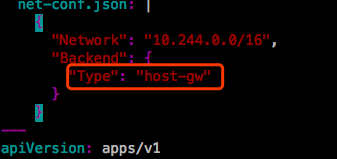
host-gw要求k8s节点必须在同一个网络,不允许跨网段。这种方式有个缺陷,那么多的Pod,成千上万个都在同一个二层网络中,不隔网段,将来一旦有广播报文,大家都会受到影响。